机器学习实战:意大利Covid-19病毒感染数学模型及预测
作者:Gianluca Malato
deephub翻译组:刘欣然
当今世界正在与一个新的敌人作斗争,那就是Covid-19病毒。
该病毒自首次在中国出现以来,在世界范围内迅速传播。不幸的是,意大利的Covid-19感染人数是欧洲最高的,为19人。我们是西方世界第一个面对这个新敌人的国家,我们每天都在与这种病毒带来的经济和社会影响作斗争。
在本文中,我将用Python向您展示感染增长的简单数学分析和两个模型,以更好地理解感染的演变。
数据收集(Data collection)
意大利民防部门每天都会更新感染者的累积数据。这些数据在GitHub上作为开放数据公开在Github这里:
https://raw.githubusercontent.com/pcm-dpc/COVID-19/master/dati-andamento-nazionale/dpc-covid19-ita-andamento-nazionale.csv
我的目标是创建迄今为止受感染人数(即实际感染人数加上已感染人数)的时间序列模型。这些模型具有参数,这些参数将通过曲线拟合进行估算。
我们用Python来做。
首先,让我们导入一些库。
importpandas as pd
importnumpy as np
from datetime import datetime,timedelta
from sklearn.metrics import mean_squared_error
from scipy.optimize import curve_fit
from scipy.optimize import fsolve
import matplotlib.pyplot as plt
%matplotlib inline现在,让我们看一下原始数据。
url = https://raw.githubusercontent.com/pcm-dpc/COVID-19/master/dati-andamento-nazionale/dpc-covid19-ita-andamento-nazionale.csv
df =pd.read_csv(url)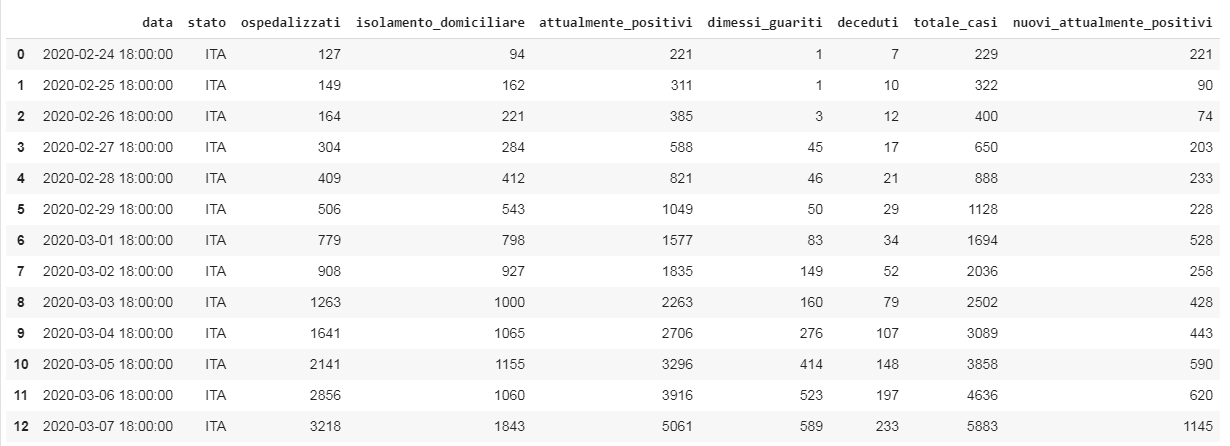
我们需要的列是' totale_casi ',它包含到目前为止的累计感染人数。
这是原始数据。现在,让我们为分析做准备。
数据准备(Data preparation)
首先,我们需要将日期改为数字。我们将从一月一日起开始算。
df =df.loc[:,['data','totale_casi']]
FMT ='%Y-%m-%d %H:%M:%S'
date =df['data']
df['data']= date.map(lambda x : (datetime.strptime(x, FMT) -datetime.strptime("2020-01-01 00:00:00", FMT)).days )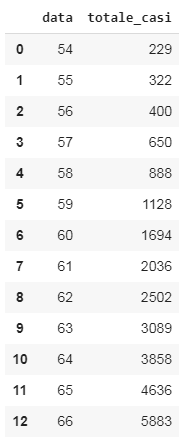
现在,我们可以分析要参加测试的两个模型,分别是逻辑函数(logistic function)和指数函数(exponential function)。
每个模型都有三个参数,这些参数将通过对历史数据进行曲线拟合计算来估计。
logistic模型(The logistic model)
logistic模型被广泛用于描述人口的增长。感染可以被描述为病原体数量的增长,因此使用logistic模型似乎是合理的。
这个公式在数据科学家中非常有名,因为它被用于逻辑回归分类器,并且是神经网络的一个激活函数。
logistic函数最一般的表达式为:
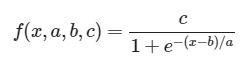
在这个公式中,我们有变量x(它是时间)和三个参数:a,b,c。
•a为感染速度
•b为感染发生最多的一天
•c是在感染结束时记录的感染者总数
在高时间值时,被感染的人数越来越接近c值,也就是我们说感染已经结束的时间点。这个函数在b点也有一个拐点,也就是一阶导数开始下降的点(即感染开始减弱并下降的峰值)。
让我们在Python中定义模型:
def logistic_model(x,a,b,c):
return c/(1+np.exp(-(x-b)/a))我们可以使用scipy库中的curve_fit函数从原始数据开始估计参数值和错误。
x =list(df.iloc[:,0])
