Python 分布式缓存之Reids数据类型操作
1、Redis API
1.操作模式
redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py。

1.安装redis模块
$ pip3.8 install redis
2.使用redis模块
import redis
# 连接redis的ip地址/主机名,port,password=None
r = redis.Redis(host="127.0.0.1",port=6379,password="gs123456")
2.redis连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
总之,当程序创建数据源实例时,系统会一次性创建多个数据库连接,并把这些数据库连接保存在连接池中,当程序需要进行数据库访问时,无需重新新建数据库连接,而是从连接池中取出一个空闲的数据库连接
import redis
# 创建连接池,将连接保存在连接池中
pool = redis.ConnectionPool(host="127.0.0.1",port=6379,password="gs123456",max_connections=10)
# 创建一个redis实例,并使用连接池"pool"
r = redis.Redis(connection_pool=pool)
2、String 操作
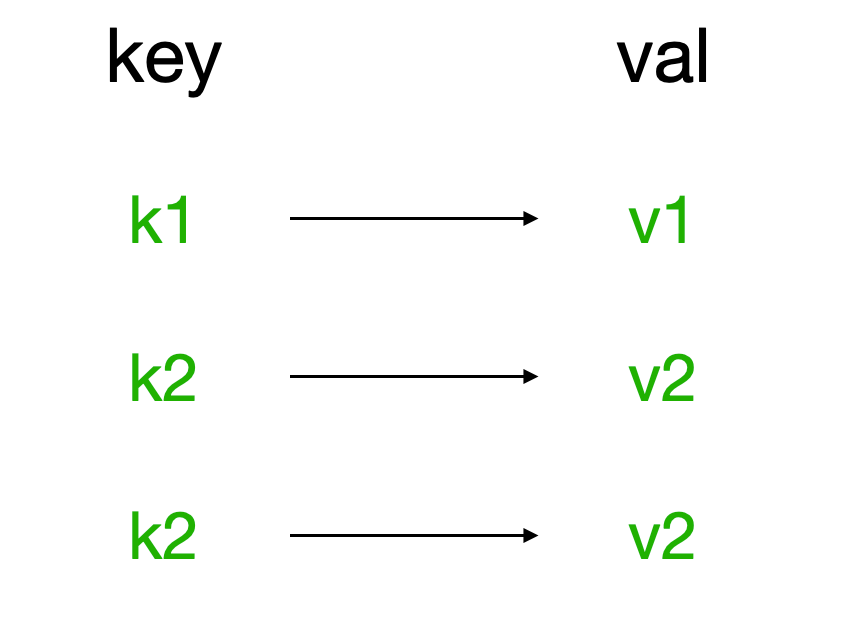
redis中的String在内存中按照一个name对应一个value来存储。如图:
1. set 为name设置值
# 在Redis中设置值,默认,不存在则创建,存在则修改
set(name, value, ex=None, px=None, nx=False, xx=False, keepttl=False)
name:设置键
value:设置值
ex:设置过期时间(秒级)
px:设置过期时间(毫秒)
nx:如果设置为True,则只有name不存在时,当前set操作才执行,同setnx(name, value)
xx:如果设置为True,则只有name存在时,当前set操作才执行
set用法:
r.set("name1","jack",ex=3600)
r.set("name2","xander",xx=36000)
setnx用法:
# 设置值,只有name不存在时,执行设置操作(添加)
setnx(name, value)
setex用法:
# 设置值,参数:time -->过期时间(数字秒 或 timedelta对象)
setex(name, value, time)
psetex用法:
# 设置值,参数:time_ms,过期时间(数字毫秒 或 timedelta对象)
psetex(name, time_ms, value)
2. get 获取name的值
# 根据key获取值
get(name)
r.get("foo")
3. mset 批量设置name的值:
mset(mapping)
data = {
"k1":"v1",
"k2":"v2",
}
r.mset(data)
4. Mget 批量获取name的值
# 批量获取值,根据多key获取多个值
mgets(mapping)
# 方法一
r.mget("k1","k2")
# 方法二
data = ["k1","k2"]
r.mget(data)
# 方法三
data = ("k1","k2")
r.mget(data)
5. getset 设置新值并获取原来的值
getset(name, value)
r.set("foo", "xoo")
ret = r.getset("foo", "yoo")
print(ret) # b'xoo'
6. append 为name原有值后追加内容
