【机器学习】聚类算法:层次聚类、K-means聚类
聚类算法实践(一)——层次聚类、K-means聚类
|
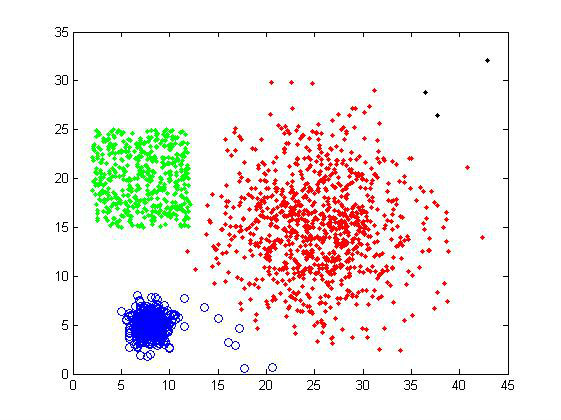
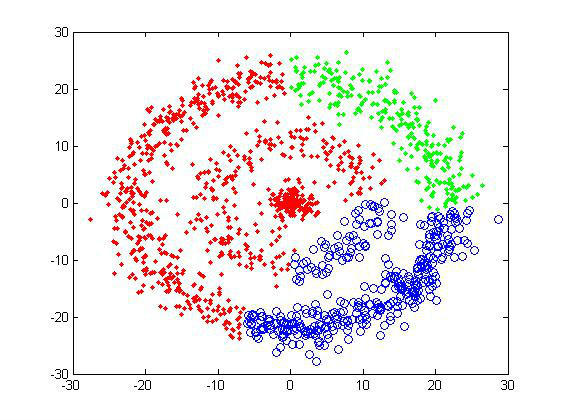
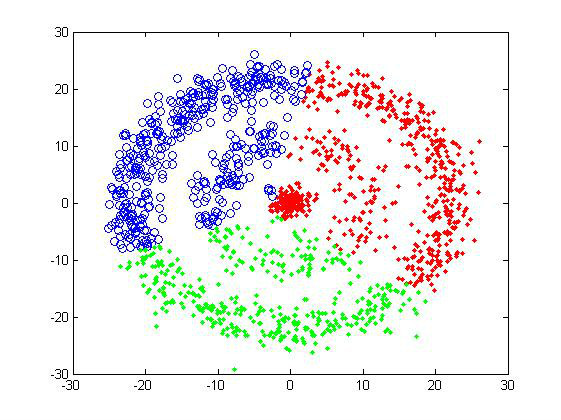
所谓聚类,就是将相似的事物聚集在一 起,而将不相似的事物划分到不同的类别的过程,是数据分析之中十分重要的一种手段。比如古典生物学之中,人们通过物种的形貌特征将其分门别类,可以说就是 一种朴素的人工聚类。如此,我们就可以将世界上纷繁复杂的信息,简化为少数方便人们理解的类别,可以说是人类认知这个世界的最基本方式之一。 在数据分析的术语之中,聚类和分类是两种技术。分类是指我们已经知道了事物的类别,需要从样品中学习分类的规则,是一种有指导学习;而聚类则是由我们来给定简单的规则,从而得到分类,是一种无指导学习。两者可以说是相反的过程。 网上关于聚类算法的资料很多,但是其实大都是几种最基本的方法,如K-means、层次聚类、SOM等,以及它们的许许多多的改进变种。这里,我就来讨论一下这些聚类算法,对它们的表现做一个简单的评估。因为内容有点多(其实主要是图占位置……),所以准备分几次来完成。 基本测试 0、测试数据集 在介绍这些算法之前,这里先给出两个简单的测试样品组,下面每介绍完一个算法,可以直接看看它对这两个样品组的聚类结果,从而得到最直观的认识。 下图就是两个简单的二维样品组: 1)第一组样品属于最基本的聚类测试,界线还是比较分明的,不过三个cluster的大小有较明显差异,可以测试一下算法对cluster size的敏感度。样品总共有2000个数据点 2)第二组是典型的甜甜圈形。使用这样的测试组主要是为了考察算法对cluster形状敏感度。共有1500个数据点。
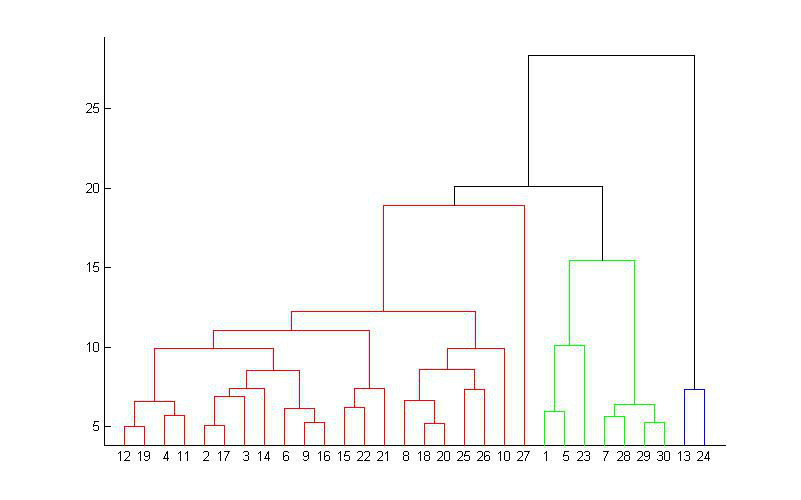
对于这样的两个样品组,人类凭肉眼可以很容易地判断它们应该分为三个cluster(特别是我还用颜色做了区分……),但对于计算机就不一定了,所以就需要有足够优秀的聚类算法。 1、相似性度量 对于聚类,关键的一步是要告诉计算机怎样计算两个数据点的“相似性”,不同的算法需要的“相似性”是不一样的。 比如像以上两组样品,给出了每个数据点的空间坐标,我们就可以用数据点之间的欧式距离来判断,距离越近,数据点可以认为越“相似”。