y =list(df.iloc[:,1])fit = curve_fit(logistic_model,x,y,p0=[2,100,20000])这里是一些值:
· a: 3.54
· b: 68.00
· c: 15968.38该函数也返回协方差矩阵,其对角值是参数的方差。取它们的平方根,我们就能计算出标准误差。
errors= [np.sqrt(fit[1][i][i]) for i in [0,1,2]]· a的标准误差:0.24
· b的标准误差:1.53
· c的标准误差:4174.69这些数字给了我们许多有用的见解。
预计感染人数在感染结束时为15968+/-4174。
感染高峰预计在2020年3月9日左右。
预期的感染结束日期可以计算为受感染者累计计数四舍五入约等于到最接近整数的c参数的那一天。
我们可以使用scipy的fsolve函数来计算出定义感染结束日的方程的根。
sol =int(fsolve(lambda x : logistic_model(x,a,b,c) - int(c),b))求解出来时间是2020年4月15日。
指数模型(Exponential model)
logistic模型描述了未来将会停止的感染增长,而指数模型描述了不可阻挡的感染增长。例如,如果一个病人每天感染2个病人,1天后我们会有2个感染,2天后4个,3天后8个,等等。
最通用的指数函数是:
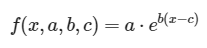
变量x是时间,我们仍然有参数a, b, c,但是它的意义不同于logistic函数参数。
让我们在Python中定义这个函数,并执行与logistic增长相同的曲线拟合过程。
def exponential_model(x,a,b,c):
return a*np.exp(b*(x-c))exp_fit =curve_fit(exponential_model,x,y,p0=[1,1,1])参数及其标准差为:
· a: 0.0019 +/- 64.6796
· b: 0.2278 +/- 0.0073
· c: 0.50 +/- 144254.77画图
我们现在有了所有必要的数据来可视化我们的结果。
pred_x= list(range(max(x),sol))
plt.rcParams['figure.figsize']= [7, 7]
plt.rc('font',size=14)
## Realdata
plt.scatter(x,y,label="Real data",color="red")
#Predicted logistic curve
plt.plot(x+pred_x,[logistic_model(i,fit[0][0],fit[0][1],fit[0][2]) for i inx+pred_x], label="Logistic model" )
#Predicted exponential curve
plt.plot(x+pred_x,[exponential_model(i,exp_fit[0][0],exp_fit[0][1],exp_fit[0][2])for i in x+pred_x], label="Exponential model" )
plt.legend()
plt.xlabel("Days since 1 January 2020")
plt.ylabel("Total number of infected people")
plt.ylim((min(y)*0.9,c*1.1))plt.show()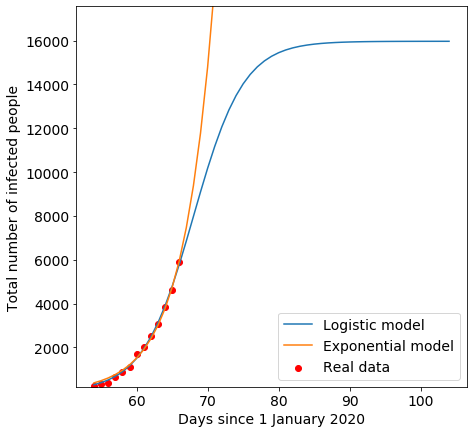
这两条理论曲线似乎都很接近实验趋势。哪一个更好?让我们看一下残差(residuals.)。
残差分析
残差是指各实验点与相应理论点的差值。我们可以通过分析两种模型的残差来验证最佳拟合曲线。在第一次近似中,理论和实验数据的均方误差越小,拟合越好。
y_pred_logistic=[logistic_model(i,fit[0][0],fit[0][1],fit[0][2])
for iin x]y_pred_exp = [exponential_model(i,exp_fit[0][0], exp_fit[0][1], exp_fit[0][2]) for iin x]
mean_squared_error(y,y_pred_logistic)
mean_squared_error(y,y_pred_exp)Logistic模型MSE(均方误差):8254.07
指数模型MSE: 16219.82
哪个是正确的模型?
