keras学习笔记-bili莫烦
一、keras的backend设置
有两种方式:
1.修改JSON配置文件
修改~/.keras/keras.json文件内容为:
{
"iamge_dim_ordering":"tf",
"epsilon":1e-07,
"floatx":"float32",
"backend":"tensorflow"
}
官方文档解释:
iamge_data_format:字符串,"channels_last"或"channels_first",该选项指定了Keras将要使用的维度顺序,可通过keras.backend.image_data_format()来获取当前的维度顺序。对2D数据来说,"channels_last"假定维度顺序为(rows,cols,channels)而"channels_first"假定维度顺序为(channels, rows, cols)。对3D数据而言,"channels_last"假定(conv_dim1, conv_dim2, conv_dim3, channels),"channels_first"则是(channels, conv_dim1, conv_dim2, conv_dim3)epsilon:浮点数,防止除0错误的小数字floatx:字符串,"float16","float32","float64"之一,为浮点数精度backend:字符串,所使用的后端,为"tensorflow"或"theano"
2.修改python环境变量中的 KERAS_BACKEND参数值
import os
os.environ["KERAS_BACKEND"]="tensorflow"
在这种情况下,效果只是临时的,但可以总是写在代码的最前面,同样可以达到目的。
二、使用keras实现线性回归
import numpy as np
import matplotlib.pyplot as plt # 按顺序建立的model结构
from keras.models import Sequential
# Dense是全连接层
from keras.layers import Dense # seed给定一个种子,利用同一个种子生成的随机数每次都相同
np.random.seed(1337) # 从-1到1生成200个均间距数
X = np.linspace(-1, 1, 200)
# 打乱数据
np.random.shuffle(X)
# 生成Y,并添加随机噪声
Y = 0.5 * X + 2 + np.random.normal(0, 0.05, (200,))
# 画散点图
plt.scatter(X, Y)
plt.show()
# XY的前160个数据作为训练数据,后40个数据作为测试数据
X_train, Y_train = X[:160], Y[:160]
X_test, Y_test = X[160:], Y[160:] # 开始使用Keras创建网络结构
model = Sequential()
# 添加一个全连接层,该层的输入维度是1,输出维度也是1。
model.add(Dense(output_dim=1, input_dim=1)) # 设置选择的损失函数,还有优化器
model.compile(loss='mse', optimizer='sgd') # 开始训练
print("Training ----------")
for step in range(301):
# 每次迭代都使用全部的训练集
cost = model.train_on_batch(X_train, Y_train)
if step % 50 == 0:
print("Train cost:", cost) # 开始测试
print("Testing -----------")
cost = model.evaluate(X_test, Y_test, batch_size=40)
print("Test cost:", cost)
W, b = model.layers[0].get_weights()
print("Weights=", W, "\nBiases=", b) # 画出在测试集上的拟合情况
Y_predict = model.predict(X_test)
# 画出测试集的散点图
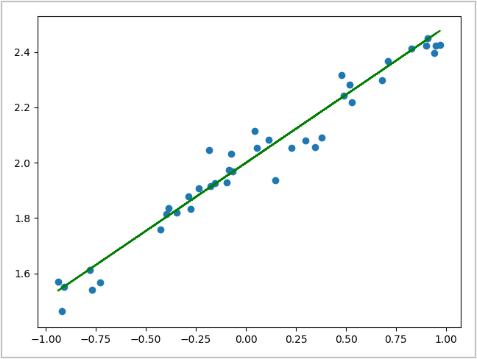
plt.scatter(X_test, Y_test)
# 画出预测值对应的直线,颜色为红色
plt.plot(X_test, Y_predict, color='g')
plt.show()
三、使用keras给mnist分类
# 解决报错GPU运行报错的问题
# 这里导入tf,用来修改tf后端的配置
import tensorflow as tf
from keras.backend.tensorflow_backend import set_session config = tf.ConfigProto()
