Golang Web入门(2):如何实现一个高性能的路由
摘要
在上一篇文章中,我们聊了聊在Golang中怎么实现一个Http服务器。但是在最后我们可以发现,固然DefaultServeMux可以做路由分发的功能,但是他的功能同样是不完善的。
由DefaultServeMux做路由分发,是不能实现RESTful风格的API的,我们没有办法定义请求所需的方法,也没有办法在API路径中加入query参数。其次,我们也希望可以让路由查找的效率更高。
所以在这篇文章中,我们将分析httprouter这个包,从源码的层面研究他是如何实现我们上面提到的那些功能。并且,对于这个包中最重要的前缀树,本文将以图文结合的方式来解释。
1 使用
我们同样以怎么使用作为开始,自顶向下的去研究httprouter。我们先来看看官方文档中的小例子:
package main
import (
"fmt"
"net/http"
"log"
"github.com/julienschmidt/httprouter"
)
func Index(w http.ResponseWriter, r *http.Request, _ httprouter.Params) {
fmt.Fprint(w, "Welcome!\n")
}
func Hello(w http.ResponseWriter, r *http.Request, ps httprouter.Params) {
fmt.Fprintf(w, "hello, %s!\n", ps.ByName("name"))
}
func main() {
router := httprouter.New()
router.GET("/", Index)
router.GET("/hello/:name", Hello)
log.Fatal(http.ListenAndServe(":8080", router))
}
其实我们可以发现,这里的做法和使用Golang自带的net/http包的做法是差不多的。都是先注册相应的URI和函数,换一句话来说就是将路由和处理器相匹配。
在注册的时候,使用router.XXX方法,来注册相对应的方法,比如GET,POST等等。
注册完之后,使用http.ListenAndServe开始监听。
至于为什么,我们会在后面的章节详细介绍,现在只需要先了解做法即可。
2 创建
我们先来看看第一行代码,我们定义并声明了一个Router。下面来看看这个Router的结构,这里把与本文无关的其他属性省略:
type Router struct {
//这是前缀树,记录了相应的路由
trees map[string]*node
//记录了参数的最大数目
maxParams uint16
}
在创建了这个Router的结构后,我们就使用router.XXX方法来注册路由了。继续看看路由是怎么注册的:
func (r *Router) GET(path string, handle Handle) {
r.Handle(http.MethodGet, path, handle)
}
func (r *Router) POST(path string, handle Handle) {
r.Handle(http.MethodPost, path, handle)
}
...
在这里还有一长串的方法,他们都是一样的,调用了
r.Handle(http.MethodPost, path, handle)
这个方法。我们再来看看:
func (r *Router) Handle(method, path string, handle Handle) {
...
if r.trees == nil {
r.trees = make(map[string]*node)
}
root := r.trees[method]
if root == nil {
root = new(node)
r.trees[method] = root
r.globalAllowed = r.allowed("*", "")
}
root.addRoute(path, handle)
...
