聊一聊高并发高可用那些事 - Kafka篇
目录

为什么需要消息队列
1.异步 :一个下单流程,你需要扣积分,扣优惠卷,发短信等,有些耗时又不需要立即处理的事,可以丢到队列里异步处理。
2.削峰 :按平常的流量,服务器刚好可以正常负载。偶尔推出一个优惠活动时,请求量极速上升。由于服务器 Redis,MySQL 承受能力不一样,如果请求全部接收,服务器负载不了会导致宕机。加机器嘛,需要去调整配置,活动结束后用不到了,即麻烦又浪费。这时可以将请求放到队列里,按照服务器的能力去消费。
3.解耦 :一个订单流程,需要扣积分,优惠券,发短信等调用多个接口,出现问题时不好排查。像发短信有很多地方需要用到, 如果哪天修改了短信接口参数,用到的地方都得修改。这时可以将要发送的内容放到队列里,起一个服务去消费, 统一发送短信。
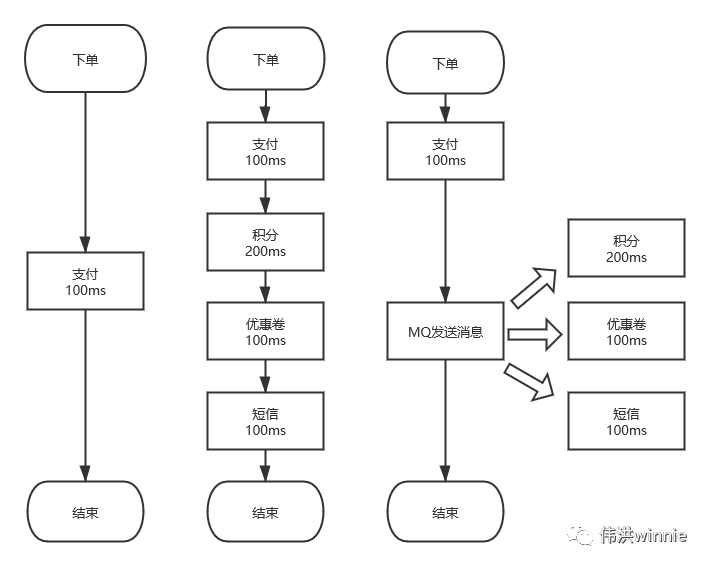
高吞吐、高可用 MQ 对比分析
看了几个招聘网站,提到较多的消息队列有:RabbitMQ、RocketMQ、Kafka 以及 Redis 的消息队列和发布订阅模式。
Redis 队列是用 List 数据结构模拟的,指定一端 Push,另一端 Pop,一条消息只能被一个程序所消费。如果要一对多消费的,可以用 Redis 的发布订阅模式。Redis 发布订阅是实时消费的,服务端不会保存生产的消息,也不会记录客户端消费到哪一条。在消费的时候如果客户端宕机了,消息就会丢失。这时就需要用到高级的消息队列,如 RocketMQ、Kafka 等。
ZeroMQ 只有点对点模式和 Redis 发布订阅模式差不多,如果不是对性能要求极高,我会用其它队列代替,毕竟关解决开发环境所需的依赖库就够折腾的。
RabbitMQ 多语言支持比较完善,特性的支持也比较齐全,但是吞吐量相对小些,而且基于 Erlang 语言开发,不利于二次开发和维护。
RocketMQ 和 Kafka 性能差不多,基于 Topic 的订阅模式。RocketMQ 支持分布式事务,但在集群下主从不能自动切换,导致了一些小问题。RocketMQ 使用的集群是 Master-Slave ,在 Master 没有宕机时,Slave 作为灾备,空闲着机器。而 Kafka 采用的是 Leader-Slave 无状态集群,每台服务器既是 Master 也是 Slave。

Kafka 相关概念
在高可用环境中,Kafka 需要部署多台,避免 Kafka 宕机后,服务无法访问。Kafka集群中每一台 Kafka 机器就是一个 Broker。Kafka 主题名称和 Leader 的选举等操作需要依赖 ZooKeeper。