# 将显存容量调到只会使用30%
config.gpu_options.per_process_gpu_memory_fraction = 0.3
# 使用设置好的配置
set_session(tf.Session(config=config)) import numpy as np np.random.seed(1337)
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
# 导入全连接层和激活函数
from keras.layers import Dense, Activation
# 导入优化器RMSprop
from keras.optimizers import RMSprop (X_train, y_train), (X_test, y_test) = mnist.load_data()
print(X_train.shape[0])
print(X_test.shape[0])
# 将数据由原本的shape-(60000,28,28)变为(60000,784),然后将数据缩放到0-1之间
X_train = X_train.reshape(X_train.shape[0], -1) / 255
X_test = X_test.reshape(X_test.shape[0], -1) / 255
# 将标签数据变换为onehot模式,原本是用10进制数来表示的
y_train = np_utils.to_categorical(y_train)
print(y_test)
y_test = np_utils.to_categorical(y_test)
print(y_test) # 可以在model中将各层放在一个列表中
model = Sequential([
# 第一个全连接层,输入784,输出32
Dense(output_dim=32, input_dim=784),
Activation('relu'),
# 不设置input_dim,会默认使用上一层的output_dim
Dense(10),
Activation('softmax'),
])
# 这样也可以
# model = Sequential()
# model.add(Dense(32,input_dim=784))
# model.add(Activation('relu'))
# model.add(Dense(10))
# model.add(Activation('softmax')) # 自己定义RMSprop
rmsprop = RMSprop(lr=0.001, rho=0.9, epsilon=1e-08, decay=0.0) # 开始创建网络,使用我们自己定义的rmsprop,如果想使用默认的RMSprop也可是使用
# optimizer = 'rmsprop'来指定。
model.compile(optimizer=rmsprop,
# 使用交叉熵损失函数
loss='categorical_crossentropy',
# 指定在过程中需要额外计算的东西
metrics=['accuracy']
) # 开始训练
print('Training ----------')
# 使用fit来进行训练,epochs指训练几轮,一轮就是train的全部数据,这里是60000
# 这里一个epochs可以训练60000/32=1875轮,epochs=2,则一共训练3750轮
# batch_size=32指每训练一轮用多少数据,这个在显存能放得下的情况下,越大越好
model.fit(X_train, y_train, epochs=1, batch_size=32) # 开始测试
print('\nTesting ----------')
loss, accuracy = model.evaluate(X_test, y_test) print('test loss:', loss)
print('test accuracy:', accuracy)
注意前面GPU报错的处理办法。
四、使用keras的卷积网络对mnist分类
# -*- coding:utf-8 -*-
__author__ = 'Leo.Z' # 解决报错GPU运行报错的问题
# 这里导入tf,用来修改tf后端的配置
import tensorflow as tf
from keras.backend.tensorflow_backend import set_session
config = tf.ConfigProto()
# 将显存容量调到只会使用30%
config.gpu_options.per_process_gpu_memory_fraction = 0.3
# 使用设置好的配置
set_session(tf.Session(config=config)) import numpy as np np.random.seed(1337)
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dense, Activation, Convolution2D, MaxPooling2D, Flatten