# key对应值的后面追加内容
append(key, value)
r.set("name","jack")
r.append("name","-m")
ret = r.get("name")
print(ret) # b'jack-m'
7. strlen 返回name的值字节长度:
# 返回字符串的长度,当name不存在时返回0
strlen(name)
r.set("name","jack-")
ret = r.strlen("name")
print(ret) # 5
8. incr 为name整数累加值
# 自增mount对应的值,当mount不存在时,则创建mount=amount,否则,则自增,amount为自增数(整数)
incr(name, amount=1)
r.incr('mount')
r.incr('mount')
r.incr('mount', amount=3)
ret = r.get('mount')
print(ret) # b'5'
3、Hash 操作
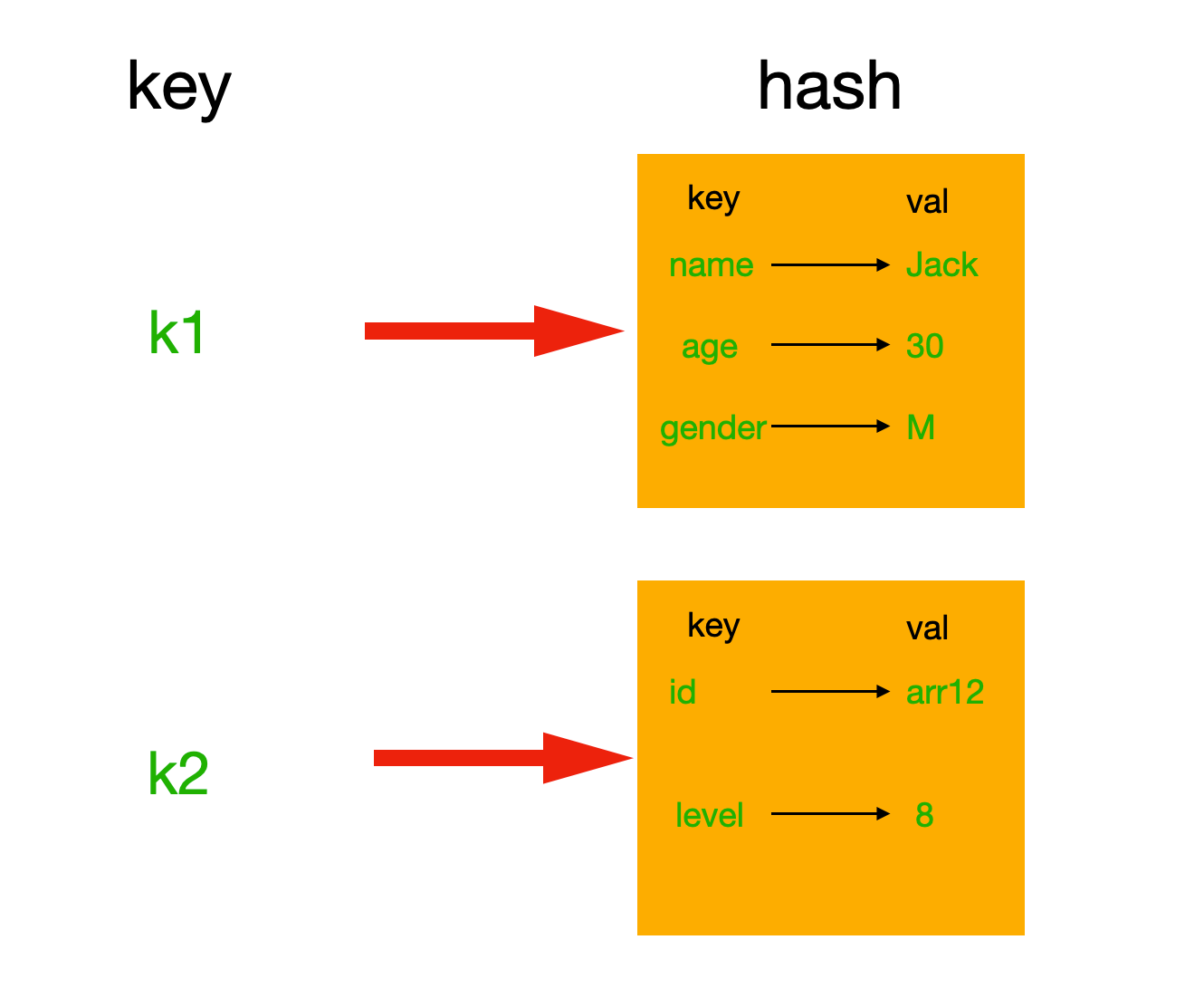
hash表现形式上有些像pyhton中的dict,可以存储一组关联性较强的数据 ,redis中Hash在内存中的存储格式如下图:
1. hset 为name设置单个键值对
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
hset(name, key, value)
name:设置name
key:name对应hash中的key(键)
value:name对应的hash中的value(值)
hset用法
# 一次只能设置一个键值对
r.hset("student-jack", "name", "Jack")
2 . hget 获取name单个键值对
# 根据name对应的hash中获取根据key获取value
hget(name,key)
ret = r.hget("student-jack", "name")
print(ret) // b'Jack'
3. hmset 为name设置多个键值对
# mapping中传入字典(不存在,则创建;否则,修改)
hmset(name, mapping):
data = {
"name": "Jack",
"age": 20,
"gender": "M",
}
r.hmset("student-jack", mapping=data)
4. hmget 获取name多个键值对
# 根据name对应的hash中获取多个key的值
hmget(name, keys, *args)
name:指定name
keys:要获取key集合,如:['k1', 'k2', 'k3']
*args:要获取的key,如:k1,k2,k3
# 直接传入需要获取的键
ret = r.hmget("student-jack", "name", "age")
print(ret) # [b'Jack', b'20']
# 列表中指定需要获取的键
data = ["name", "age"]
ret = r.hmget("student-jack", data)
print(ret) # [b'Jack', b'20']
5. hgetall 获取name的键值对
# 根据name获取hash的所有值
hgetall(name)
ret = r.hgetall("student-jack")
print(ret) # {b'name': b'Jack', b'age': b'20', b'gender': b'M'}
6、hlen 获取name中的键值对个数
# 根据name获取hash中键值对的总个数
hlen(name)
ret = r.hlen("student-jack")
print(ret) # 3 , 3个键值对
