Dubbo 路由机制的实现

Dubbo 路由机制是在服务间的调用时,通过将服务提供者按照设定的路由规则来决定调用哪一个具体的服务。
路由服务结构
Dubbo 实现路由都是通过实现 RouterFactory 接口。当前版本 dubbo-2.7.5 实现该接口类如下:
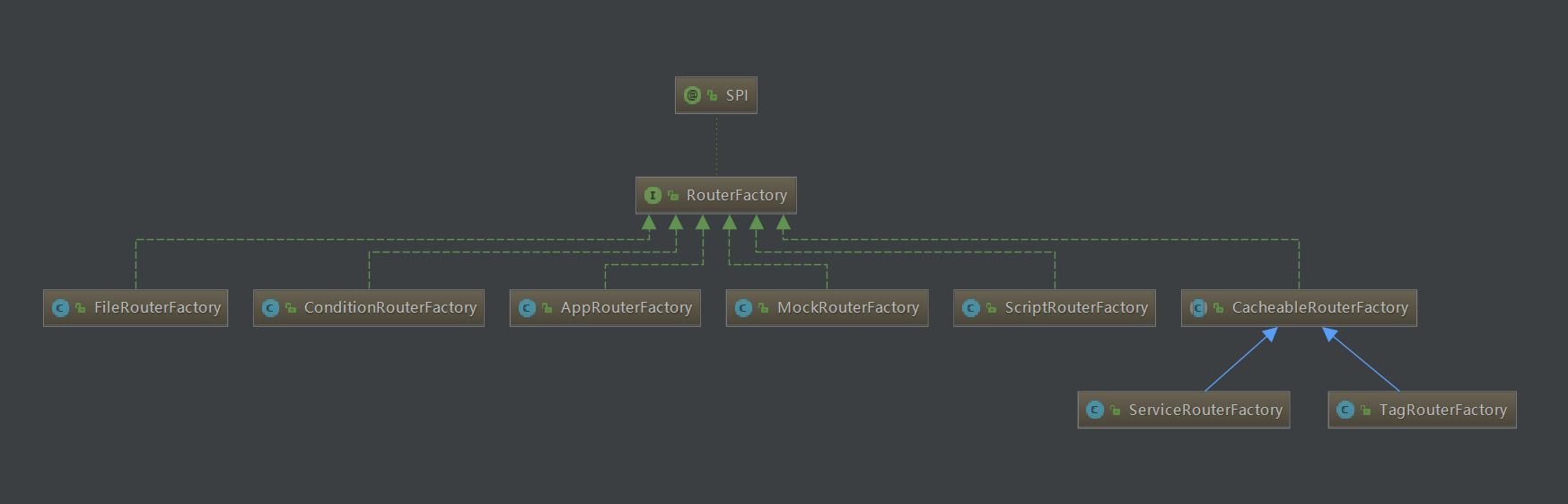
路由实现工厂类是在 router 包下

由于 RouterFactory 是 SPI 接口,同时在获取路由 RouterFactory#getRouter 方法上有 @Adaptive("protocol") 注解,所以在获取路由的时候会动态调用需要的工厂类。
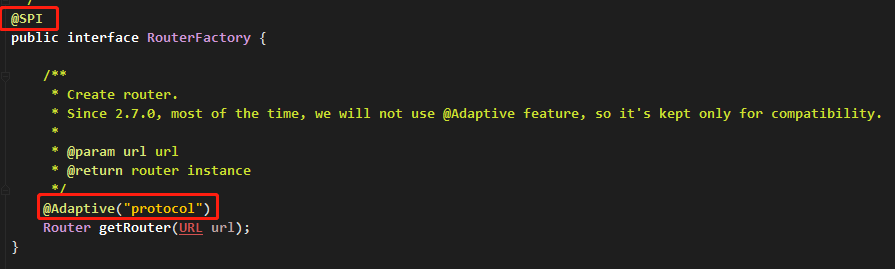
可以看到 getRouter 方法返回的是一个 Router 接口,该接口信息如下
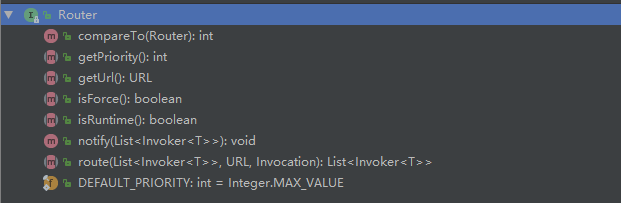
其中 Router#route 是服务路由的入口,对于不同类型的路由工厂,有特定的 Router 实现类。
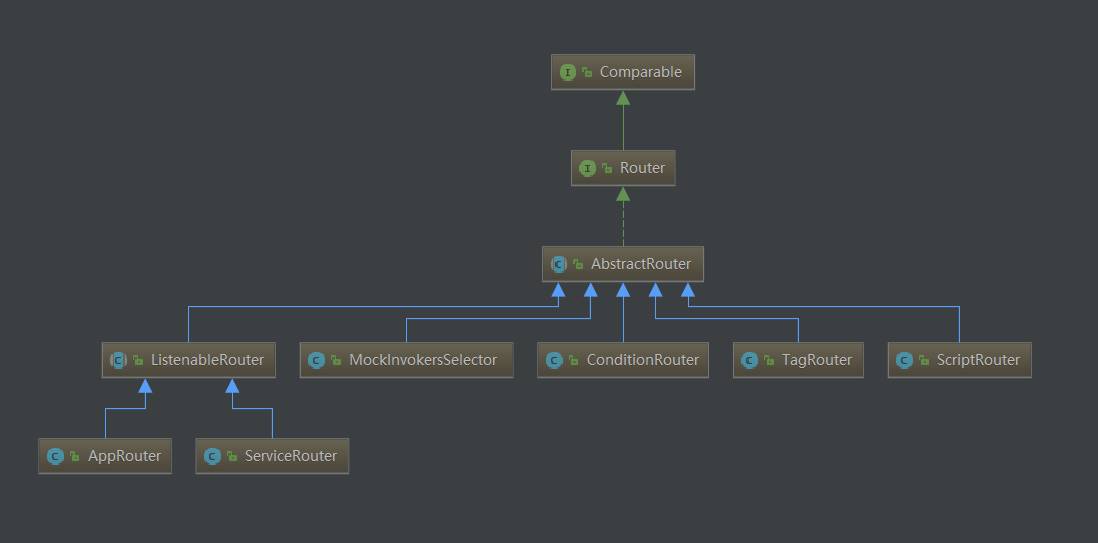
以上就是通过解析 URL,获取到具体的 Router,通过调用 Router#router 过滤出符合当前路由规则的 invokers。
服务路由实现
上面展示了路由实现类,这几个实现类型中,ConditionRouter 条件路由是最为常用的类型,由于文章篇幅有限,本文就不对全部的路由类型逐一分析,只对条件路由进行具体分析,只要弄懂这一个类型,其它类型的解析就能容易掌握。
条件路由参数规则
在分析条件路由前,先了解条件路由的参数配置,官方文档如下:

条件路由规则内容如下:

条件路由实现分析
分析路由实现,主要分析工厂类的 xxxRouterFactory#getRouter 和 xxxRouter#route 方法。
ConditionRouterFactory#getRouter
ConditionRouterFactory 中通过创建 ConditionRouter 对象来初始化解析相关参数配置。

在 ConditionRouter 构造函数中,从 URL 里获取 rule 的字符串格式的规则,解析规则在 ConditionRouter#init 初始化方法中。
public void init(String rule) {try {if (rule == null || rule.trim().length() == 0) {throw new IllegalArgumentException("Illegal route rule!");}// 去掉 consumer. 和 provider. 的标识rule = rule.replace("consumer.", "").replace("provider.", "");// 获取 消费者匹配条件 和 提供者地址匹配条件 的分隔符int i = rule.indexOf("=>");// 消费者匹配条件String whenRule = i < 0 ? null : rule.substring(0, i).trim();// 提供者地址匹配条件String thenRule = i < 0 ? rule.trim() : rule.substring(i + 2).trim();// 解析消费者路由规则Map<String, MatchPair> when = StringUtils.isBlank(whenRule) || "true".equals(whenRule) ? new HashMap<String, MatchPair>() : parseRule(whenRule);// 解析提供者路由规则Map<String, MatchPair> then = StringUtils.isBlank(thenRule) || "false".equals(thenRule) ? null : parseRule(thenRule);// NOTE: It should be determined on the business level whether the `When condition` can be empty or not.this.whenCondition = when;this.thenCondition = then;} catch (ParseException e) {throw new IllegalStateException(e.getMessage(), e);}}
以路由规则字符串中的=>为分隔符,将消费者匹配条件和提供者匹配条件分割,解析两个路由规则后,赋值给当前对象的变量。
调用 parseRule 方法来解析消费者和服务者路由规则。