from keras.optimizers import Adam (X_train, y_train), (X_test, y_test) = mnist.load_data() # 改变结构,-1表示默认的样本数,1表示channels这里是灰度图片,28*28表示图片大小
# 卷积网络要使用图片的格式
X_train = X_train.reshape(-1, 1, 28, 28)
X_test = X_test.reshape(-1, 1, 28, 28)
# 将标签变换为onehot格式
y_train = np_utils.to_categorical(y_train, num_classes=10)
y_test = np_utils.to_categorical(y_test, num_classes=10) model = Sequential()
# 添加第一个卷积层,32个核,核尺寸为5*5,步长为1,填充为same,激活函数为relu,输入为1*28*28
model.add(Convolution2D(
filters=32,
kernel_size=(5, 5),
strides=1,
padding='same',
activation='relu',
input_shape=(1, 28, 28)
))
# 添加一个pool层,类型为Maxpooling,核尺寸为2*2,步长为2,填充为same
model.add(MaxPooling2D(
pool_size=(2, 2),
strides=2,
padding='same'
))
# 添加第二个卷积层,64个核,大小为5*5,填充为same,激活函数为relu
model.add(Convolution2D(
filters=64,
kernel_size=(5, 5),
padding='same',
activation='relu',
))
# 添加Maxpooling层,尺寸为2*2,填充为same
model.add(MaxPooling2D(
pool_size=(2, 2),
strides=2,
padding='same'
))
# 将得到的卷积层给抹平,然后提供给全连接层
model.add(Flatten())
# 添加一个全连接层,node为1024(输出为1024)
model.add(Dense(1024))
# 给第一个全连接层加一个激活函数relu
model.add(Activation("relu"))
# 添加第二个全连接层,node为10(输出为10)
model.add(Dense(10))
# 为第二个全连接层添加激活函数softmax作分类输出
model.add(Activation("softmax")) # 使用adam优化器
adam = Adam(lr=1e-4) # 创建网络,使用交叉熵损失函数,输出accuracy
model.compile(optimizer=adam,
loss='categorical_crossentropy',
metrics=['accuracy']) # 开始训练,每个batch为32,跑一个epoch
print("Training ----------")
model.fit(X_train, y_train, epochs=1, batch_size=32)
# 开始测试,输出损失值和准确度
print("Testing ----------")
loss, accuracy = model.evaluate(X_test, y_test) print("Loss:", loss)
print("Accuracy:", accuracy)
五、使用RNN来分类Mnist
# -*- coding:utf-8 -*-
__author__ = 'Leo.Z' # 解决报错GPU运行报错的问题
# 这里导入tf,用来修改tf后端的配置
import tensorflow as tf
from keras.backend.tensorflow_backend import set_session config = tf.ConfigProto()
# 将显存容量调到只会使用30%
config.gpu_options.per_process_gpu_memory_fraction = 0.3
# 使用设置好的配置
set_session(tf.Session(config=config)) import numpy as np np.random.seed(1337) from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import SimpleRNN, Activation, Dense
from keras.optimizers import Adam # 一个图片28行,我们看作是28个时间点
TIME_STEP = 28
