KNN原理小结
K近邻法(K-nearest neighbors,KNN)既可以分类,也可以回归。
KNN做回归和分类的区别在于最后预测时的决策方式。KNN做分类时,一般用多数表决法;KNN做回归时,一般用平均法。
scikit-learn中只使用了蛮力实现(brute-force),KD树(KDTree),球树(BallTree),所以这里只讨论这几种算法。
1. KNN算法三要素
KNN算法主要考虑:k值的选取,距离度量方式,分类决策规则。
当K值较小,训练误差减小,泛化误差增大,模型复杂容易过拟合;当K值较大,泛化误差减小,训练误差增大,模型简单使预测发生错误(一个极端,K等于样本数m,则完全没有分类,此时无论测试集是什么,结果都属于训练集中最多的类)。
距离度量方式:欧式距离,曼哈顿距离,闵可夫斯基距离(欧式距离是闵可夫斯基距离在 p=2 的特例,曼哈顿距离是 p=1 的特例)。
2. KNN算法蛮力实现
计算预测样本和所有训练集中的样本距离,然后计算出最小的K个距离即可,接着多数表决,做出预测。这种方法简单,在样本量少,样本特征少的时候有效。
3. KNN算法之KD树实现原理
KD树就是K个特征维度的树。KNN中的K代表最近的K个样本,KD树中的K代表样本特征的维数。为了防止混淆,后面称特征维数为n。
KD树算法包括3步:第一建树,第二搜索最近邻,第三预测。
3.1 KD树的建立
KD树划分思想:
kd树实质是二叉树,其划分思想与CART树一致,即切分使样本复杂度降低最多的特征。kd树认为特征方差越大,则该特征的复杂度亦越大,优先对该特征进行切分 ,切分点是所有实例在该特征的中位数。重复该切分步骤,直到切分后无样本则终止切分,终止时的样本为叶节点。
具体步骤:
KD树的建立是从 m 个样本中的 n 维特征中,分别计算 n 个特征的取值的方差,用方差最大的第 K 维特征 nk 作为根节点。选择特征 nk 取值的中位数 nkv 对应的样本作为划分点,对于所有第 K 维特征的取值小于 nkv 的样本,划入左子树,对于第 K 维特征的取值大于等于 nkv 的样本,划入右子树,对于左右子树,采用和刚才同样的办法找方差最大的特征来做更节点,递归生成KD树。

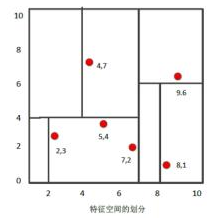
我们有二维样本6个,{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},构建KD树步骤:
- 找到划分的特征。6个数据点在 x,y维度上的数据方差分别为6.97,5.37,所以在 x 轴上方差更大,用第1维特征建树。
- 确定划分点(7,2)。根据根据x维上的值将数据排序,6个数据的中值(所谓中值,即中间大小的值)为7,所以划分点的数据是(7,2)。这样,该节点的分割超平面就是通过(7,2)并垂直于:划分点维度的直线x=7;
- 确定左子空间和右子空间。 分割超平面x=7将整个空间分为两部分:x<=7的部分为左子空间,包含3个节点={(2,3),(5,4),(4,7)};另一部分为右子空间,包含2个节点={(9,6),(8,1)}。
- 用同样的办法划分左子树的节点{(2,3),(5,4),(4,7)}和右子树的节点{(9,6),(8,1)}。最终得到KD树。
KD树(绿色为叶子节点,红色为节点和根节点):
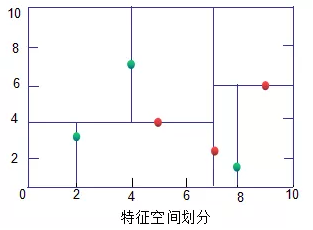
3.2 KD树搜索最近邻
生成KD树后,可以预测测试集里面的样本目标点了。对于每一个目标点,首先在KD树里面找到包含目标点的叶子节点。以目标点为圆心,目标点到叶子节点样本实例的距离为半径,得到一个超球体,最近邻的点一定在这个超球体内部。然后返回叶子节点的父节点,检查另一个子节点包含的超矩形体是否和超球体相交,如果相交就到这个子节点寻找是否有更加近的近邻,有的话更新近邻。如果不想交,直接返回父节点的父节点,在另一个子树继续搜索最近邻。当回溯到根节点时,算法结束。此时保存的最近邻节点就是最终的最近邻。
从上面可以看出,KD树划分后可以大大减少无效的最近邻搜索,很多样本点由于所在的超矩形体和超球体不相交根本不需要计算距离。大大节省计算时间。
用3.1建立的KD树,来看对点(2,4.5)找最近邻的过程。
先进行二叉查找,先从(7,2)查找到(5,4)节点,在进行查找时是由y = 4为分割超平面的,由于查找点为y值为4.5,因此进入右子空间查找到(4,7),形成搜索路径<(7,2),(5,4),(4,7)>,但 (4,7)与目标查找点的距离为3.202,而(5,4)与查找点之间的距离为3.041,所以(5,4)为查询点的最近点; 以(2,4.5)为圆心,以3.041为半径作圆,如下图所示。可见该圆和y = 4超平面交割,所以需要进入(5,4)左子空间进行查找,也就是将(2,3)节点加入搜索路径中得<(7,2),(2,3)>;于是接着搜索至(2,3)叶子节点,(2,3)距离(2,4.5)比(5,4)要近,所以最近邻点更新为(2,3),最近距离更新为1.5;回溯查找至(5,4),直到最后回溯到根结点(7,2)的时候,以(2,4.5)为圆心1.5为半径作圆,并不和x = 7分割超平面交割,如下图所示。至此,搜索路径回溯完,返回最近邻点(2,3),最近距离1.5。
对应的图如下:

3.3 KD树预测
在KD树搜索最近邻的基础上,我们选择到了第一个最近邻样本,就把它置为已选。在第二轮中,我们忽略置为已选的样本,重新选择最近邻,这样跑k次,就得到了目标的K个最近邻,然后根据多数表决法,如果是KNN分类,预测为K个最近邻里面有最多类别数的类别。如果是KNN回归,用K个最近邻样本输出的平均值作为回归预测值。
KNN原理小结的更多相关文章
- K近邻法(KNN)原理小结
K近邻法(k-nearst neighbors,KNN)是一种很基本的机器学习方法了,在我们平常的生活中也会不自主的应用.比如,我们判断一个人的人品,只需要观察他来往最密切的几个人的人品好坏就可以得出 ...