同样地,为了避免 ZooKeeper 宕机导致服务无法访问,ZooKeeper 也需要部署多台。生产者的数据是写入到 Kafka 的 Leader 节点,Follower 节点的 Kafka 从 Leader 中拉取数据同步。在写数据时,需要指定一个 Topic,也就是消息的类型。
一个主题下可以有多个分区,数据存储在分区下。一个主题下也可以有多个副本,每一个副本都是这个主题的完整数据备份。Producer 生产消息,Consumer 消费消息。在没给 Consumer 指定 Consumer Group 时会创建一个临时消费组。Producer 生产的消息只能被同一个 Consumer Group 中的一个 Consumer 消费。
- Broker:Kafka 集群中的每一个 Kafka 实例
- Zookeeper:选举 Leader 节点和存储相关数据
- Leader:生产者与消费者只跟 Leader Kafka 交互
- Follower:Follower 从 Leader 中同步数据
- Topic:主题,相当于发布的消息所属类别
- Producer:消息的生产者
- Consumer:消息的消费者
- Partition:分区
- Replica:副本
- Consumer Group:消费组
分区、副本、消费组
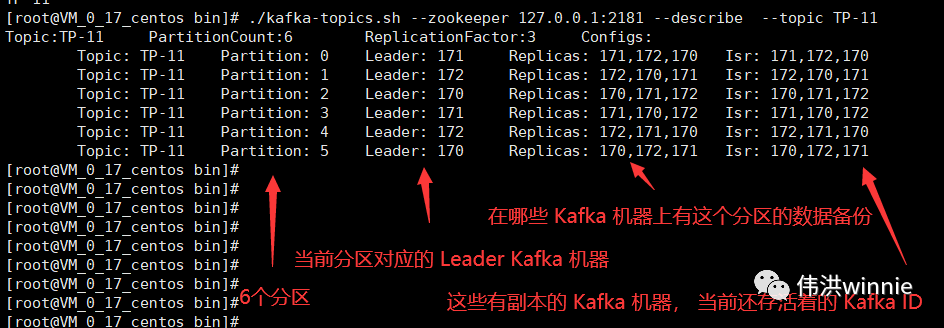
- 分区
主题的数据会按分区数分散存到分区下,把这些分区数据加起来才是一个主题的完整的数据。分区数最好是副本数的整数倍,这样每个副本分配到的分区数比较均匀。同一个分区写入是有顺序的,如果要保证全局有序,可以只设置一个分区。
如果分区数小于消费者数,前面的消费者会配到一个分区,后面超过分区数的消费者将无分区可消费,除非前面的消费者宕机了。如果分区数大于消费者数,每个消费者至少分配到一个分区的数据,一些分配到两个分区。这时如果有新的消费者加入,会把有两个分区的调一个分配到新的消费者。
分区数可以设置成 6、12 等数值。比如 6,当消费者只有一个时,这 6 个分区都归这个消费者,后面再加入一个消费者时,每个消费者都负责 3 个分区,后面又加入一个消费者时,每个消费者就负责 2 个分区。每个消费者分配到的分区数是一样的,可以均匀地消费。
- 副本
主题的副本数即数据备份的个数,如果副本数为 1 , 即使 Kafka 机器有多个,当该副本所在的机器宕机后,对应的数据将访问失败。