# 输入大小,就是每一行的像素点个数
INPUT_SIZE = 28
# 每一轮训练的样本数(图片个数)
BATCH_SIZE = 50
BATCH_INDEX = 0
# 输出维度10
OUTPUT_SIZE = 10
# RNN单元中node个个数
CELL_SIZE = 50
# 学习率为0.001
LR = 0.001 # 读取数据
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 数据预处理
# 将训练数据和测试数据都转换为 m*28*28,并且归一化
X_train = X_train.reshape(-1, 28, 28) / 255
X_test = X_test.reshape(-1, 28, 28) / 255
y_train = np_utils.to_categorical(y_train, num_classes=10)
y_test = np_utils.to_categorical(y_test, num_classes=10) model = Sequential() model.add(SimpleRNN(
# 输入一个batch的shape为50*28*28
# 当使用batch_input_shape规定了batch大小后,测试时会要求满足这个大小
#batch_input_shape=(BATCH_SIZE, TIME_STEP, INPUT_SIZE),
# 选择使用input_shape,从而不影响测试时输入大小
input_shape=(TIME_STEP, INPUT_SIZE),
units=CELL_SIZE,
# tanh也是默认值
activation='tanh'
))
# 定义输出层,输出为10
model.add(Dense(OUTPUT_SIZE))
model.add(Activation('softmax')) adam = Adam(LR) model.compile(optimizer=adam,
loss='categorical_crossentropy',
metrics=['accuracy']) for step in range(4001):
# 每次获取一个batch_size的数据集
X_batch = X_train[BATCH_INDEX:BATCH_INDEX + BATCH_SIZE, :, :]
y_batch = y_train[BATCH_INDEX:BATCH_INDEX + BATCH_SIZE, :]
# 训练一次,返回cost
cost = model.train_on_batch(X_batch, y_batch)
BATCH_INDEX += BATCH_SIZE
# 如果训练集跑完了一轮,将BATCH_INDEX置0,继续跑
BATCH_INDEX = 0 if BATCH_INDEX >= X_train.shape[0] else BATCH_INDEX
# 每500测试一次,打印一次cost和accuracy
if step % 500 == 0:
cost, accuracy = model.evaluate(X_test, y_test, batch_size=10000, verbose=False)
print("Cost:", cost, "Accuracy:", accuracy)
六、使用LSTM来进行回归
# -*- coding:utf-8 -*-
__author__ = 'Leo.Z' # 解决报错GPU运行报错的问题
# 这里导入tf,用来修改tf后端的配置
import tensorflow as tf
from keras.backend.tensorflow_backend import set_session config = tf.ConfigProto()
# 将显存容量调到只会使用30%
config.gpu_options.per_process_gpu_memory_fraction = 0.3
# 使用设置好的配置
set_session(tf.Session(config=config)) import numpy as np np.random.seed(1337) from keras.models import Sequential
from keras.layers import LSTM, TimeDistributed, Dense
from keras.optimizers import Adam
import matplotlib.pyplot as plt BATCH_START = 0
# 每次20个数据为一个序列
TIME_STEPS = 20
# 一个批次为50个序列
BATCH_SIZE = 50
# 每个输入为1,一个sin的值
INPUT_SIZE = 1
# 每个输出也为1,一个cos的值
OUTPUT_SIZE = 1
# RNN循环单元中node个数量
CELL_SIZE = 20