}
在这个方法里,同样省略了很多细节。我们只关注一下与本文有关的。我们可以看到,在这个方法中,如果tree还没有初始化,则先初始化这颗前缀树。
然后我们注意到,这颗树是一个map结构。也就是说,一个方法,对应了一颗树。然后,对应这棵树,调用addRoute方法,把URI和对应的Handle保存进去。
3 前缀树
3.1 定义
又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
简单的来讲,就是要查找什么,只要跟着这棵树的某一条路径找,就可以找得到。
比如在搜索引擎中,你输入了一个蔡:
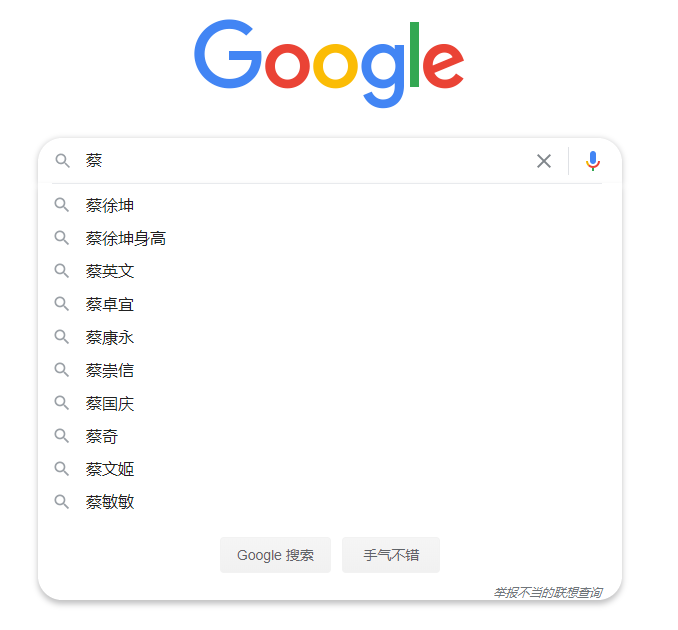
他会有这些联想,也可以理解为是一个前缀树。
再举个例子:
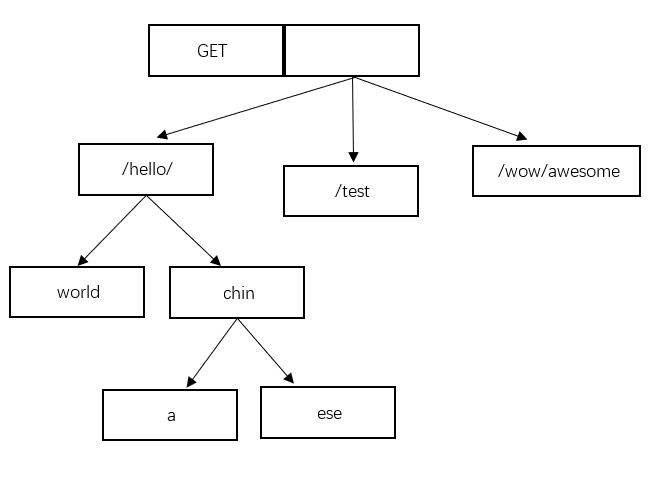
在这颗GET方法的前缀树中,包含了以下的路由:
- /wow/awesome
- /test
- /hello/world
- /hello/china
- /hello/chinese
说到这里你应该可以理解了,在构建这棵树的过程中,任何两个节点,只要有了相同的前缀,相同的部分就会被合并成一个节点。
3.2 图解构建
上面说的addRoute方法,就是这颗前缀树的插入方法。假设现在数为空,在这里我打算以图解的方式来说明这棵树的构建。
假设我们需要插入的三个路由分别为:
- /hello/world
- /hello/china
- /hello/chinese
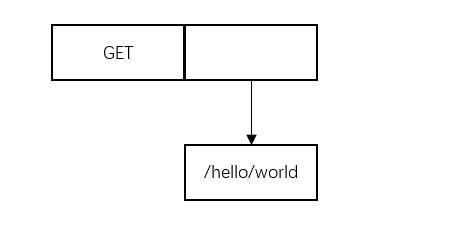
(1)插入/hello/world
因为此时树为空,所以可以直接插入:
(2)插入/hello/china
此时,发现/hello/world和/hello/china有相同的前缀/hello/。
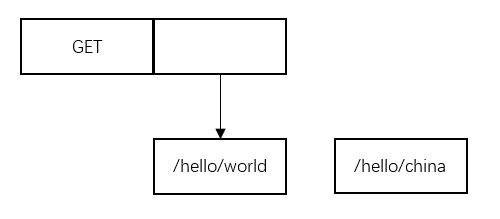
那么要先将原来的/hello/world结点,拆分出来,然后将要插入的结点/hello/china,截去相同部分,作为/hello/world的子节点。

(3)插入/hello/chinese
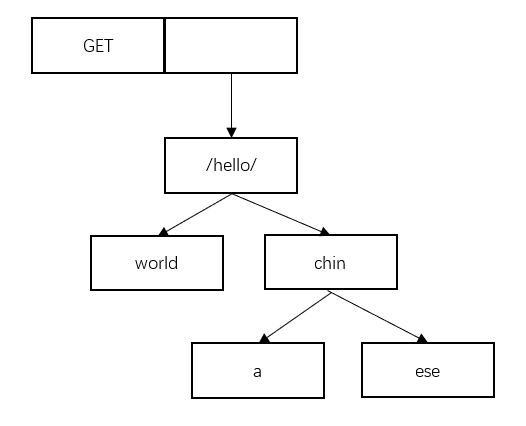
此时,我们需要插入/hello/chinese,但是发现,/hello/chinese和结点/hello/有公共的前缀/hello/,所以我们去查看/hello/这个结点的子节点。
注意,在结点中有一个属性,叫indices。它记录了这个结点的子节点的首字母,便于我们查找。比如这个/hello/结点,他的indices值为wc。而我们要插入的结点是/hello/chinese,除去公共前缀后,chinese的第一个字母也是c,所以我们进入china这个结点。

这时,有没有发现,情况回到了我们一开始插入/hello/china时候的局面。那个时候公共前缀是/hello/,现在的公共前缀是chin。