当然,也可以用其它的度量方式,这跟所涉及的具体问题有关。 2、层次聚类 层次聚类,是一种很直观的算法。顾名思义就是要一层一层地进行聚类,可以从下而上地把小的cluster合并聚集,也可以从上而下地将大的cluster进行分割。似乎一般用得比较多的是从下而上地聚集,因此这里我就只介绍这一种。 所谓从下而上地合并cluster,具体而言,就是每次找到距离最短的两个cluster,然后进行合并成一个大的cluster,直到全部合并为一个cluster。整个过程就是建立一个树结构,类似于下图。
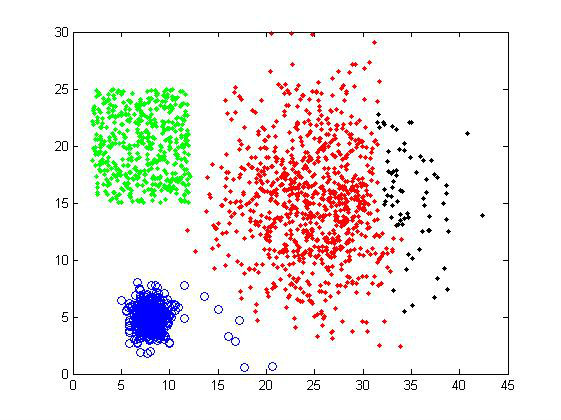
那 么,如何判断两个cluster之间的距离呢?一开始每个数据点独自作为一个类,它们的距离就是这两个点之间的距离。而对于包含不止一个数据点的 cluster,就可以选择多种方法了。最常用的,就是average-linkage,即计算两个cluster各自数据点的两两距离的平均值。类似的 还有single-linkage/complete-linkage,选择两个cluster中距离最短/最长的一对数据点的距离作为类的距离。个人经 层 次聚类最大的优点,就是它一次性地得到了整个聚类的过程,只要得到了上面那样的聚类树,想要分多少个cluster都可以直接根据树结构来得到结果,改变 cluster数目不需要再次计算数据点的归属。层次聚类的缺点是计算量比较大,因为要每次都要计算多个cluster内所有数据点的两两距离。另外,由 于层次聚类使用的是贪心算法,得到的显然只是局域最优,不一定就是全局最优,这可以通过加入随机效应解决,这就是另外的问题了。 聚类结果 对样品组1使用average-linkage,选择聚类数目为4,可以得到下面的结果。右上方的一些异常点被独立地分为一类,而其余的数据点的分类基本符合我们的预期。
如果选择聚类数目为5,则是下面的结果。其中一个大的cluster被分割,但没有出现均匀分割的情况(比如K-means),只有少量的数据点被分离,大体的分类还是比较正确的。因此这个算法可以处理大小差别比较大的聚类问题,对cluster size不太敏感。
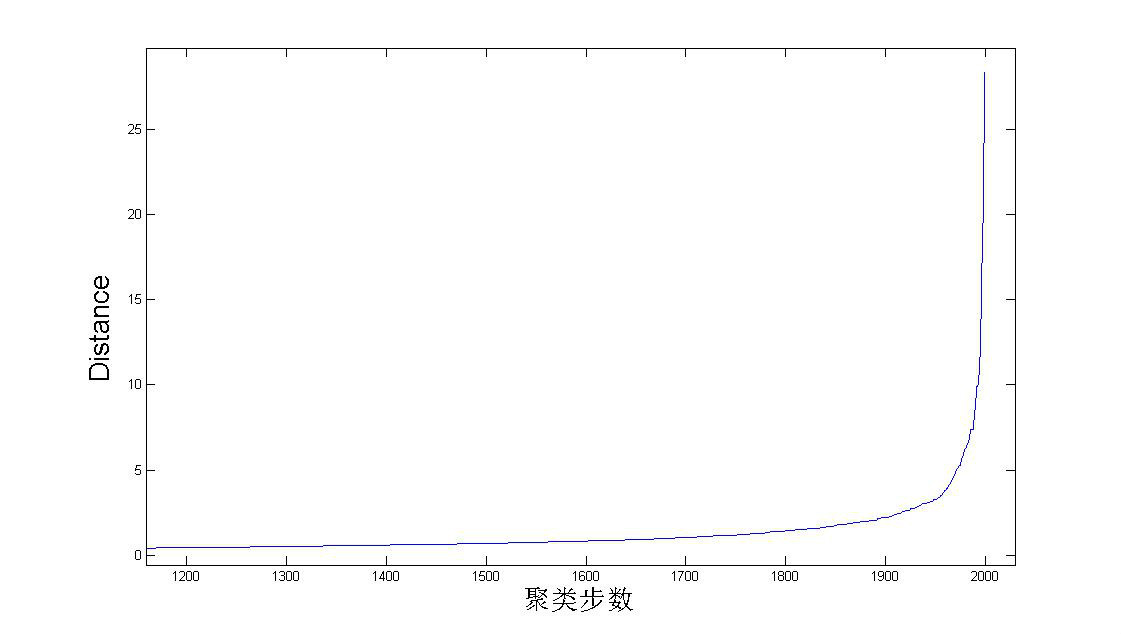
