python利用(threading,ThreadPoolExecutor.map,ThreadPoolExecutor.submit) 三种多线程方式处理 list数据
需求:在从银行数据库中取出 几十万数据时,需要对 每行数据进行相关操作,通过pandas的dataframe发现数据处理过慢,于是 对数据进行 分段后 通过 线程进行处理;
如下给出 测试版代码,通过 list 分段模拟 pandas 的 dataframe ;
1.使用 threading模块
# -*- coding: utf-8 -*-
# (C) Guangcai Ren <renguangcai@jiaaocap.com>
# All rights reserved
# create time '2019/6/26 14:41'
import math
import random
import time
from threading import Thread _result_list = [] def split_df():
# 线程列表
thread_list = []
# 需要处理的数据
_l = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 每个线程处理的数据大小
split_count = 2
# 需要的线程个数
times = math.ceil(len(_l) / split_count)
count = 0
for item in range(times):
_list = _l[count: count + split_count]
# 线程相关处理
thread = Thread(target=work, args=(item, _list,))
thread_list.append(thread)
# 在子线程中运行任务
thread.start()
count += split_count # 线程同步,等待子线程结束任务,主线程再结束
for _item in thread_list:
_item.join() def work(df, _list):
""" 线程执行的任务,让程序随机sleep几秒 :param df:
:param _list:
:return:
"""
sleep_time = random.randint(1, 5)
print(f'count is {df},sleep {sleep_time},list is {_list}')
time.sleep(sleep_time)
_result_list.append(df) def use():
split_df() if __name__ == '__main__':
y = use()
print(len(_result_list), _result_list)
响应结果如下:
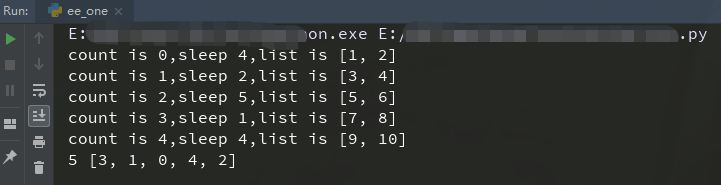
注意点:
脚本中的 _result_list 在项目中 要 放在 函数中,不能直接放在 路由类中,否则会造成 多次请求 数据 污染;
定义线程任务时 thread = Thread(target=work, args=(item, _list,)) 代码中的 work函数 和 参数 要分开,否则 多线程无效
注意线程数不能过多
2.使用ThreadPoolExecutor.map
# -*- coding: utf-8 -*-
# (C) Guangcai Ren <renguangcai@jiaaocap.com>
# All rights reserved
# create time '2019/6/26 14:41'
import math
import random
import time
from concurrent.futures import ThreadPoolExecutor def split_list():
# 线程列表
new_list = []
count_list = []
# 需要处理的数据
_l = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 每个线程处理的数据大小
split_count = 2
# 需要的线程个数
times = math.ceil(len(_l) / split_count)
count = 0
for item in range(times):
_list = _l[count: count + split_count]
new_list.append(_list)
count_list.append(count)
count += split_count
return new_list, count_list def work(df, _list):
""" 线程执行的任务,让程序随机sleep几秒 :param df:
:param _list:
:return:
"""
sleep_time = random.randint(1, 5)
print(f'count is {df},sleep {sleep_time},list is {_list}')
time.sleep(sleep_time)
return sleep_time, df, _list def use():
pool = ThreadPoolExecutor(max_workers=5)
new_list, count_list = split_list()
# map返回一个迭代器,其中的回调函数的参数 最好是可以迭代的数据类型,如list;如果有 多个参数 则 多个参数的 数据长度相同;
# 如: pool.map(work,[[1,2],[3,4]],[0,1]]) 中 [1,2]对应0 ;[3,4]对应1 ;其实内部执行的函数为 work([1,2],0) ; work([3,4],1)
# map返回的结果 是 有序结果;是根据迭代函数执行顺序返回的结果 # 使用map的优点是 每次调用回调函数的结果不用手动的放入结果list中
results = pool.map(work, new_list, count_list)