所以,我们同样把chin截出来,作为一个结点,将a作为这个结点的子节点。并且,同样把ese也作为子节点。
3.3 总结构建算法
到这里,构建就已经结束了。我们来总结一下算法。
具体带注释的代码将在本文最末尾给出,如果想要了解的更深可以自行查看。在这里先理解这个过程:
(1)如果树为空,则直接插入
(2)否则,查找当前的结点是否与要插入的URI有公共前缀
(3)如果没有公共前缀,则直接插入
(4)如果有公共前缀,则判断是否需要分裂当前的结点
(5)如果需要分裂,则将公共部分作为父节点,其余的作为子节点
(6)如果不需要分裂,则寻找有无前缀相同的子节点
(7)如果有前缀相同的,则跳到(4)
(8)如果没有前缀相同的,直接插入
(9)在最后的结点,放入这条路由对应的Handle
但是到了这里,有同学要问了:怎么这里的路由,不带参数的呀?
其实只要你理解了上面的过程,带参数也是一样的。逻辑是这样的:在每次插入之前,会扫描当前要插入的结点的path是否带有参数(即扫描有没有/或者*)。如果带有参数的话,将当前结点的wildChild属性设置为true,然后将参数部分,设置为一个新的子节点。
4 监听
在讲完了路由的注册,我们来聊聊路由的监听。
在上一篇文章的内容中,我们有提到这个:
type serverHandler struct {
srv *Server
}
func (sh serverHandler) ServeHTTP(rw ResponseWriter, req *Request) {
handler := sh.srv.Handler
if handler == nil {
handler = DefaultServeMux
}
if req.RequestURI == "*" && req.Method == "OPTIONS" {
handler = globalOptionsHandler{}
}
handler.ServeHTTP(rw, req)
}
当时我们提到,如果我们不传入任何的Handle方法,Golang将使用默认的DefaultServeMux方法来处理请求。而现在我们传入了router,所以将会使用router来处理请求。
因此,router也是实现了ServeHTTP方法的。我们来看看(同样省略了一些步骤):
func (r *Router) ServeHTTP(w http.ResponseWriter, req *http.Request) {
...
path := req.URL.Path
if root := r.trees[req.Method]; root != nil {
if handle, ps, tsr := root.getValue(path, r.getParams); handle != nil {
if ps != nil {
handle(w, req, *ps)
r.putParams(ps)
} else {
handle(w, req, nil)
}
return
}
}
...