如 何确定应该取多少个cluster?这是聚类里面的一个非常重要的问题。对于层次聚类,可以根据聚类过程中,每次合并的两个cluster的距离来作大概 判断,如下图。因为总共有2000个数据点,每次合并两个cluster,所以总共要做2000次合并。从图中可以看到在后期合并的两个cluster的 距离会有一个陡增。假如数据的分类是十分显然的,就是应该被分为K个大的cluster,K个cluster之间有明显的间隙。那么如果合并的两个小
对于测试样品2,average-linkage可谓完全失效,这是由于它对“相似性”的理解造成的,所以只能得到凸型的cluster。
总体而言,像average-linkage这样的算法还是比较稳定的,可以大致地判断聚类数目,聚类效果也不错,在数据量比较小的时候可以使用。 3、K-means算法 K-means是最为常用的聚类方法之一,尽管它有着很多不足,但是它有着一个很关键的优点:快!K-means的计算复杂度只有O(tkn),t是迭代次数,k是设定的聚类数目,而n是数据量,相比起很多其它算法,K-means算是比较高效的。 K-means的目标是要将数据点划分为k个cluster,找到这每个cluster的中心,并且最小化函数
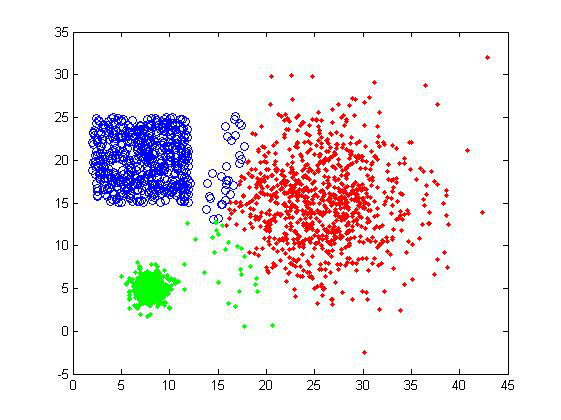
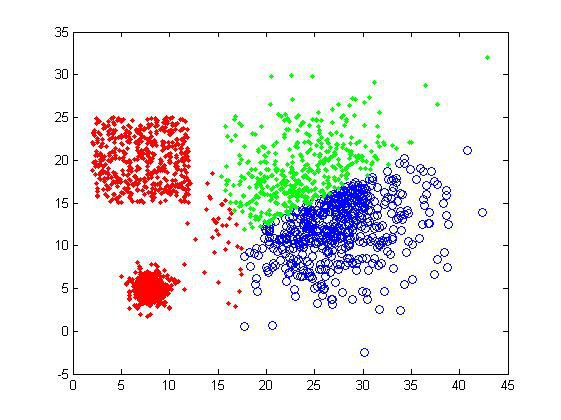
其中 为了得到每个cluster的中心,K-means迭代地进行两步操作。首先随机地给出k个中心的位置,然后把每个数据点归类到离它最近的中心,这样我们就构造了k个cluster。但是,这k个中心的位置显然是不正确的,所以要把中心转移到得到的cluster内部的数据点的平均位置。实际上也就是计算,在每个数据点的归类确定的情况下,上面函数取极值的位置,然后再次构造新的k个cluster。这个过程中,中心点的位置不断地改变,构造出来的cluster的也在变化(动画请看这里)。通过多次的迭代,这k个中心最终会收敛并不再移动。 K-means实际上是EM算法的一个特例(关于EM算法,请猛击这里和这里),根据中心点决定数据点归属是expectation,而根据构造出来的cluster更新中心则是maximization。理解了K-means,也就顺带了解了基本的EM算法思路。 实际应用里,人们指出了很多K-means的不足。比如需要用户事先给出聚类数目k,而这个往往是很难判断的;又如K-means得到的是局域最优,跟初始给定的中心值有关,所以往往要尝试多个初始值;总是倾向于得到大小接近的凸型cluster等等。 