7. hkeys 获取name中键值对所有key
# 获取name里键值对的key
hkeys(name)
ret = r.hkeys('student-jack')
print(ret) # [b'name', b'age', b'gender']
8. hvals 获取name中键值对所有value
# 获取name里键值对的value
hvals(name)
ret = r.hvals('student-jack')
print(ret) # [b'Jack', b'20', b'M']
9. hkeys 检查name里的键值对是否有对应的key
# 根据name检查对应的hash是否存在当前传入的key
hexists(name, key)
# 返回布尔值
ret = r.hexists('student-jack', 'name')
print(ret) # True
10. hincrby 从name里的键值对设置自增值
1.整数自增:
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
hincrby(name, key, amount=1)
name:设置键
key:hash对应的key
amount:自增数(整数)
ret = r.hincrby('student-jack', 'age')
ret = r.hincrby('student-jack', 'age')
print(ret) # 22
2.浮点自增
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
hincrbyfloat(name, key, amount=1.0)
name:设置键
key:hash对应的key
amount:自增数(浮点数)
11. hdel 根据name从键值对中删除指定key
# 根据name将对应hash中指定的key键值对删除
hdel(name,*keys)
r.hdel("info",*("m-k1","m-k2"))
4、List 操作
List操作,redis中的List在内存中按照一个name对应一个List来存储。如图:

1. lpush 为name添加元素,每个新的元素都添加到列表的最左边
# name对应的list中添加元素
lpush(name,values)
# 直接指定多个元素
r.lpush("names", "Jack", "Alex", "Eric")
# 将需要添加的元素添加到元组
data = ("Jack", "Alex", "Eric")
r.rpush("names", *data)
# 将需要添加的元素添加到列表
data = ["Jack", "Alex", "Eric"]
r.rpush("names", *data)
Note:列表类型中的值统称元素
2. rpush 为name添加元素,每个新的元素都添加到列表的最右边
# 同lpush,但每个新的元素都会添加到列表的最右边
rpush(name, values)
3. lpushx 为name添加元素,只有当name已存在时,将元素添加至列表最左边
lpushx(name,value)
4. rpushx 同上,将元素添加至列表最右边
rpushx(name, values)
5. llen 统计name中list的元素个数
# name对应的list元素的个数
llen(name)
ret = r.llen('names')
print(ret) # 3, 该list中有3个元素
6. linsert 为name中list的某一个值或后 插入一个新的值
# 在name对应的列表的某一个值前或后插入一个新值
linsert(name, where, refvalue, value)
name:设置name
where:BEFORE或AFTER
refvalue:标杆值,即:在它前后插入数据