残差分析似乎指向逻辑模型。很可能是因为感染应该会在将来的某一天结束;即使每个人都会被感染,他们也会适当地发展出免疫防御措施以避免再次感染。只要病毒没有发生太多变异(例如,流感病毒),这就是正确的模型。
但是有些事情仍然让我担心。自感染开始以来,我每天都在拟合logistic曲线,而且每天都有不同的参数值。感染的人数最终会增加,最大感染日通常是当天或第二天(与该参数的1天标准误差是一致的)。
这就是为什么我认为,尽管逻辑模型似乎是最合理的模型,但是曲线的形状可能会由于新的感染热点,政府约束感染的行动措施等外在影响而发生变化。
因此,我认为这个模型的预测只有在感染高峰期之后的几周内才会开始有用。
原文地址:https://imba.deephub.ai/p/cced87c064f711ea90cd05de3860c663

机器学习实战:意大利Covid-19病毒感染数学模型及预测的更多相关文章
- Python两步实现关联规则Apriori算法,参考机器学习实战,包括频繁项集的构建以及关联规则的挖掘
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 机器学习实战笔记-k-近邻算法
机器学习实战笔记-k-近邻算法 目录 1. k-近邻算法概述 2. 示例:使用k-近邻算法改进约会网站的配对效果 3. 示例:手写识别系统 4. 小结 本章介绍了<机器学习实战>这本书中的 ...
- 机器学习实战(Machine Learning in Action)学习笔记————10.奇异值分解(SVD)原理、基于协同过滤的推荐引擎、数据降维
关键字:SVD.奇异值分解.降维.基于协同过滤的推荐引擎作者:米仓山下时间:2018-11-3机器学习实战(Machine Learning in Action,@author: Peter Harr ...
- 机器学习实战:用nodejs实现人脸识别
机器学习实战:用nodejs实现人脸识别 在本文中,我将向你展示如何使用face-recognition.js执行可靠的人脸检测和识别 . 我曾经试图找一个能够精确识别人脸的Node.js库,但是 ...
- 《机器学习实战》——k-近邻算法Python实现问题记录(转载)
py2.7 : <机器学习实战> k-近邻算法 11.19 更新完毕 原文链接 <机器学习实战>第二章k-近邻算法,自己实现时遇到的问题,以及解决方法.做个记录. 1.写一个k ...
- 【机器学习PAI实战】—— 玩转人工智能之商品价格预测
摘要: 我们经常思考机器学习,深度学习,以至于人工智能给我们带来什么?在数据相对充足,足够真实的情况下,好的学习模型可以发现事件本身的内在规则,内在联系.我们去除冗余的信息,可以通过最少的特征构建最简 ...
- Python 机器学习实战 —— 监督学习(上)
前言 近年来AI人工智能成为社会发展趋势,在IT行业引起一波热潮,有关机器学习.深度学习.神经网络等文章多不胜数.从智能家居.自动驾驶.无人机.智能机器人到人造卫星.安防军备,无论是国家级军事设备还是 ...
- Python 机器学习实战 —— 监督学习(下)
前言 近年来AI人工智能成为社会发展趋势,在IT行业引起一波热潮,有关机器学习.深度学习.神经网络等文章多不胜数.从智能家居.自动驾驶.无人机.智能机器人到人造卫星.安防军备,无论是国家级军事设备还是 ...
- Python 机器学习实战 —— 无监督学习(上)
前言 在上篇<Python 机器学习实战 -- 监督学习>介绍了 支持向量机.k近邻.朴素贝叶斯分类 .决策树.决策树集成等多种模型,这篇文章将为大家介绍一下无监督学习的使用.无监督学习顾 ...
随机推荐
- springboot yml 文件配置oracle,提示账号密码错误
最近使用Spring boot,本来一直连接的是mysql数据库,一直没问题.昨天在更换了oracle数据库后,一直提示账号密码不正确,登录被拒绝.检查多次,检查账号密码一切正常,但就是连接不上ora ...
- plsql登录,tables表为空解决方案
共两种方法,第一种不行,再试下第二种: 第一种: plsql tables 表存在,但是看不到所有的表信息 将C:\Windows\Prefetch目录下,几个PLSQL DEVELOPER***** ...
- jenkins-自定义工作空间目录
- python Ajax的使用
转自:http://www.cnblogs.com/python-study/p/6060530.html 1.使用Ajax在后台传递参数的示例 要使用Ajax传递参数,需要使用jquery,使用jq ...
- Archives: 2018/11
There are 35 posts in total till now. 11月 11, 2018 HTTP 11月 11, 2018 TCP与UDP 11月 10, 2018 Python测试 1 ...
- [LC] 256. Paint House
There are a row of n houses, each house can be painted with one of the three colors: red, blue or gr ...
- Web服务器的配置与管理
Web服务器的配置与管理(2) 虚拟主机技术 在上篇博文中,我们已经利用IIS搭建好了一台Web服务器,并可以成功访问IIS中自带的默认站点,那么我们是否可以在这台服务器中再创建另外一个Web站点?也 ...
- windows下apache运行环境搭建
apache的安装 要求: 1,不要安装到有中文的目录中: 2,尽量将apache,php,mysql安装到一个总的目录,便于管理.(如都建立在amp目录下,然后在该目录下分别建立apache,php ...
- 写个匹配某段html dom代码某属性的正则匹配方法
private static string GetHtmlDomAttr(string html, string id, string attrname) { string xmatchstring ...
- 使用java列举所有给定数组中和为定值的组合
import java.util.Arrays; public class SolveProb { ]; ;// 记录当前 public SolveProb() { } public static v ...