# 学习率为0.006
LR = 0.006 # 准备数据,每次获取一个batch的数据,每个batch中的sin和cos是连续的
def get_batch():
global BATCH_START, TIME_STEPS
# 每一次batch对应X轴的数据,转化为50*20
xs = np.arange(BATCH_START, BATCH_START + TIME_STEPS * BATCH_SIZE).reshape((BATCH_SIZE, TIME_STEPS))
# X对应的sin数据,50*20
seq = np.sin(xs)
# X对应的cos数据,50*20
res = np.cos(xs)
BATCH_START += TIME_STEPS # plt.plot(xs[0,:],res[0,:],'r',xs[0,:],seq[0,:],'b--')
# plt.show() # 返回数据,格式为[50*20*1,50*20*1,50]
return [seq[:, :, np.newaxis], res[:, :, np.newaxis], xs] model = Sequential() model.add(LSTM(
batch_input_shape=(BATCH_SIZE, TIME_STEPS, INPUT_SIZE),
units=CELL_SIZE,
# 是否在RNN的每次循环中都做输入,默认是False,即只在最后输出结果
return_sequences=True,
# 两次batch之间是否是有联系的,即第一个batch的最后一部的输出a是否作为第二个batch的第一个输入
stateful=True
))
# 按时间分割的全链接,即对RNN的每一次循环都添加一个全连接进行输出,输出维度为1。
model.add(TimeDistributed(Dense(OUTPUT_SIZE))) adam = Adam(LR) model.compile(optimizer=adam,
loss='mse') print("Train ----------")
# 使用plt.ion开启交互模式
plt.ion() for step in range(501):
X_batch, y_batch, xs = get_batch()
cost = model.train_on_batch(X_batch, y_batch)
pred = model.predict(X_batch, BATCH_SIZE) # 避免在图中重复的画线,线尝试删除已经存在的线
try:
# 每次画图之前清空前面的图形,不然就是累加
plt.clf()
except Exception:
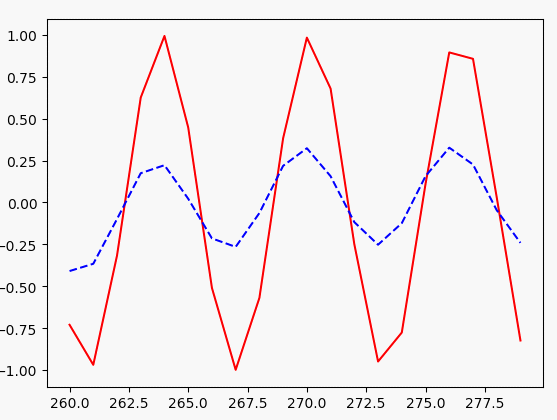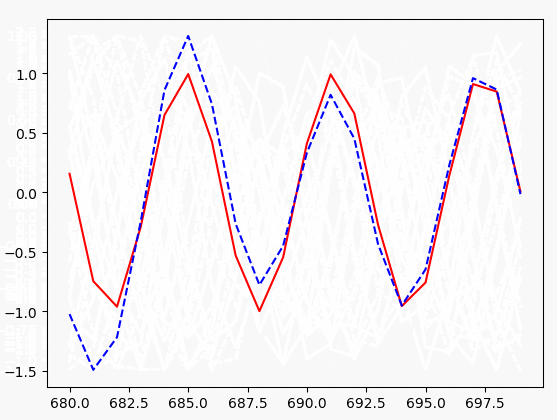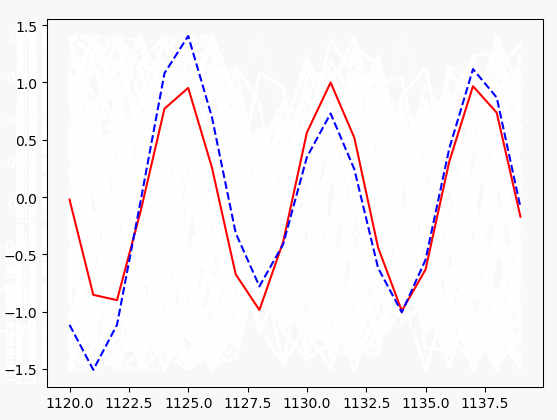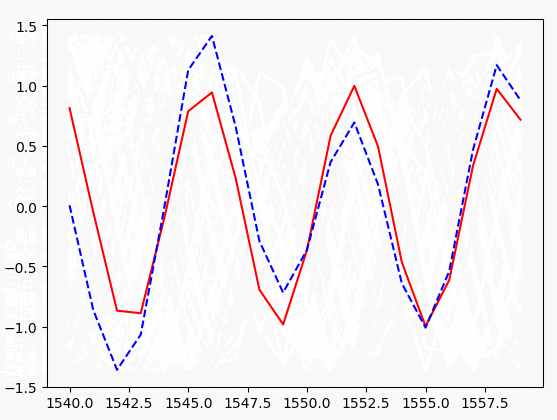
pass plt.plot(xs[0, :], y_batch[0].flatten(), 'r', xs[0, :], pred.flatten()[:TIME_STEPS], 'b--')
# 暂停一下,否则会卡
plt.pause(0.1)
if step % 10 == 0:
print('tiran cost: ', cost)
七、使用keras实现自编码(autoencoder)
# -*- coding:utf-8 -*-
__author__ = 'Leo.Z' # 解决报错GPU运行报错的问题
# 这里导入tf,用来修改tf后端的配置
import tensorflow as tf
from keras.backend.tensorflow_backend import set_session config = tf.ConfigProto()
# 将显存容量调到只会使用30%
config.gpu_options.per_process_gpu_memory_fraction = 0.3
# 使用设置好的配置
set_session(tf.Session(config=config)) import numpy as np np.random.seed(1337) import matplotlib.pyplot as plt
from keras.datasets import mnist
# 这里直接使用Model,而没有使用Sequential
from keras.models import Model
from keras.layers import Dense, Input # 导入matplotlib中的3D模块
from mpl_toolkits import mplot3d # 导入数据,但在这个例子中,由于自编码是属于无监督,所以只需要X_train和X_test
