基于bs4库的HTML标签遍历方法
基于bs4库的HTML标签遍历方法
import requests
r=requests.get('http://python123.io/ws/demo.html')
demo=r.text
HTML基本格式
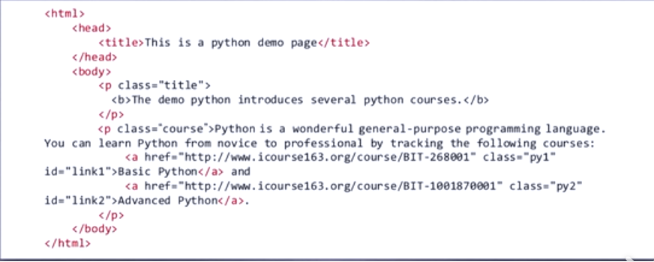
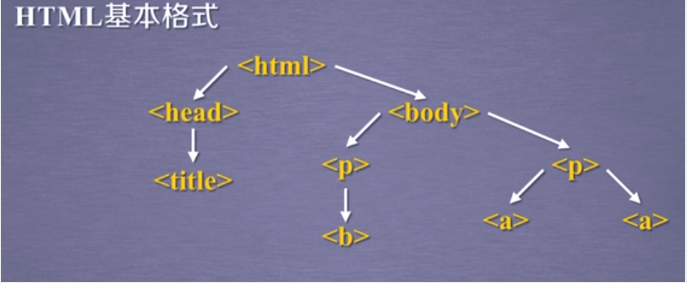
HTML可以看做一棵标签树
遍历方法
!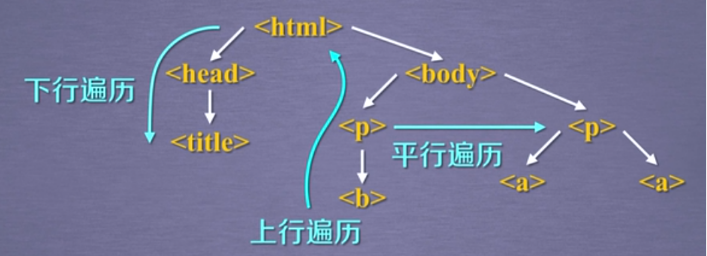
下行遍历
| 属性 | 说明 |
|---|---|
| .contents | 将该标签所有的儿子节点存入列表 |
| .children | 子节点的迭代类型,和contents类似,用于遍历儿子节点 |
| .descendants | 子孙节点的迭代类型,包含所有的子孙跌点,用于循环遍历 |
import requests
from bs4 import BeautifulSoup
r=requests.get('http://python123.io/ws/demo.html')
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
print(soup.contents)# 获取整个标签树的儿子节点
print(soup.body.content)#返回标签树的body标签下的节点
print(soup.head)#返回head标签
print(len(soup.body.content))#输出body标签儿子节点的个数
print(soup.body.content[1])#获取body下第一个子标签
遍历子孙节点
import requests
from bs4 import BeautifulSoup
r=requests.get('http://python123.io/ws/demo.html')
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
for child in soup.body.children:#遍历儿子节点
print(child)
for child in soup.body.descendants:#遍历子孙节点
print(child)
上行遍历
| 属性 | 说明 |
|---|---|
| .parent | 节点的父亲标签 |
| .parents | 节点的先辈标签的迭代类型,用于循环遍历先辈节点 |
import requests
from bs4 import BeautifulSoup
r=requests.get('http://python123.io/ws/demo.html')
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
print(soup.title.parent)
print(soup.title.parent)
print(soup.parent)
import requests
from bs4 import BeautifulSoup
r=requests.get('http://python123.io/ws/demo.html')
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
for parent in soup.a.parents:#遍历先辈的信息
if parent is None:
print(parent)
else:
print(parent.name)
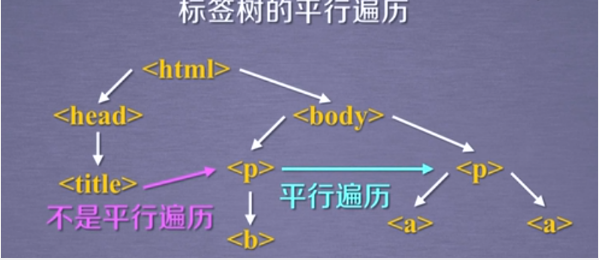
平行遍历
| 属性 | 说明 |
|---|---|
| .next_sibling | 返回HTML文本顺序的下一个平行标签 |
| .previous_sibling | 返回HTML文本顺序的上一个平行标签 |
| .next_siblings | 迭代类型,返回HTML文本顺序后续所有的平行标签 |
| .pervious_siblings | 迭代类型,返回HTML文本顺序前面所有的平行标签 |
注意
- 标签树的平行遍历是有条件的
- 平行遍历发生在同一个父亲节点的各节点之间
- 标签中的内容也构成了节点
import requests
from bs4 import BeautifulSoup
r=requests.get('http://python123.io/ws/demo.html')
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
print(soup.a.next_sibling)#a标签的下一个标签
print(soup.a.next_sibling.next_sibling)#a标签的下一个标签的下一个标签
print(soup.a.previous_sibling)#a标签的前一个标签
print(soup.a.previous_sibling.previous_sibling)#a标签的前一个标签的前一个标签