集群模式下创建主题时,如果分区数和副本数都大于 1,主题会将分区 Leader 较均匀的分配在有副本的 Kafka 上。这样客户端在消费这个主题时,可以从多台机器上的 Kafka 消息数据,实现分布式消费。
副本数不是越多越好,从节点需要从主节点拉取数据同步,一般设置成和 Kafka 机器数一样即可。如果只需要用到高可用的话,可以采用 N+1 策略,副本数设置为 2,专门弄一台 Kafka 来备份数据。然后主题分布存储在 "N" 台 Kafka 上,"+1" 台 Kafka 保存着完整的主题数据,作为备用服务。
Replicas 表示在哪些 Kafka 机器上有主题的副本,Isr 表示当前有副本的 Kafka 机器上还存活着的 Kafka 机器。主题分区中所涉及的 Leader Kafka 宕机时,会将宕机 Kafka 涉及的分区分配到其它可用的 Kafka 节点上。如下:
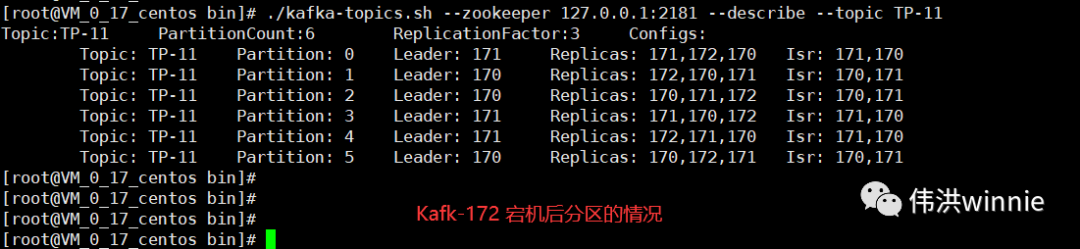
- 消费组
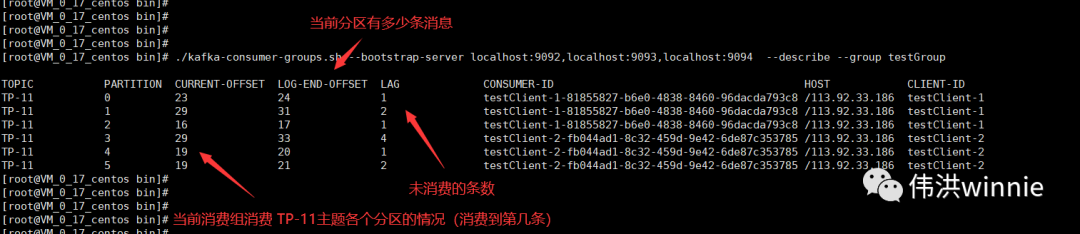
每一个消费组记录者各个主题分区的消费偏移量,在消费的时候,如果没有指定消费组,会默认创建一个临时消费组。生产者生产的消息只能被同一消费组下某个消费者消费。如果想要一条消息可以被多个消费者消费,可以加入不同的消费组。
偏移量最大值,消息存储策略
- 偏移量的最大值
long 类型最大值是(2^63)-1 (为什么要减一呢?第一位是符号位,正的有262,负的有262,其中+0 和 -0 是相等的 , 只不过有的语言把0算到负里面,有的语言把0算到正里面)。 偏移量是一个 long 类型,除去负数,包含0,其最大值为 2^62。
- 消息存储策略
Kafka 配置项提供两种策略, 一种是基于时间:log.retention.hours=168,另一种是基于大小:log.retention.bytes=1073741824 。符合条件的数据会被标记为待删除,Kafka会在恰当的时候才真正删除。
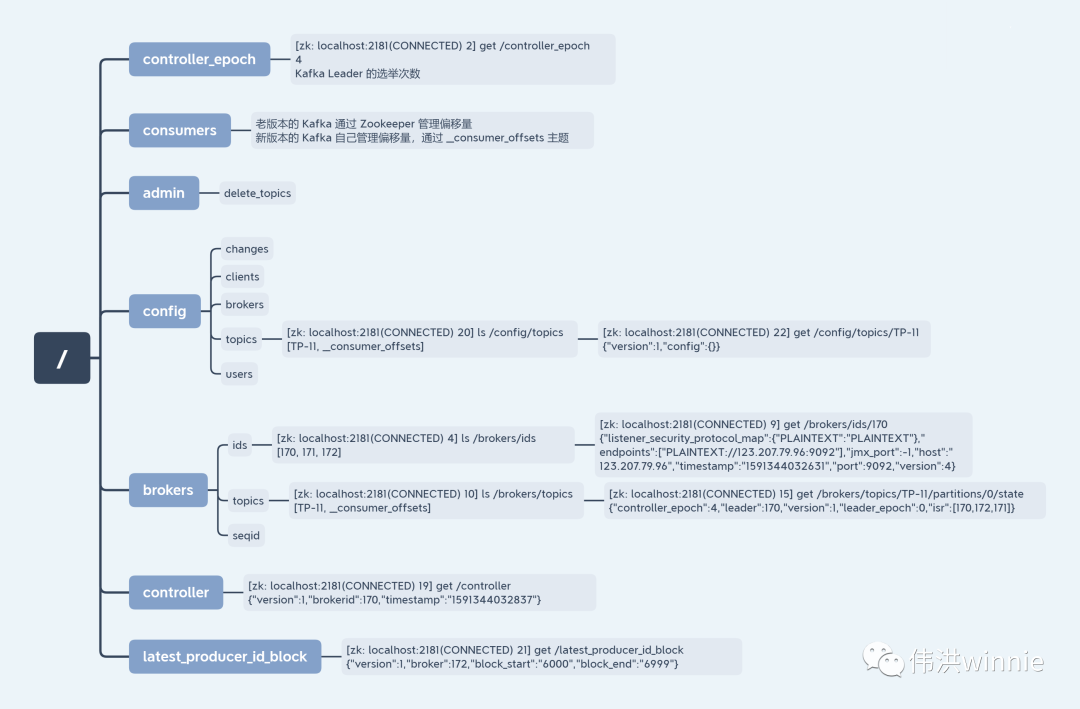
Zookeeper 上存的 Kafka 相关数据
如何确保消息只被消费一次
前面已经讲到,同一主题里的分区数据,只能被相同消费组里其中一个消费者消费。当有多个消费者同时消费同一主题时,将这些消费者都加入相同的消费组,这时生产者的消息只能被其中一个消费者消费。
重复消费和数据丢失问题
