python对目录下的文件进行 多条件排序
在进入正题之前,先介绍一下基础知识:
1、sort(),方法:就是对列表内容进行正向排序,直接在原列表进行修改,返回的是修改后的列表
lists =[1, 5, 10, 8, 6]
lists.sort()
print(lists)
>>> [1, 5, 6, 8, 10]
2、sorted() 方法: 对列表进行排序后,返回一个新的列表,而原列表不变。并且sorted()方法可以用在任何数据类型的序列中,而返回的总是一个列表的形式。
lists = [1, 5, 10, 8, 6]
a = sorted(lists)
print(lists)
>>>[1, 5, 10, 8, 6]
print(a)
>>>[1, 5, 6, 8, 10]
3、进行多条件排序,使用参数 key 即可,其返回的顺序就是按照元组的顺序 。如果想要第一个顺序,第二个逆序,只需要在 x[1] 前面加上 -x[1]
lists = [(2, 5), (2, 3), (1, 2), (4, 2), (3, 4)] lists.sort(key=lambda x: (x[0], x[1])) print(lists)
>>>[(1, 2), (2, 3), (2, 5), (3, 4), (4, 2)]
好,介绍完之后,下面进入正题,自定义顺序 读取文件 多条件排序。
如图,要让下面这些文件进行自己想要的顺序排序,首先根据月份排,然后依据日期排;即先五月,从 5_1 到 5_15,然后再到 6_1 ,如果只是单纯的采用 sort() 和sorted()肯定是不能实现的,需要自定义方式,进行排序。
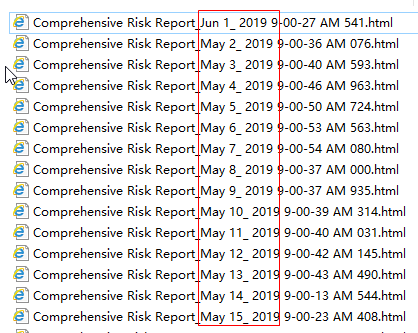
那么怎么来排序呢?
思路就是: 先对文件进行分割,得到 月份 和 天数,然后利用sort() 的key值,进行排序。
import os path = '..\\url\\'
file_selected = os.listdir(path)
month = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'] file_tem = []
file_comp = []
for file in file_selected:
file_tem.append(file) # [file]
value = file.split("_")[1].split(" ")[0]
ind = month.index(value) # 得到月份的下标
file_tem.append(ind) # [file,ind]
num = int(file.split("_")[1].split(" ")[1]) # 得到天数
file_tem.append(num) # [file,ind,num]
file_comp.append(file_tem) # 得到[[file,ind,num],[file2,ind2,num2]]的形式
file_tem = [] file_comp.sort(key=lambda x: (x[1], x[2])) # 根据ind排,再根据num2 排
sorted_file = [x[0] for x in file_comp] print(sorted_file)
最终得到结果:
['Comprehensive Risk Report_May 1_ 2019 9-00-36 AM 076.html',
'Comprehensive Risk Report_May 2_ 2019 9-00-36 AM 076.html',
'Comprehensive Risk Report_May 3_ 2019 9-00-40 AM 593.html',
'Comprehensive Risk Report_May 4_ 2019 9-00-46 AM 963.html',
'Comprehensive Risk Report_May 5_ 2019 9-00-50 AM 724.html',
'Comprehensive Risk Report_May 6_ 2019 9-00-53 AM 563.html',
'Comprehensive Risk Report_May 7_ 2019 9-00-54 AM 080.html',
'Comprehensive Risk Report_May 8_ 2019 9-00-37 AM 000.html',
'Comprehensive Risk Report_May 9_ 2019 9-00-37 AM 935.html',
'Comprehensive Risk Report_May 10_ 2019 9-00-39 AM 314.html',
'Comprehensive Risk Report_May 11_ 2019 9-00-40 AM 031.html',
'Comprehensive Risk Report_May 12_ 2019 9-00-42 AM 145.html',
'Comprehensive Risk Report_May 13_ 2019 9-00-43 AM 490.html',
'Comprehensive Risk Report_May 14_ 2019 9-00-13 AM 544.html',
'Comprehensive Risk Report_May 15_ 2019 9-00-23 AM 408.html',
'Comprehensive Risk Report_Jun 1_ 2019 9-00-27 AM 541.html']
这里为什么采用 file_tem = [ ] 而不是采用 file_tem.clear(),将在下一篇介绍。
python对目录下的文件进行 多条件排序的更多相关文章
- Python打开目录下所有文件
用Python打开指定目录下所有文件,统计文件里特定的字段信息. 这里是先进入2017-02-25到2017-03-03目录,然后进入特定IP段目录下,最后打开文件进行统计 import os, gl ...