# y_test主要用于最后画3D图时用作颜色区分
(X_train, _), (X_test, y_test) = mnist.load_data() # 预处理数据,将数据全部归一化为[-0.5,0.5]范围
X_train = X_train.astype('float32') / 255. - 0.5
X_train = X_train.reshape((X_train.shape[0], -1))
X_test = X_test.astype('float32') / 255. - 0.5
X_test = X_test.reshape((X_test.shape[0], -1)) # 我们确定将encoder的输出维度定为3(画3D图)
encoding_dim = 3 # 定义输入
input_img = Input(shape=(784,)) # 定义encoder部分
encoded = Dense(128, activation='relu')(input_img)
encoded = Dense(64, activation='relu')(encoded)
encoded = Dense(10, activation='relu')(encoded)
encoder_output = Dense(encoding_dim, )(encoded) # 定义decoder部分
decoded = Dense(10, activation='relu')(encoder_output)
decoded = Dense(64, activation='relu')(decoded)
decoded = Dense(128, activation='relu')(decoded)
decoded = Dense(784, activation='tanh')(decoded) # 自编码整体结构
autoencoder = Model(inputs=input_img, outputs=decoded)
# 仅编码部分
encoder = Model(inputs=input_img, outputs=encoder_output) # 构建
autoencoder.compile(optimizer='adam', loss='mse')
# 训练20epochs,每个batch为256,并打乱顺序
autoencoder.fit(X_train, X_train, epochs=20, batch_size=256, shuffle=True) # 使用仅编码部分结构来进行预测,即生成编码后的3维数据
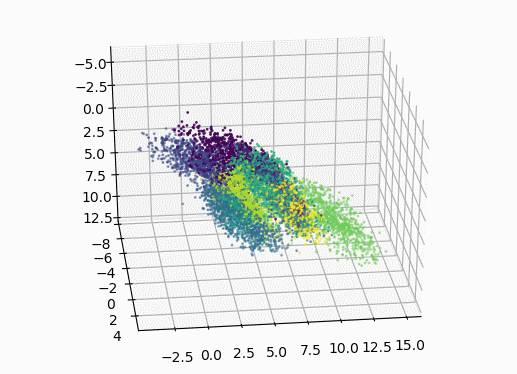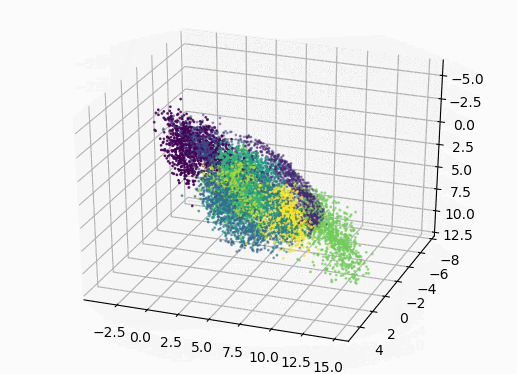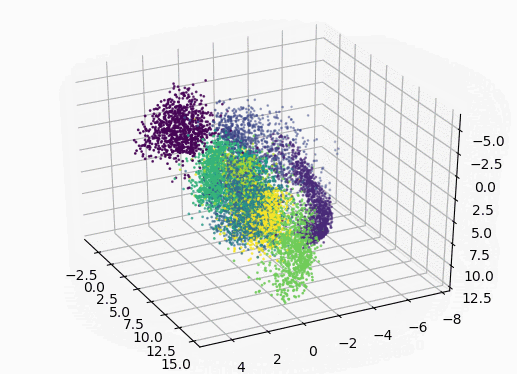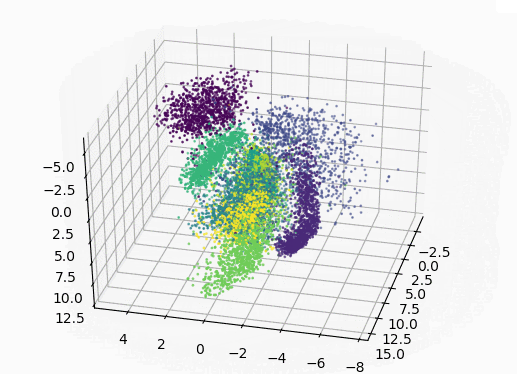
encoded_img = encoder.predict(X_test[1000:]) # 使用3D绘图
ax = plt.axes(projection='3d')
# 画3D图(只画了X_test中的前1000个点,避免卡)
ax.scatter3D(encoded_img[:, 0], encoded_img[:, 1], encoded_img[:, 2], c=y_test[1000:], s=1)
plt.show()
八、模型保存和载入
from keras.models import Sequential
from keras.models import load_model # 直接保存整个model
# 使用HDF5格式保存需要安装h5py包
model.save('my_model.h5')
# 载入整个model
model = load_model('my_model.h5') # 只保存weights
model.save_weights('my_model_weights.h5')
model.load_weights('my_model_weights.h5') # 只保存网络结构
from keras.models import model_from_json
json_string = model.to_json()
model = model_from_json(json_string)
keras学习笔记-bili莫烦的更多相关文章
- tensorflow学习笔记-bili莫烦
bilibili莫烦tensorflow视频教程学习笔记 1.初次使用Tensorflow实现一元线性回归 # 屏蔽警告 import os os.environ[' import numpy as ...
- scikit-learn学习笔记-bili莫烦
bilibili莫烦scikit-learn视频学习笔记 1.使用KNN对iris数据分类 from sklearn import datasets from sklearn.model_select ...