// 正则验证路由规则protected static final Pattern ROUTE_PATTERN = Pattern.compile("([&!=,]*)\\s*([^&!=,\\s]+)");private static Map<String, MatchPair> parseRule(String rule)throws ParseException {/*** 条件变量和条件变量值的映射关系* 比如 host => 127.0.0.1 则保存着 host 和 127.0.0.1 的映射关系*/Map<String, MatchPair> condition = new HashMap<String, MatchPair>();if (StringUtils.isBlank(rule)) {return condition;}// Key-Value pair, stores both match and mismatch conditionsMatchPair pair = null;// Multiple valuesSet<String> values = null;final Matcher matcher = ROUTE_PATTERN.matcher(rule);while (matcher.find()) {// 获取正则前部分匹配(第一个括号)的内容String separator = matcher.group(1);// 获取正则后部分匹配(第二个括号)的内容String content = matcher.group(2);// 如果获取前部分为空,则表示规则开始位置,则当前 content 必为条件变量if (StringUtils.isEmpty(separator)) {pair = new MatchPair();condition.put(content, pair);}// 如果分隔符是 &,则 content 为条件变量else if ("&".equals(separator)) {// 当前 content 是条件变量,用来做映射集合的 key 的,如果没有则添加一个元素if (condition.get(content) == null) {pair = new MatchPair();condition.put(content, pair);} else {pair = condition.get(content);}}// 如果当前分割符是 = ,则当前 content 为条件变量值else if ("=".equals(separator)) {if (pair == null) {throw new ParseException("Illegal route rule \""+ rule + "\", The error char '" + separator+ "' at index " + matcher.start() + " before \""+ content + "\".", matcher.start());}// 由于 pair 还没有被重新初始化,所以还是上一个条件变量的对象,所以可以将当前条件变量值在引用对象上赋值values = pair.matches;values.add(content);}// 如果当前分割符是 = ,则当前 content 也是条件变量值else if ("!=".equals(separator)) {if (pair == null) {throw new ParseException("Illegal route rule \""+ rule + "\", The error char '" + separator+ "' at index " + matcher.start() + " before \""+ content + "\".", matcher.start());}// 与 = 时同理values = pair.mismatches;values.add(content);}// 如果当前分割符为 ',',则当前 content 也为条件变量值else if (",".equals(separator)) { // Should be separated by ','if (values == null || values.isEmpty()) {throw new ParseException("Illegal route rule \""+ rule + "\", The error char '" + separator+ "' at index " + matcher.start() + " before \""+ content + "\".", matcher.start());}// 直接向条件变量值集合中添加数据values.add(content);} else {throw new ParseException("Illegal route rule \"" + rule+ "\", The error char '" + separator + "' at index "+ matcher.start() + " before \"" + content + "\".", matcher.start());}}return condition;}