- 生产者
生产者发送消息成功后,不等 Kafka 同步完成的确认,继续发送下一条消息。在发的过程中如果 Leader Kafka 宕机了,但生产者并不知情,发出去的信息 Kafka 就收不到,导致数据丢失。解决方案是将 Request.Required.Acks 设置为 -1,表示生产者等所有副本都确认收到后才发送下一条消息。
Request.Required.Acks=0 表示发送消息即完成发送,不等待确认(可靠性低,延迟小,最容易丢失消息)
Request.Required.Acks=1 表示当 Leader 提交同步完成后才发送下一条消息
- 消费者
消费者有两种情况,一种是消费的时候自动提交偏移量导致数据丢失:拿到消息的同时偏移量加一,如果业务处理失败,下一次消费的时候偏移量已经加一了,上一个偏移量的数据丢失了。
另一种是手动提交偏移量导致重复消费:等业务处理成功后再手动提交偏移量,有可能出现业务处理成功,偏移量提交失败,那下一次消费又是同一条消息。
怎么解决呢?这是一个 or 的问题,偏移量要么自动提交要么手动提交,对应的问题是要么数据丢失要么重复消费。如果消息要求实时性高,丢个一两条没关系的话可以选择自动提交偏移量。如果消息一条都不能丢的话可以选择手动提交偏移量,然后将业务设计成幂等,不管这条消息消费多少次最终和消费一次的结果一样。
Linux Kafka 操作命令
- 查看 Kafka 中 Topic

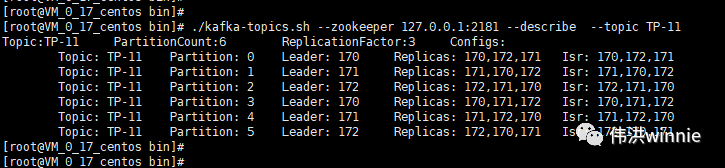
- 查看 Kafka 详情
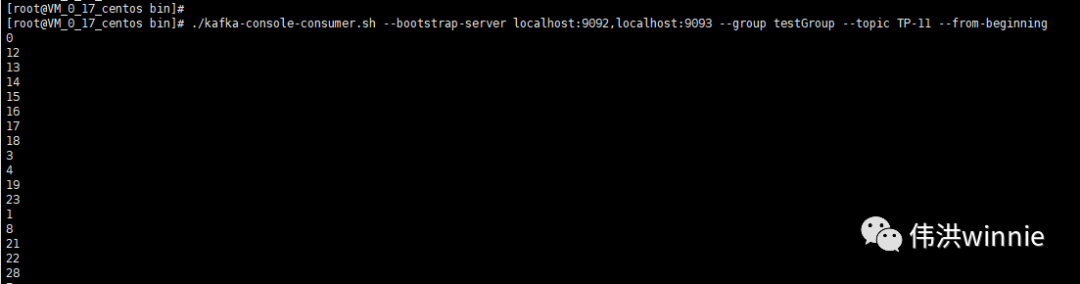
- 消费 Topic
- 查看所有消费组

- 查看消费组的消费情况

Windows 可视化工具 Kafka Tool
- 配置 Hosts 文件
123.207.79.96 ZooKeeper-Kafka-01
- 配置 Kafka Tool 连接信息
- 查看 Kafka 主题数据
生产者和消费者使用代码
- 具体操作参考 github.com/wong-winnie/library
订阅号:伟洪winnie
聊一聊高并发高可用那些事 - Kafka篇的更多相关文章
- 高并发&高可用系统的常见应对策略 秒杀等-(阿里)
对于一个需要处理高并发的系统而言,可以从多个层面去解决这个问题. 1.数据库系统:数据库系统可以采取集群策略以保证某台数据库服务器的宕机不会影响整个系统,并且通过负载均衡策略来降低每一台数据库服务器的 ...