value:要插入的数据
// 在Alex值前插入一个值(BEFORE表示:在...之前)
r.linsert('names', 'BEFORE', 'Jack', 'Jason')
// 在Jack后插入一个值(AFTER表示:在...之后)
r.linsert('names', 'AFTER', 'Jack', 'Xander')
7. lset 为name中list的某一个索引位置的元素重新赋值
# 对name对应的list中的某一个索引位置重新赋值
lset(name, index, value)
name:设置name
index:list的索引位置
value:要设置的值
// 将索引为1的元素修改为Gigi
r.lset('names', 1, 'Gigi')
8. lrem 移除name里对应list的元素
# 在name对应的list中删除指定的值
lrem(name, count, value)
name:设置name
value:要删除的值
count:count=0,删除列表中的指定值;
count=2,从前到后,删除2个;
count=-2,从后向前,删除2个
r.lrem('names', count=2, value='Xander')
9. lpop 从name里的list获取最左侧的第一个元素,并在列表中移除,返回值是则是第一个元素
lpop(name)
ret = r.lpop('names')
print(ret) # b'Jason'
10. rpop 同上,从右侧获取第一个元素
rpop(name)
11. lindex 在name对应的列表 根据索引获取元素
# 在name对应的列表中根据索引获取列表元素
lindex(name, index)
ret = r.lindex('names', 0)
print(ret) # b'Gigi'
12. ltrim 移除列表内没有在该索引之内的值(截断)
# 移除列表内没有在该索引之内的值
ltrim(name, start, end)
r.ltrim("names",0,2)
13. lrange 在name对应的列表 根据索引获取数据
# 在name对应的列表分片获取数据
lrange(name, start, end)
name:设置name
start:索引的起始位置
end:索引结束位置
// 先添加点元素
data = ['Jack', 'Eric', 'Koko', 'Jason', 'Alie']
r.rpush('names', *data)
// 获取列表所有元素
ret = r.lrange('names', 0, -1)
print(ret) # [b'Gigi', b'Alex', b'Jack', b'Eric', b'Koko', b'Jason', b'Alie']
// 获取列表索引2-5的元素(包含2和5,即 2 3 4 5)
ret = r.lrange('names', 2, 5)
print(ret) # [b'Jack', b'Eric', b'Koko', b'Jason']
// 获取列表的最后一个元素
ret = r.lrange('names', -1, -1)
print(ret) # [b'Alie']
Python 分布式缓存之Reids数据类型操作的更多相关文章
- python对缓存(memcached,redis)的操作
1.Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态.数据库驱动网站的 ...
- python笔记二:常用数据类型操作
1.切片:常用于取list或tuple的部分元素的操作 1)l=[1,2,3,4,5,6] l[:3]表示取前3个值,l[1:5]表示1到5个值, L[-3:]从列表最后往前数即最后3个数.... 2 ...