print(type(results))
# 如下2行 会等待线程任务执行结束后 再执行其他代码
for ret in results:
print(ret)
print('thread execute end!') if __name__ == '__main__':
use()
响应为:

3.使用 ThreadPoolExecutor.submit
# -*- coding: utf-8 -*-
# (C) Guangcai Ren <renguangcai@jiaaocap.com>
# All rights reserved
# create time '2019/6/26 14:41'
import math
import random
import time
from concurrent.futures import ThreadPoolExecutor # 线程池list
pool_list = [] def split_df(pool):
# 需要处理的数据
_l = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 每个线程处理的数据大小
split_count = 2
# 需要的线程个数
times = math.ceil(len(_l) / split_count)
count = 0
for item in range(times):
_list = _l[count: count + split_count]
# 线程相关处理
# submit方法提交可回调的函数,并返回一个future实例;future对象包含相关属性
# 如: done(函数是否执行完成),result(函数执行结果),running(函数是否正在运行)
# 从而 可以在submit 后的代码中 查看 相关任务运行情况
# 此方法 执行数据的结果是无序的,如果需要得到有序的结果,需要 for循环 每个future实例(线程池),如 此脚本代码
f = pool.submit(work, item, _list)
pool_list.append(f)
count += split_count def work(df, _list):
""" 线程执行的任务,让程序随机sleep几秒 :param df:
:param _list:
:return:
"""
sleep_time = random.randint(1, 5)
print(f'count is {df},sleep {sleep_time},list is {_list}')
time.sleep(sleep_time)
return sleep_time, df, _list def use():
pool = ThreadPoolExecutor(max_workers=5)
split_df(pool)
_result_list = []
for item in pool_list:
result_tuple = item.result()
_result_list.append(result_tuple[1])
return _result_list if __name__ == '__main__':
_result_list = use()
print(len(_result_list), _result_list)
结果如下:
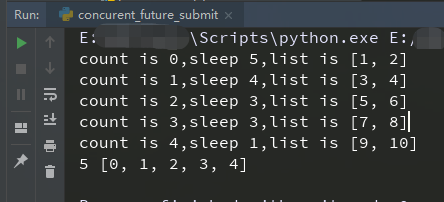
个人比较喜欢使用 第二中方法,代码写的少,返回的是有序结果,回调函数结果自动管理在generator中,直接for循环 map的结果即可;不用担心在 项目中多次请求数据污染问题
相关连接:
https://blog.csdn.net/dutsoft/article/details/54728706
python利用(threading,ThreadPoolExecutor.map,ThreadPoolExecutor.submit) 三种多线程方式处理 list数据的更多相关文章
- oracle Hash Join及三种连接方式
在Oracle中,确定连接操作类型是执行计划生成的重要方面.各种连接操作类型代表着不同的连接操作算法,不同的连接操作类型也适应于不同的数据量和数据分布情况. 无论是Nest Loop Join(嵌套循 ...
- python笔记-20 django进阶 (model与form、modelform对比,三种ajax方式的对比,随机验证码,kindeditor)
一.model深入 1.model的功能 1.1 创建数据库表 1.2 操作数据库表 1.3 数据库的增删改查操作 2.创建数据库表的单表操作 2.1 定义表对象 class xxx(models.M ...
- Map三种遍历方式
Map三种遍历方式 package decorator; import java.util.Collection; import java.util.HashMap; import java.util ...
- python对mysql数据库操作的三种不同方式
首先要说一下,在这个暑期如果没有什么特殊情况,我打算用python尝试写一个考试系统,希望能在下学期的python课程实际使用,并且尽量在此之前把用到的相关技术都以分篇博客的方式分享出来,有想要交流的 ...
- python中的三种输入方式
python中的三种输入方式 python2.X python2.x中以下三个函数都支持: raw_input() input() sys.stdin.readline() raw_input( )将 ...