上面就是解析条件路由规则的过程,条件变量的值都保存在 MatchPair 中的 matches、mismatches 属性中,=和,的条件变量值放在可以匹配的 matches 中,!=的条件变量值放在不可匹配路由规则的 mismatches 中。赋值过程中,代码还是比较优雅。

实际上 matches、mismatches 就是保存的是条件变量值。
ConditionRouter#route
Router#route的作用就是匹配出符合路由规则的 Invoker 集合。
// 在初始化中进行被复制的变量// 消费者条件匹配规则protected Map<String, MatchPair> whenCondition;// 提供者条件匹配规则protected Map<String, MatchPair> thenCondition;public <T> List<Invoker<T>> route(List<Invoker<T>> invokers, URL url, Invocation invocation)throws RpcException {if (!enabled) {return invokers;}// 验证 invokers 是否为空if (CollectionUtils.isEmpty(invokers)) {return invokers;}try {// 校验消费者是否有规则匹配,如果没有则返回传入的 Invokerif (!matchWhen(url, invocation)) {return invokers;}List<Invoker<T>> result = new ArrayList<Invoker<T>>();if (thenCondition == null) {logger.warn("The current consumer in the service blacklist. consumer: " + NetUtils.getLocalHost() + ", service: " + url.getServiceKey());return result;}// 遍历传入的 invokers,匹配提供者是否有规则匹配for (Invoker<T> invoker : invokers) {if (matchThen(invoker.getUrl(), url)) {result.add(invoker);}}// 如果 result 不为空,或当前对象 force=true 则返回 result 的 Invoker 列表if (!result.isEmpty()) {return result;} else if (force) {logger.warn("The route result is empty and force execute. consumer: " + NetUtils.getLocalHost() + ", service: " + url.getServiceKey() + ", router: " + url.getParameterAndDecoded(RULE_KEY));return result;}} catch (Throwable t) {logger.error("Failed to execute condition router rule: " + getUrl() + ", invokers: " + invokers + ", cause: " + t.getMessage(), t);}return invokers;}
上面代码可以看到,只要消费者没有匹配的规则或提供者没有匹配的规则及 force=false 时,不会返回传入的参数的 Invoker。
匹配消费者路由规则和提供者路由规则方法是 matchWhen 和 matchThen

这两个匹配方法都是调用同一个方法 matchCondition 实现的。将消费者或提供者 URL 转为 Map,然后与 whenCondition 或 thenCondition 进行匹配。
匹配过程中,如果 key (即 sampleValue 值)存在对应的值,则通过 MatchPair#isMatch 方法再进行匹配。