- c#实例化继承类,必须对被继承类的程序集做引用 .net core Redis分布式缓存客户端实现逻辑分析及示例demo 数据库笔记之索引和事务 centos 7下安装python 3.6笔记 你大波哥~ C#开源框架(转载) JSON C# Class Generator ---由json字符串生成C#实体类的工具
c#实例化继承类,必须对被继承类的程序集做引用 0x00 问题 类型“Model.NewModel”在未被引用的程序集中定义.必须添加对程序集“Model, Version=1.0.0.0, Cu ...
- Redis-基本概念、java操作redis、springboot整合redis,分布式缓存,分布式session管理等
NoSQL的引言 Redis数据库相关指令 Redis持久化相关机制 SpringBoot操作Redis Redis分布式缓存实现 Resis中主从复制架构和哨兵机制 Redis集群搭建 Redis实 ...
- 缓存数据库-redis数据类型和操作(list)
转: 狼来的日子里! 奋发博取 缓存数据库-redis数据类型和操作(list) 一:Redis 列表(List) Redis列表是简单的字符串列表,按照插入顺序排序.你可以添加一个元素导列表的头部( ...
- 第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作、增、删、改、查
第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作.增.删.改.查 elasticsearch(搜索引擎)基本的索引 ...
- 第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中
第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中 1.爬虫文件 dispatcher.connect()信号分发器,第一个参数信 ...
- 第三百五十节,Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求
第三百五十节,Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求 selenium模块 selenium模块为 ...
- 四十一 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作、增、删、改、查
elasticsearch(搜索引擎)基本的索引和文档CRUD操作 也就是基本的索引和文档.增.删.改.查.操作 注意:以下操作都是在kibana里操作的 elasticsearch(搜索引擎)都是基 ...
随机推荐
- 乌云jsonp案例
新浪微博之点击我的链接就登录你的微博(JSONP劫持) 生活处处有惊喜啊!逛逛wooyun都能捡到bug. 测试的时候没关burp,逛乌云的时候抓到一条url: http://login.sina.c ...
- uni-app之uni.showToast()image路径问题
uni-app的API中,showToast的icon值只有success,loading,none三种显示,失败没有图标.如果失败时需要显示图标,就要用到自定义图标 image 了. uni.sho ...
- leetcode976之三角形最大周长
题目描述: 给定由一些正数(代表长度)组成的数组 A,返回由其中三个长度组成的.面积不为零的三角形的最大周长. 如果不能形成任何面积不为零的三角形,返回 0. def largePara(A): A. ...
- jchdl - RTL实例 - AndReg
https://mp.weixin.qq.com/s/p4-379tBRYKCYBk8AZoT8A 输入两组线相与,结果输出到寄存器. 参考链接 https://github.com/wjcd ...
- 【Hadoop】hdfs,剖析文件上传
文件上传原理图 剖析文件写入 1.客户端(client)通过对DistributedFileSystem对象调用create()来新建文件: FSDataOutputStream outputStre ...
- Java实现 LeetCode 640 求解方程(计算器的加减法计算)
640. 求解方程 求解一个给定的方程,将x以字符串"x=#value"的形式返回.该方程仅包含'+',' - '操作,变量 x 和其对应系数. 如果方程没有解,请返回" ...
- Java中List,Set,Map的区别以及API的使用
1.面试题:你说说collection里面有什么子类. (其实面试的时候听到这个问题的时候,你要知道,面试官是想考察List,Set) 正如图一,list和set是实现了collection接口的. ...
- Java实现 蓝桥杯 历届试题 数字游戏
问题描述 栋栋正在和同学们玩一个数字游戏. 游戏的规则是这样的:栋栋和同学们一共n个人围坐在一圈.栋栋首先说出数字1.接下来,坐在栋栋左手边的同学要说下一个数字2.再下面的一个同学要从上一个同学说的数 ...
- java实现第六届蓝桥杯九数分三组
九数分三组 题目描述 1~9的数字可以组成3个3位数,设为:A,B,C, 现在要求满足如下关系: B = 2 * A C = 3 * A 请你写出A的所有可能答案,数字间用空格分开,数字按升序排列. ...
- java代码(12) ---CollectionUtils工具类
CollectionUtils工具类 CollectionUtils工具类是在apache下的,而不是springframework下的CollectionUtils 个人觉得在真实项目中Collec ...