- Bagging与随机森林算法原理小结
在集成学习原理小结中,我们讲到了集成学习有两个流派,一个是boosting派系,它的特点是各个弱学习器之间有依赖关系.另一种是bagging流派,它的特点是各个弱学习器之间没有依赖关系,可以并行拟合. ...
- 梯度提升树(GBDT)原理小结
在集成学习之Adaboost算法原理小结中,我们对Boosting家族的Adaboost算法做了总结,本文就对Boosting家族中另一个重要的算法梯度提升树(Gradient Boosting De ...
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- 机器学习之KNN原理与代码实现
KNN原理与代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/9670187.html 1. KNN原理 K ...
- 梯度提升树(GBDT)原理小结(转载)
在集成学习值Adaboost算法原理和代码小结(转载)中,我们对Boosting家族的Adaboost算法做了总结,本文就对Boosting家族中另一个重要的算法梯度提升树(Gradient Boos ...
- XGBoost算法原理小结
在两年半之前作过梯度提升树(GBDT)原理小结,但是对GBDT的算法库XGBoost没有单独拿出来分析.虽然XGBoost是GBDT的一种高效实现,但是里面也加入了很多独有的思路和方法,值得单独讲一讲 ...
- gc原理小结
一.相关概念 基本回收算法 1. 引用计数(Reference Counting) 比较古老的回收算法.原理是此对象有一个引用,即增加一个计数,删除一个引用则减少一个计数.垃圾回收时,只用收集计数为0 ...
- GBDT(梯度提升树) 原理小结
在之前博客中,我们对Boosting家族的Adaboost算法做了总结,本文就对Boosting家族中另一个重要的算法梯度提升树(Gradient Boosting Decison Tree, 以下简 ...
随机推荐
- Let's write a framework.
Let's write a framework. create a model var model={a:1,b:'b'} let's create a router, router maps url ...
- python之django_form组件笔记
Form字段 Field required=True, 是否允许为空 widget=None, HTML插件 label=None, 用于生成Label标签或显示内容 initial=None, 初始 ...
- HihoCoder1076 与链(数位DP)
时间限制:24000ms 单点时限:3000ms 内存限制:256MB 描述 给定 n 和 k.计算有多少长度为 k 的数组 a1, a2, ..., ak,(0≤ai) 满足: a1 + a2 + ...
- 交互式数据可视化-D3.js(三)比例尺
线性比例尺 线性比例尺是常用比例尺常用方法有: var linear = d3.scaleLinear() - 创建一个定量的线性比例尺. linear.domain([numbers]) - 定义或 ...
- Django—ajax、前端后端编码格式,bulk_create批量插入语数据库、自定义分页
一.ajax简介: XML也是一门标记语言该语法应用场景 1.写配置文件 2.可以写前端页面(odoo框架中 erp) 每家公司都会有属于这家公司独有的内部管理软件:专门用来开发企业内部管理软件 框架 ...
- vue设置全局query参数
router.beforeEach((to, from, next) => { // 设置全局店铺ID shopid const shopid = from.query.shopid // 如果 ...
- 吴恩达+neural-networks-deep-learning+第二周作业
Logistic Regression with a Neural Network mindset v4 简单用logistic实现了猫的识别,logistic可以被看做一个简单的神经网络结构,下面是 ...
- centos7排查swap占用过高
使用free -h 查看发现服务器在可用内存还有91G的情况下,使用Swap分区空间 查看具体是哪进程在占用Swap分区 ###for i in $( cd /proc;ls |grep " ...
- Flink SQL 如何实现数据流的 Join?
无论在 OLAP 还是 OLTP 领域,Join 都是业务常会涉及到且优化规则比较复杂的 SQL 语句.对于离线计算而言,经过数据库领域多年的积累,Join 语义以及实现已经十分成熟,然而对于近年来刚 ...
- 获得 Client 的相关信息
1.获得 Client 的相关信息 package com.shine.sun.small; import java.net.InetAddress; @Slf4j public class netI ...