private boolean isMatch(String value, URL param) {// 存在可匹配的规则,不存在不可匹配的规则if (!matches.isEmpty() && mismatches.isEmpty()) {// 不可匹配的规则列表为空时,只要可匹配的规则匹配上,直接返回 truefor (String match : matches) {if (UrlUtils.isMatchGlobPattern(match, value, param)) {return true;}}return false;}// 存在不可匹配的规则,不存在可匹配的规则if (!mismatches.isEmpty() && matches.isEmpty()) {// 不可匹配的规则列表中存在,则返回falsefor (String mismatch : mismatches) {if (UrlUtils.isMatchGlobPattern(mismatch, value, param)) {return false;}}return true;}// 存在可匹配的规则,也存在不可匹配的规则if (!matches.isEmpty() && !mismatches.isEmpty()) {// 都不为空时,不可匹配的规则列表中存在,则返回 falsefor (String mismatch : mismatches) {if (UrlUtils.isMatchGlobPattern(mismatch, value, param)) {return false;}}for (String match : matches) {if (UrlUtils.isMatchGlobPattern(match, value, param)) {return true;}}return false;}// 最后剩下的是 可匹配规则和不可匹配规则都为空时return false;}
匹配过程再调用 UrlUtils#isMatchGlobPattern 实现
public static boolean isMatchGlobPattern(String pattern, String value, URL param) {// 如果以 $ 开头,则获取 URL 中对应的值if (param != null && pattern.startsWith("$")) {pattern = param.getRawParameter(pattern.substring(1));}//return isMatchGlobPattern(pattern, value);}public static boolean isMatchGlobPattern(String pattern, String value) {if ("*".equals(pattern)) {return true;}if (StringUtils.isEmpty(pattern) && StringUtils.isEmpty(value)) {return true;}if (StringUtils.isEmpty(pattern) || StringUtils.isEmpty(value)) {return false;}// 获取通配符位置int i = pattern.lastIndexOf('*');// 如果value中没有 "*" 通配符,则整个字符串值匹配if (i == -1) {return value.equals(pattern);}// 如果 "*" 在最后面,则匹配字符串 "*" 之前的字符串即可else if (i == pattern.length() - 1) {return value.startsWith(pattern.substring(0, i));}// 如果 "*" 在最前面,则匹配字符串 "*" 之后的字符串即可else if (i == 0) {return value.endsWith(pattern.substring(i + 1));}// 如果 "*" 不在字符串两端,则同时匹配字符串 "*" 左右两边的字符串else {String prefix = pattern.substring(0, i);String suffix = pattern.substring(i + 1);return value.startsWith(prefix) && value.endsWith(suffix);}}
就这样完成全部的条件路由规则匹配,虽然看似代码较为繁杂,但是理清规则、思路,一步一步还是较好解析,前提是要熟悉相关参数的用法及形式,不然代码较难理解。
最后
单纯从逻辑上,如果能够掌握条件路由的实现,去研究其它方式的路由实现,相信不会有太大问题。只是例如像脚本路由的实现,你得先会使用脚本执行引擎为前提,不然就不理解它的代码。最后,在 dubbo-admin 上可以设置路由,大家可以尝试各种使用规则,通过实操才能更好掌握和理解路由机制的实现。
个人博客: https://ytao.top
关注公众号 【ytao】,更多原创好文

Dubbo 路由机制的实现的更多相关文章
- Dubbo超时机制导致的雪崩连接
Bug影响:Dubbo服务提供者出现无法获取Dubbo服务处理线程异常,后端DB爆出拿不到数据库连接池,导致前端响应时间异常飙高,系统处理能力下降,核心基础服务无法提供正常服务. Bug发现过程: ...
- C#进阶系列——WebApi 路由机制剖析:你准备好了吗?
前言:从MVC到WebApi,路由机制一直是伴随着这些技术的一个重要组成部分. 它可以很简单:如果你仅仅只需要会用一些简单的路由,如/Home/Index,那么你只需要配置一个默认路由就能简单搞定: ...