- 官网实例详解-目录和实例简介-keras学习笔记四
官网实例详解-目录和实例简介-keras学习笔记四 2018-06-11 10:36:18 wyx100 阅读数 4193更多 分类专栏: 人工智能 python 深度学习 keras 版权声明: ...
- Keras学习笔记——Hello Keras
最近几年,随着AlphaGo的崛起,深度学习开始出现在各个领域,比如无人车.图像识别.物体检测.推荐系统.语音识别.聊天问答等等.因此具备深度学习的知识并能应用实践,已经成为很多开发者包括博主本人的下 ...
- Keras学习笔记
Keras基于Tensorflow和Theano.作为一个更高级的框架,用其编写网络更加方便.具体流程为根据设想的网络结构,使用函数式模型API逐层构建网络即可,每一层的结构都是一个函数,上一层的输出 ...
- Keras学习笔记(完结)
使用Keras中文文档学习 基本概念 Keras的核心数据结构是模型,也就是一种组织网络层的方式,最主要的是序贯模型(Sequential).创建好一个模型后就可以用add()向里面添加层.模型搭建完 ...
- Keras学习笔记1--基本入门
""" 1.30s上手keras """ #keras的核心数据结构是“模型”,模型是一种组织网络层的方式,keras 的主要模型是Sequ ...
- keras 学习笔记:从头开始构建网络处理 mnist
全文参考 < 基于 python 的深度学习实战> import numpy as np from keras.datasets import mnist from keras.model ...
- Keras学习笔记二:保存本地模型和调用本地模型
使用深度学习模型时当然希望可以保存下训练好的模型,需要的时候直接调用,不再重新训练 一.保存模型到本地 以mnist数据集下的AutoEncoder 去噪为例.添加: file_path=" ...
随机推荐
- TensorFlow基础总结
1.基础概念 Tensor:类型化的多维数组,图的边:Tensor所引用的并不持有具体的值,而是保持一个计算过程,可以使用session.run()或者t.eval()对tensor的值进行计算. O ...
- Vue中使用fullpage.js
Vue中使用fullpage.js:https://blog.csdn.net/weixin_34184158/article/details/88672739
- 洛谷 P2796 Facer的程序 题解
题面 一个树形DP, f[i]=表示以i为根可以得到的子树个数: 则f[i]*=(f[j]+1): 初始化f[i]=1; ans=sigma(f[i]); #include <bits/stdc ...
- chrome://inspect 白屏BUG解决方案
chrome://inspect 是前端常用的调试工具但是有时候会碰到PC端dev-tools白屏的问题 1.首先我们要处于[科][学]的网络环境 2.在 chrome 中输入chrome://app ...
- python-2:爬取某个网页(虎扑)帖子的标题做词云图
关键词:requests,BeautifulSoup,jieba,wordcloud 整体思路:通过requests请求获得html,然后BeautifulSoup解析html获得一些关键数据,之后通 ...
- PostgreSQL-优化之分表
分表概述 数据库分表,就是把一张表分成多张表,物理上虽然分开了,逻辑上彼此仍有联系. 分表有两种方式:水平分表,即按列分开:垂直分表,即按行分开 优势 1. 查询速度大幅提升 2. 删除数据速度更快 ...
- HDU 1789 Doing Homework again(排序,DP)
Doing Homework again Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Oth ...
- npm学习(十)之如何使用创建、发布、使用作用域包
前言 要求npm版本2或更高 作用域用于将相关包分组在一起,并为npm模块创建一个名称空间(类似于域).这里有更详细的解释. 如果一个包的名称以@开头,那么它就是一个有作用域的包.范围是@和斜杠之间的 ...
- 断言(assert)
断言是编程术语,表示为一些布尔表达式,程序员相信在程序中的某个特定点该表达式值为真,可以在任何时候启用和禁用断言验证,因此可以在测试时启用断言而在部署时禁用断言. 简单点说,断言指的就是,将结果判断说 ...
- last, lastb - 显示最近登录的用户列表
总览 last [-R] [-num] [ -n num ] [-adiox] [ -f file ] [name...] [tty...] lastb [-R] [-num] [ -n num ] ...