K- means算法相比起上面提到的层次聚类,还有一个很大的不同,那就是它需要数据点的坐标,因为它必须要求取平均,而层次聚类实际上并不需要坐标数据,只 需要知道数据点之间的距离而已。这也就是说K-means只适用于使用欧氏距离来计算数据点相似性的情况,因为如果采用非欧距离,那么也不能通过简单的平 均来得到cluster中心。 聚类结果 取 k=3,K-means对样品组1聚类得到下面两张图。为什么是两张图呢?正如前面所说,K-means的聚类结果跟初始中心选择有关,而不是所以的初始 值都能保证聚类成功的,下面第二张就是失败的例子。另外由于K-means总倾向于得到接近大小的cluster,所以可以看到两个小的cluster对 大cluster的“入侵”。
对甜甜圈样品组,K-means也是完全没辙。
从 上面的结果可以看出,K-means的聚类效果确实不是很好。用户如果选择了不正确的聚类数目,会使得本应同一个cluster的数据被判定为属于两个大 的类别,这是我们不想看到的。因为需要数据点的坐标,这个方法的适用性也受到限制。但是效率是它的一个优势,在数据量大或者对聚类结果要求不是太高的情况 下,可以采用K-means算法来计算,也可以在实验初期用来做测试看看数据集的大致情况。 |


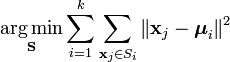
【机器学习】聚类算法:层次聚类、K-means聚类的更多相关文章
- ML: 聚类算法R包-K中心点聚类
K-medodis与K-means比较相似,但是K-medoids和K-means是有区别的,不一样的地方在于中心点的选取,在K-means中,我们将中心点取为当前cluster中所有数据点的平均值, ...
- Python聚类算法之基本K均值实例详解
Python聚类算法之基本K均值实例详解 本文实例讲述了Python聚类算法之基本K均值运算技巧.分享给大家供大家参考,具体如下: 基本K均值 :选择 K 个初始质心,其中 K 是用户指定的参数,即所 ...
- 机器学习算法总结(五)——聚类算法(K-means,密度聚类,层次聚类)
本文介绍无监督学习算法,无监督学习是在样本的标签未知的情况下,根据样本的内在规律对样本进行分类,常见的无监督学习就是聚类算法. 在监督学习中我们常根据模型的误差来衡量模型的好坏,通过优化损失函数来改善 ...