// Handle 404
if r.NotFound != nil {
r.NotFound.ServeHTTP(w, req)
} else {
http.NotFound(w, req)
}
}
在这里,我们选择请求方法所对应的前缀树,调用了getValue方法。
简单解释一下这个方法:在这个方法中会不断的去匹配当前路径与结点中的path,直到找到最后找到这个路由对应的Handle方法。
注意,在这期间,如果路由是RESTful风格的,在路由中含有参数,将会被保存在Param中,这里的Param结构如下:
type Param struct {
Key string
Value string
}
如果未找到相对应的路由,则调用后面的404方法。
5 处理
到了这一步,其实和以前的内容几乎一样了。
在获取了该路由对应的Handle之后,调用这个函数。
唯一和之前使用net/http包中的Handler不一样的是,这里的Handle,封装了从API中获取的参数。
type Handle func(http.ResponseWriter, *http.Request, Params)
6 写在最后
谢谢你能看到这里~
至此,httprouter介绍完毕,最关键的也就是前缀树的构建了。在上面我用图文结合的方式,模拟了一次前缀树的构建过程,希望可以让你理解前缀树是怎么回事。当然,如果还有疑问,也可以留言或者在微信中与我交流~
当然,如果你不满足于此,可以看看后面的附录,有前缀树的全代码注释。
当然了,作者也是刚入门。所以,可能会有很多的疏漏。如果在阅读的过程中,有哪些解释不到位,或者理解出现了偏差,也请你留言指正。
再次感谢~
PS:如果有其他的问题,也可以在公众号找到作者。并且,所有文章第一时间会在公众号更新,欢迎来找作者玩~

7 源码阅读
7.1 树的结构
type node struct {
path string //当前结点的URI
indices string //子结点的首字母
wildChild bool //子节点是否为参数结点
nType nodeType //结点类型
priority uint32 //权重
children []*node //子节点
handle Handle //处理器
}
7.2 addRoute
func (n *node) addRoute(path string, handle Handle) {
fullPath := path
n.priority++
// 如果这是个空树,那么直接插入
if len(n.path) == 0 && len(n.indices) == 0 {
//这个方法其实是在n这个结点插入path,但是会处理参数
//详细实现在后文会给出
n.insertChild(path, fullPath, handle)
n.nType = root
return
}
//设置一个flag
walk:
for {
// 找到当前结点path和要插入的path中最长的前缀
// i为第一位不相同的下标
i := longestCommonPrefix(path, n.path)
// 此时相同的部分比这个结点记录的path短
// 也就是说需要把当前的结点分裂开
if i < len(n.path) {
child := node{
// 把不相同的部分设置为一个切片,作为子节点
path: n.path[i:],
wildChild: n.wildChild,
nType: static,
indices: n.indices,
children: n.children,
handle: n.handle,
priority: n.priority - 1,
}
// 将新的结点作为这个结点的子节点
n.children = []*node{&child}
// 把这个结点的首字母加入indices中
// 目的是查找更快
n.indices = string([]byte{n.path[i]})
n.path = path[:i]
n.handle = nil
n.wildChild = false
}
// 此时相同的部分只占了新URI的一部分
// 所以把path后面不相同的部分要设置成一个新的结点
if i < len(path) {
path = path[i:]
// 此时如果n的子节点是带参数的
if n.wildChild {
n = n.children[0]
n.priority++
// 判断是否会不合法
if len(path) >= len(n.path) && n.path == path[:len(n.path)] &&
n.nType != catchAll &&
(len(n.path) >= len(path) || path[len(n.path)] == '/') {
continue walk
} else {
pathSeg := path
if n.nType != catchAll {
pathSeg = strings.SplitN(pathSeg, "/", 2)[0]
}
prefix := fullPath[:strings.Index(fullPath, pathSeg)] + n.path
panic("'" + pathSeg +
"' in new path '" + fullPath +
"' conflicts with existing wildcard '" + n.path +
"' in existing prefix '" + prefix +
"'")
}
}
// 把截取的path的第一位记录下来
idxc := path[0]
// 如果此时n的子节点是带参数的
if n.nType == param && idxc == '/' && len(n.children) == 1 {
n = n.children[0]
n.priority++
continue walk
}
// 这一步是检查拆分出的path,是否应该被合并入子节点中
// 具体例子可看上文中的图解
// 如果是这样的话,把这个子节点设置为n,然后开始一轮新的循环
for i, c := range []byte(n.indices) {
if c == idxc {
// 这一部分是为了把权重更高的首字符调整到前面
i = n.incrementChildPrio(i)
n = n.children[i]
continue walk
}
}
// 如果这个结点不用被合并