- Java 18套JAVA企业级大型项目实战分布式架构高并发高可用微服务电商项目实战架构
Java 开发环境:idea https://www.jianshu.com/p/7a824fea1ce7 从无到有构建大型电商微服务架构三个阶段SpringBoot+SpringCloud+Solr ...
- java处理高并发高负载类网站的优化方法
java处理高并发高负载类网站中数据库的设计方法(java教程,java处理大量数据,java高负载数据) 一:高并发高负载类网站关注点之数据库 没错,首先是数据库,这是大多数应用所面临的首个SPOF ...
- [转]java处理高并发高负载类网站的优化方法
本文转自:http://www.cnblogs.com/pengyongjun/p/3406210.html java处理高并发高负载类网站中数据库的设计方法(java教程,java处理大量数据,ja ...
- 高并发高可、O2O、微服务架构用学习网站
高并发高可.O2O.微服务架构用学习网站 https://www.itkc8.com 非常感谢http://www.cnblogs.com/skyblog/p/5044486.html 关于架构,笔者 ...
- PHP高并发高负载系统架构
PHP高并发高负载系统架构 1.为什么要进行高并发和高负载的研究 1.1.产品发展的需要 1.2.公司发展的需要 1.3.当前形式决定的 2.高并发和高负载的约束条件 2.1.硬件 2.2.部署 2. ...
- Nginx+Redis+Ehcache大型高并发高可用三层架构总结
在生产环境中,对于高并发架构,我们知道缓存 是最重要的环节,对于大量的高并发.可以采用三层缓存架构来实现,也就是Nginx+Redis+Ehcache 对于中间件Nginx常来做流量分发,同事ngin ...
- 高并发&高可用系统的常见应对策略
解耦神器:MQ MQ是分布式架构中的解耦神器,应用非常普遍.有些分布式事务也是利用MQ来做的.由于其高吞吐量,在一些业务比较复杂的情况,可以先做基本的数据验证,然后将数据放入MQ,由消费者异步去处理后 ...
- 构建高并发&高可用&安全的IT系统-高并发部分
什么是高并发? 狭义来讲就是你的网站/软件同一时间能承受的用户数量有多少 相关指标有 并发数:对网站/软件同时发起的请求数,一般也可代表实际的用户 每秒响应时间:常指一次请求到系统正确响的时间(以秒为 ...
随机推荐
- Linux之cat的使用介绍
cat选项分析 ...
- js中的栈,堆。
一.栈和堆 栈(stack):栈会自动分配内存空间,会自动释放,存放基本类型,简单的数据段,占据固定大小的空间. 基本类型:String,Number,Boolean,Null,Undefined 堆 ...
- 使用naxsi
naxsi简介 naxsi 是一个nginx 防病毒,防跨站,sql 注入的一个模块.nginx的一个waf ,应用防火墙.非常好配置. naxsi 安装 naxsi 在debina/ubuntu 上 ...
- How to delete the eclipse plugin.
click Help-->installation Details 2. choose the plugin that you want to delete.Then click uninst ...
- 第七篇:wed版语音机器人
wed版语音机器人: GitHub项目地址:https://github.com/Yang915/WebToy 特别说明:该项目在本机测试,通过浏览器调用系统麦克风(https请求),实际环境在Fir ...
- python3.x 基础五:模块
1.定义 模块:本质是.py结尾的python文件,从逻辑上组织python代码,可以是变量,函数,类,逻辑,目的是实现一个功能,test.py 对应模块名:test 包:从逻辑上组织模块的,本质就是 ...
- 关于hadoop3.x MR报错:找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster
用的apache Hadoop3.X,今天运行MR报错: 找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster 关键需要配置两个配置:ma ...
- CICD:Jenkins入门和使用
最近,我们使用的开发服务器被回收了,换了一台新的服务器,CI/CD平台需要重新搭建. 我的运维能力一直薄弱,所以借此机会学习了一番如何使用Jenkins进行持续集成开发和部署,实践并踩了一些坑,在此记 ...
- Understanding REST and RESTful APIs
Understanding REST and RESTful APIs If you've spent any amount of time with modern web development, ...
- ExtJS定时和JS定时
ExtJS定时 //定时刷新待办事宜状态 var task={ run:function(){ //执行的方法或方法体 }, interval:5*60*1000 //5分钟 } //定时启动 Ext ...