- Python遍历目录下所有文件的最后一行进行判断若错误及时邮件报警-案例
遍历目录下所有文件的最后一行进行判断若错误及时邮件报警-案例: #-*- encoding: utf-8 -*- __author__ = 'liudong' import linecache,sys ...
- Python语言获取目录下所有文件
#coding=utf-8# -*- coding: utf-8 -*-import osimport sysreload(sys) sys.setdefaultencoding('utf-8') d ...
- Python遍历目录下xlsx文件
对指定目录下的指定类型文件进行遍历,可对文件名关键字进行条件筛选 返回值为文件地址的列表 import os # 定义一个函数,函数名字为get_all_excel,需要传入一个目录 def get_ ...
- python遍历目录下所有文件
# -*- coding:utf-8 -*- import os if __name__ == "__main__": rootdir = '.\data' list = os.l ...
- python获取目录下所有文件
#方法1:使用os.listdir import os for filename in os.listdir(r'c:\\windows'): print filename #方法2:使用glob模块 ...
- python拷贝目录下的文件
#!/usr/bin/env python # Version = 3.5.2 import shutil base_dir = '/data/media/' file = '/backup/temp ...
- python 读取目录下的文件
参考方法: import os path = r'C:\Users\Administrator\Desktop\file' for filename in os.listdir(path): prin ...
- Python递归遍历目录下所有文件
#自定义函数: import ospath="D:\\Temp_del\\a"def gci (path): """this is a stateme ...
随机推荐
- Train Problem II (卡特兰数+大数问题)
卡特兰数: Catalan数 原理: 令h(1)=1,h(0)=1,catalan数满足递归式: h(n)= h(1)*h(n-1) + h(2)*h(n-2) + ... + h(n-1)h(1) ...
- Spring5源码分析(1)设计思想与结构
1 源码地址(带有中文注解)git@github.com:yakax/spring-framework-5.0.2.RELEASE--.git Spring 的设计初衷其实就是为了简化我们的开发 基于 ...
- Hexo和github搭建个人博客 - 朱晨
GitHub账号 mac/pc 环境 12 node.jsgit 创建GitHub仓库 登陆GitHub,创建一个新的Respository Repository name叫做{username}.g ...
- resourcequota分析(一)-evaluator-v1.5.2
什么是evaluator 大家都知道,Kubernetes中使用resourcequota对配额进行管理.配额的管理涉及两个步骤:1.计算请求所需要的资源:2.比较并更新配额.所以解读resource ...
- 10——PHP中的两种数组【索引数组】与【关联数组】
[索引数组] 用数字作为键名的数组一般叫做索引数组.用字符串表示键的数组就是下面要介绍的关联数组.索引数组的键是整数,而且从0开始以此类推. 索引数组初始化例: <pre name=" ...
- USB小白学习之路(1) Cypress固件架构解析
Cypress固件架构彻底解析及USB枚举 1. RAM的区别 56pin或者100pin的cy7c68013A,只有内部RAM,不支持外部RAM 128pin的cy7c68013A在pin脚EA=0 ...
- 带你学习ES5中新增的方法
1. ES5中新增了一些方法,可以很方便的操作数组或者字符串,这些方法主要包括以下几个方面 数组方法 字符串方法 对象方法 2. 数组方法 迭代遍历方法:forEach().map().filter( ...
- C#开发BIMFACE系列30 服务端API之模型对比1:发起模型对比
系列目录 [已更新最新开发文章,点击查看详细] 在实际项目中,由于需求变更经常需要对模型文件进行修改.为了便于用户了解模型在修改前后发生的变化,BIMFACE提供了模型在线对比功能,可以利用在 ...
- electron+vue制作桌面应用--自定义标题栏
electron会默认显示边框和标题栏,如下图 我们来看一下如何自定义一个更加有(gao)意(da)思(shang)的标题栏,例如网易云音乐这种 首先我们要把默认的标题栏删掉,找到主进程中创建窗体部分 ...
- 前端每日实战:113# 视频演示如何用纯 CSS 创作一个赛车 loader
效果预览 按下右侧的"点击预览"按钮可以在当前页面预览,点击链接可以全屏预览. https://codepen.io/comehope/pen/mGdXGJ 可交互视频 此视频是可 ...