if idxc != ':' && idxc != '*' {
// 把这个结点的首字母也加入n的indices中
n.indices += string([]byte{idxc})
child := &node{}
n.children = append(n.children, child)
n.incrementChildPrio(len(n.indices) - 1)
// 新建一个结点
n = child
}
// 对这个结点进行插入操作
n.insertChild(path, fullPath, handle)
return
}
// 直接插入到当前的结点
if n.handle != nil {
panic("a handle is already registered for path '" + fullPath + "'")
}
n.handle = handle
return
}
}
7.3 insertChild
func (n *node) insertChild(path, fullPath string, handle Handle) {
for {
// 这个方法是用来找这个path是否含有参数的
wildcard, i, valid := findWildcard(path)
// 如果不含参数,直接跳出循环,看最后两行
if i < 0 {
break
}
// 条件校验
if !valid {
panic("only one wildcard per path segment is allowed, has: '" +
wildcard + "' in path '" + fullPath + "'")
}
// 同样判断是否合法
if len(wildcard) < 2 {
panic("wildcards must be named with a non-empty name in path '" + fullPath + "'")
}
if len(n.children) > 0 {
panic("wildcard segment '" + wildcard +
"' conflicts with existing children in path '" + fullPath + "'")
}
// 如果参数的第一位是`:`,则说明这是一个参数类型
if wildcard[0] == ':' {
if i > 0 {
// 把当前的path设置为参数之前的那部分
n.path = path[:i]
// 准备把参数后面的部分作为一个新的结点
path = path[i:]
}
//然后把参数部分作为新的结点
n.wildChild = true
child := &node{
nType: param,
path: wildcard,
}
n.children = []*node{child}
n = child
n.priority++
// 这里的意思是,path在参数后面还没有结束
if len(wildcard) < len(path) {
// 把参数后面那部分再分出一个结点,continue继续处理
path = path[len(wildcard):]
child := &node{
priority: 1,
}
n.children = []*node{child}
n = child
continue
}
// 把处理器设置进去
n.handle = handle
return
} else { // 另外一种情况
if i+len(wildcard) != len(path) {
panic("catch-all routes are only allowed at the end of the path in path '" + fullPath + "'")
}
if len(n.path) > 0 && n.path[len(n.path)-1] == '/' {
panic("catch-all conflicts with existing handle for the path segment root in path '" + fullPath + "'")
}
// 判断在这之前有没有一个/
i--
if path[i] != '/' {
panic("no / before catch-all in path '" + fullPath + "'")
}
n.path = path[:i]
// 设置一个catchAll类型的子节点
child := &node{
wildChild: true,
nType: catchAll,
}
n.children = []*node{child}
n.indices = string('/')
n = child
n.priority++
// 把后面的参数部分设置为新节点
child = &node{
path: path[i:],
nType: catchAll,
handle: handle,
priority: 1,
}
n.children = []*node{child}
return
}
}
// 对应最开头的部分,如果这个path里面没有参数,直接设置
n.path = path
n.handle = handle
}
最关键的几个方法到这里就全部结束啦,先给看到这里的你鼓个掌!
这一部分理解会比较难,可能需要多看几遍。
如果还是有难以理解的地方,欢迎留言交流,或者直接来公众号找我~
Golang Web入门(2):如何实现一个高性能的路由的更多相关文章
- Golang Web入门(4):如何设计API
摘要 在之前的几篇文章中,我们从如何实现最简单的HTTP服务器,到如何对路由进行改进,到如何增加中间件.总的来讲,我们已经把Web服务器相关的内容大概梳理了一遍了.在这一篇文章中,我们将从最简单的一个 ...
- Golang Web入门(1):自顶向下理解Http服务器
摘要 由于Golang优秀的并发处理,很多公司使用Golang编写微服务.对于Golang来说,只需要短短几行代码就可以实现一个简单的Http服务器.加上Golang的协程,这个服务器可以拥有极高的性 ...
- Golang Web入门(3):如何优雅的设计中间件
摘要 在上一篇文章中,我们已经可以实现一个性能较高,且支持RESTful风格的路由了.但是,在Web应用的开发中,我们还需要一些可以被扩展的功能. 因此,在设计框架的过程中,应该留出可以扩展的空间,比 ...