- 【Python机器学习实战】聚类算法(1)——K-Means聚类
实战部分主要针对某一具体算法对其原理进行较为详细的介绍,然后进行简单地实现(可能对算法性能考虑欠缺),这一部分主要介绍一些常见的一些聚类算法. K-means聚类算法 0.聚类算法算法简介 聚类算法算 ...
- 机器学习之路:python k均值聚类 KMeans 手写数字
python3 学习使用api 使用了网上的数据集,我把他下载到了本地 可以到我的git中下载数据集: https://github.com/linyi0604/MachineLearning 代码: ...
- 模式识别之聚类算法k-均值---k-均值聚类算法c实现
//写个简单的先练习一下,测试通过 //k-均值聚类算法C语言版 #include <stdlib.h> #include <stdio.h> #inc ...
- 机器学习理论与实战(十)K均值聚类和二分K均值聚类
接下来就要说下无监督机器学习方法,所谓无监督机器学习前面也说过,就是没有标签的情况,对样本数据进行聚类分析.关联性分析等.主要包括K均值聚类(K-means clustering)和关联分析,这两大类 ...
- 【Python机器学习实战】聚类算法(2)——层次聚类(HAC)和DBSCAN
层次聚类和DBSCAN 前面说到K-means聚类算法,K-Means聚类是一种分散性聚类算法,本节主要是基于数据结构的聚类算法--层次聚类和基于密度的聚类算法--DBSCAN两种算法. 1.层次聚类 ...
- Mahout机器学习平台之聚类算法具体剖析(含实例分析)
第一部分: 学习Mahout必需要知道的资料查找技能: 学会查官方帮助文档: 解压用于安装文件(mahout-distribution-0.6.tar.gz),找到例如以下位置.我将该文件解压到win ...
- 机器学习实战(Machine Learning in Action)学习笔记————06.k-均值聚类算法(kMeans)学习笔记
机器学习实战(Machine Learning in Action)学习笔记————06.k-均值聚类算法(kMeans)学习笔记 关键字:k-均值.kMeans.聚类.非监督学习作者:米仓山下时间: ...
随机推荐
- PLC与PC通讯
using System; using System.Windows.Forms; using Microsoft.Win32; // for the registry table using Sys ...
- C# 跨窗体事件
跨窗体事件:例如从一个窗体改变另一个窗体button的颜色,首先需要将需要改变button的属性改为public using System; using System.Drawing; using S ...
- js-点击+加关注变成已关注,已关注状态时,鼠标滑动上的状态时取消关注
效果: HTML: <div class="rightBtn cur">+关注</div> CSS: .rightBtn{ width: 80px; hei ...
- 手写一个类加载器demo
1.什么是类加载器? 2.加载方式 ClassLoader类加载器,主要的作用是将class文件加载到jvm虚拟机中.jvm启动的时候,并不是一次性加载所有的类,而是根据需要动态去加载类,主要分为隐式 ...
- [pwnable.kr]Dragon
0x00: dragon 是一个UAF漏洞的利用. UseAfterFree 是堆的漏洞利用的一种 简单介绍 https://www.owasp.org/index.php/Using_freed_m ...
- Linux—查看路由
下面那些命令可以用来查看Linux主机的默认路由() A.route B.ifconfig C.ping D.netstat 分析: A.route命令用来显示目前本机路由表的内容,并且还可以针对路由 ...
- Linux命令-文本编辑(二)
Linux命令-文本编辑(二) Linux mtype命令 mtype为mtools工具指令,模拟MS-DOS的type指令,可显示MS-DOS文件的内容. 语法: mtype [-st][文件] 参 ...
- JavaWeb_(SSH论坛)_五、帖子模块
基于SSH框架的小型论坛项目 一.项目入门 传送门 二.框架整合 传送门 三.用户模块 传送门 四.页面显示 传送门 五.帖子模块 传送门 六.点赞模块 传送门 七.辅助模块 传送门 回复帖子 分析回 ...
- vue计算属性详解
一.什么是计算属性 模板内的表达式非常便利,但是设计它们的初衷是用于简单运算的.在模板中放入太多的逻辑会让模板过重且难以维护.例如: <div id="example"> ...
- Spring boot之JdbcTemplate
实体类 package com.kfit.demo1.bean; import javax.persistence.Entity; import javax.persistence.Generated ...