- python全栈开发day38-css三种引入方式、基础选择器、高级选择器、补充选择器
一.昨日内容回顾 div:分割整个网站,很多块 (1)排版标签 (2)块级标签 独占一行 可以设置高和宽,如果不设置宽高,默认是父盒子的宽 span: (1) 小区域 (2)文本标签 (3)在一行内显 ...
- python selenium 三种等待方式详解[转]
python selenium 三种等待方式详解 引言: 当你觉得你的定位没有问题,但是却直接报了元素不可见,那你就可以考虑是不是因为程序运行太快或者页面加载太慢造成了元素不可见,那就必须要加等待 ...
- 以下三种下载方式有什么不同?如何用python模拟下载器下载?
问题始于一个链接https://i1.pixiv.net/img-zip-...这个链接在浏览器打开,会直接下载一个不完整的zip文件 但是,使用下载器下载却是完整文件 而当我尝试使用python下载 ...
- Python 45 css三种引入方式以及优先级
一:css三种引入方式 三种方式为:行间式 | 内联式 | 外联式 行间式 1.在标签头部的style属性内 2.属性值满足的是css语法 3.属性值用key:value形式赋值,value具 ...
随机推荐
- 前端每日实战:161# 视频演示如何用纯 CSS 创作一张纪念卓别林的卡片(没有笑声的一天就是被荒废的一天)
效果预览 按下右侧的"点击预览"按钮可以在当前页面预览,点击链接可以全屏预览. https://codepen.io/comehope/pen/WaaBNV 可交互视频 此视频是可 ...
- 火狐使用阿里云OOS上传图片报错:“XML 解析错误:找不到根元素”
问题描述: 使用阿里云OOS上传图片在火狐浏览器报错 "XML 解析错误:找不到根元素",但不影响功能的使用.阿里云返回信息: <Error> <Code> ...
- legend3---阿里云如何多个域名指向同一个网站
legend3---阿里云如何多个域名指向同一个网站 一.总结 一句话总结: 先寻求资料及文档,没有找到的话自己摸索一下就好 结论:多个域名都需要备案 二.阿里云如何多个域名指向同一个网站 当前情况 ...
- 利用Eclipse CDT 阅读C/C++代码
本文转自: https://xbgd.iteye.com/blog/1259544 常见阅读代码的工具有 , visual c++, visual studio + va(visual assista ...
- 阶段3 1.Mybatis_06.使用Mybatis完成DAO层的开发_8 properties标签的使用及细节
properties 可以把数据库链接的配置放在上面的properties里面 #{占位符}的形式去引用上面的.下面的内容就是引用上面的内容的定义. 运行查询的方法测试一下 这样改造可以成功的运行程序 ...
- python学习笔记:(七)dict(字典)常用的方法
字典是通过名称来引用值的数据结构,这种类型的数据结构称为:映射. 字典是python中唯一的内建映射类型. 注意: 1.字典中键必须是唯一的,如果同一个键被赋值两次,会使用后一个值: 2.键必须不可变 ...
- pycharm基础使用方法
0.前言 Pycharm 作为一款针对 Python 的编辑器,配置简单.功能强大.使用起来省时省心,对初学者友好,这也是为什么编程教室一直推荐新手使用 Pycharm 的原因.本文我们将介绍 py ...
- 【Java基础】内部类
非静态内部类不能拥有静态变量 为什么 下面这段代码,如果Lazyholder没有static修饰,则编译不过 class Singleton2 { private static class LazyH ...
- SpringCloud:(一)服务注册与发现
最近跟着方志明老师学习SpringCloud,博客地址如下: https://blog.csdn.net/forezp/article/details/81040925 自己也跟着撸了一遍,纸上得来终 ...
- Java之类的继承
说起来Java的类,不得不说以下几个方面:继承.转型.重写.多态和接口. 今天来说一说继承,转型和重写几个方面: 继承(extends)即子类继承父类,就好比玻璃杯.保温杯等子类继承了杯子这个父类,子 ...