- Linux mips64r2 PCI中断路由机制分析
Linux mips64r2 PCI中断路由机制分析 本文主要分析mips64r2 PCI设备中断路由原理和irq号分配实现方法,并尝试回答如下问题: PCI设备驱动中断注册(request_irq) ...
- 走进AngularJs(八) ng的路由机制
在谈路由机制前有必要先提一下现在比较流行的单页面应用,就是所谓的single page APP.为了实现无刷新的视图切换,我们通常会用ajax请求从后台取数据,然后套上HTML模板渲染在页面上,然而a ...
- MVC5之路由机制
---恢复内容开始--- MVC是一种模式,是基于asp.net上的一种设计.路由机制不属于MVC,路由机制属于asp.net.因此,mvc的路由机制就是基于asp.net路由机制上的一种“自定制”. ...
- MVC路由机制
按照传统,在很多Web框架中(如经典的ASP.JSP.PHP.ASP.NET等之类的框架),URL代表的是磁盘上的物理文件.例如,当看到请求http://example.com/albums/li ...
- typecho路由机制详解
本文介绍的是typecho的路由机制,引自 不烦恼路由机制是typecho的核心,有很多功能都是基于路由功能设计的,理解并熟悉TE的路由机制将非常有助于插件的开发. 完整的路由表如下: array ( ...
- asp.net MVC 路由机制
1:ASP.NET的路由机制主要有两种用途: -->1:匹配请求的Url,将这些请求映射到控制器 -->2:选择一个匹配的路由,构造出一个Url 2:ASP.NET路由机制与URL重写的区 ...
- asp.net MVC 路由机制 Route
1:ASP.NET的路由机制主要有两种用途: -->1:匹配请求的Url,将这些请求映射到控制器 -->2:选择一个匹配的路由,构造出一个Url 2:ASP.NET路由机制与URL重写的区 ...
随机推荐
- 从零开始学习R语言(二)——数据结构之“因素(Factor)”
本文首发于知乎专栏:https://zhuanlan.zhihu.com/p/60101041 也同步更新于我的个人博客:https://www.cnblogs.com/nickwu/p/125370 ...
- Spring优雅整合Redis缓存
“小明,多系统的session共享,怎么处理?”“Redis缓存啊!” “小明,我想实现一个简单的消息队列?”“Redis缓存啊!” “小明,分布式锁这玩意有什么方案?”“Redis缓存啊!” “小明 ...
- 北邮OJ-257- 最近公共祖先-软件14 java
思路分析:思路应该比较简单也很容易想的来,就是比较两个节点的最近的祖先节点,要对每个节点依次记录下他的所有祖先节点,包括其自己,因为自己也算自己的祖先节点,这一点题目中没有明确指出 所以比较坑. 我们 ...
- Spring03——有关于 Spring AOP 的总结
本文将为各位带来 Spring 的另一个重点知识点 -- Spring AOP.关注我的公众号「Java面典」,每天 10:24 和你一起了解更多 Java 相关知识点. 什么是 AOP 面向切面编程 ...
- pd库dataframe基本操作
一.查看数据(查看对象的方法对于Series来说同样适用) 1.查看DataFrame前xx行或后xx行 a=DataFrame(data); a.head(6)表示显示前6行数据,若head()中不 ...
- Redis系列(一):小试牛刀
引言 随着互联网的高速发展,传统的关系数据库(如MySQL.Microsoft SQL Server等)已不能满足日益增长的业务需求,如商品秒杀.抢购等及时性非常强的功能,随着应用高并发的访问,会造成 ...
- 在Keras中可视化LSTM
作者|Praneet Bomma 编译|VK 来源|https://towardsdatascience.com/visualising-lstm-activations-in-keras-b5020 ...
- POJ-3134-Power Calculus(迭代加深)
题意:输入一个n,问x从1次方开始,到n次方 ,可以乘或除已经计算出来的数 ,最少需要执行多少步? 思路:迭代加深 ,深度从0开始 ,直到返回值为真. 在深搜过程中剪枝(深度的判断 ,当前最大值尽全力 ...
- html ajax 异步加载 局部刷新
1. getJSON 优点: 简单高效,直接返回处理好的json数据 缺点: 只能使用get请求和使用json数据 <script src ='jquery.min.js'></sc ...
- Django-User
User对象 User对象是认证系统的核心.用户对象通常用来代表网站的用户,并支持例如访问控制.注册用户.关联创建者和内容等.在Django认证框架中只有一个用户类,例如超级用户('superuser ...