- golang web框架设计2:自定义路由
继续学习谢大的Go web框架设计 HTTP路由 http路由负责将一个http的请求交到对应的函数处理(或者一个struct的方法),路由在框架中相当于一个事件处理器,而这个时间包括 用户请求的路径 ...
- JAVA WEB快速入门之从编写一个基于SpringBoot+Mybatis快速创建的REST API项目了解SpringBoot、SpringMVC REST API、Mybatis等相关知识
JAVA WEB快速入门系列之前的相关文章如下:(文章全部本人[梦在旅途原创],文中内容可能部份图片.代码参照网上资源) 第一篇:JAVA WEB快速入门之环境搭建 第二篇:JAVA WEB快速入门之 ...
- golang快速入门(五)初尝web服务
提示:本系列文章适合对Go有持续冲动的读者 初探golang web服务 golang web开发是其一项重要且有竞争力的应用,本小结来看看再golang中怎么创建一个简单的web服务. 在不适用we ...
- Golang快速入门
Go语言简介: Golang 简称 Go,是一个开源的编程语言,Go是从2007年末由 Robert Griesemer, Rob Pike, Ken Thompson主持开发,后来还加入了Ian L ...
- 8、web入门回顾/ Http
1 web入门回顾 web入门 1)web服务软件作用: 把本地资源共享给外部访问 2)tomcat服务器基本操作 : 启动: %tomcat%/bin/startup.bat 关闭: % ...
- Asp.Net MVC4.0 官方教程 入门指南之四--添加一个模型
Asp.Net MVC4.0 官方教程 入门指南之四--添加一个模型 在这一节中,你将添加用于管理数据库中电影的类.这些类是ASP.NET MVC应用程序的模型部分. 你将使用.NET Framewo ...
随机推荐
- 学习笔记----C语言的面向对象
2020-03-26 21:27:17 面向对象的编程语言都有一个类的概念,像Java.python等.类是对特定数据的特定操作的集合体.它包含两个范畴:数据和操作.C语言是没有类的概念的,但是 ...
- HTTPS加密传输过程
HTTPS加密传输过程 HTTPS全称Hyper Text Transfer Protocol over SecureSocket Layer,是以安全为目标的HTTP通道,在HTTP的基础上通过传输 ...
- payload分离免杀
shellcode loader 借助第三方加载器,将shellcode加载到内存中来执行. https://github.com/clinicallyinane/shellcode_launcher ...
- cmdb客户端采集数据的完善
file文件自己去拷贝(这里不提供) custom_settings.py import os BASEDIR = os.path.dirname(os.path.dirname(os.path.ab ...
- Hive设置配置参数的方法,列举8个常用配置
Hive设置配置参数的方法 Hive提供三种可以改变环境变量的方法,分别是: (1).修改${HIVE_HOME}/conf/hive-site.xml配置文件: (2).命令行参数: (3).在已经 ...
- OpenCV-Python 轮廓分层 | 二十五
目标 这次我们学习轮廓的层次,即轮廓中的父子关系. 理论 在前几篇关于轮廓的文章中,我们已经讨论了与OpenCV提供的轮廓相关的几个函数.但是当我们使用cv.findcontour()函数在图像中找到 ...
- Thread wait notify sleep
wait: 必须暂定当前正在执行的线程,并释放资源锁,让其他线程可以有机会运行 notify/notifyall: 唤醒因锁池中的线程,使之运行 wait与sleep区别 对于sleep()方法,我们 ...
- Dockerfile极简入门与实践
前文中,罗列了docker使用中用到的基本命令 此文,将会对怎样使用Dockerfile去创建一个镜像做简单的介绍 Dockerfile命令 要开始编写Dockerfile,首先要对相关的命令有个清晰 ...
- Python——交互式图形编程
一. 1.图形显示 图素法 像素法 图素法---矢量图:以图形对象为基本元素组成的图形,如矩形. 圆形 像素法---标量图:以像素点为基本单位形成图形 2.图形用户界面:Graphical User ...
- linux进程和线程直接通信方式梳理
对于linux的进程之间.线程直接的通信方式进行梳理,这些都属于基本知识,不过因为知识体系“年久失修”,需要重新总结汇总.