平行遍历
import requests
from bs4 import BeautifulSoup
r=requests.get('http://python123.io/ws/demo.html')
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
for sibling in soup.a.next_siblings:#遍历后续节点
print(sibling)
for sibling in soup.a.previous_sibling:#遍历之前的节点
print(sibling)
有层次感的输出-prettify()
import requests
from bs4 import BeautifulSoup
r=requests.get('http://python123.io/ws/demo.html')
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
print(soup.prettify())
基于bs4库的HTML标签遍历方法的更多相关文章
- 基于bs4库的HTML内容查找方法
一.信息提取实例 提取HTML中所有的URL链接 思路:1)搜索到所有的<a>标签 2)解析<a>标签格式,提取href后的链接内容 >>> import r ...
- 基于bs4库的HTML查找方法
基于bs4库的HTML查找方法 find_all方法 <>.find_all(name,attrs,recursive,string,**kwargs) 返回一个列表类型,内部存储查找的结 ...
- python bs4库
Beautiful Soup parses anything you give it, and does the tree traversal stuff for you. BeautifulSoup ...
- 《爬虫学习》(四)(使用lxml,bs4库以及正则表达式解析数据)
1.XPath: XPath(XML Path Language)是一门在XML和HTML文档中查找信息的语言,可用来在XML和HTML文档中对元素和属性进行遍历. 工具:扩展商店里搜索:XPath ...
- WebGIS中基于控制点库进行SHP数据坐标转换的一种查询优化策略
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1.前言 目前项目中基于控制点库进行SHP数据的坐标转换,流程大致为:遍 ...
- JSTL标签库之核心标签
一.JSTL标签库介绍 JSTL标签库的使用是为弥补html标签的不足,规范自定义标签的使用而诞生的.使用JSLT标签的目的就是不希望在jsp页面中出现java逻辑代码 二.JSTL标签库的分类 核心 ...
- javaweb学习总结(二十八)——JSTL标签库之核心标签
一.JSTL标签库介绍 JSTL标签库的使用是为弥补html标签的不足,规范自定义标签的使用而诞生的.使用JSLT标签的目的就是不希望在jsp页面中出现java逻辑代码 二.JSTL标签库的分类 核心 ...
- 学会怎样使用Jsp 内置标签、jstl标签库及自定义标签
学习jsp不得不学习jsp标签,一般来说,对于一个jsp开发者,可以理解为jsp页面中出现的java代码越少,对jsp的掌握就越好,而替换掉java代码的重要方式就是使用jsp标签. jsp标签的分 ...
- javaWeb学习总结(9)- JSTL标签库之核心标签
一.JSTL标签库介绍 JSTL标签库的使用是为弥补html标签的不足,规范自定义标签的使用而诞生的.使用JSLT标签的目的就是不希望在jsp页面中出现java逻辑代码 二.JSTL标签库的分类 核心 ...
随机推荐
- Struts 2 配置Action详解_java - JAVA
文章来源:嗨学网 敏而好学论坛www.piaodoo.com 欢迎大家相互学习 实现了Action处理类之后,就可以在struts.xml中配置该Action,从而让Struts 2框架知道哪个Act ...
- 【shell】文本按行逆序
1.最简单的方法是使用tac [root ~]$ seq |tac 2.使用tr和awk. tr把换行符替换成自定义的分隔符,awk分解替换后的字符串,并逆序输出 [root ~]$ seq | tr ...
- Leaflet调用geoserver发布的矢量切片
geoserver如何发布切片就不写了,大家都可以查到. index.html <!DOCTYPE html> <html> <head> <meta cha ...
- GO语言学习笔记6-Sort的使用
GoLang标准库的sort包提供了排序切片和用户自定义数据集以及相关功能的函数. Sort操作的对象通常是一个slice,需要满足三个基本的接口,并且能够使用整数来索引. 1.sort实现原理 So ...
- 实验 5 Spark SQL 编程初级实践
实验 5 Spark SQL 编程初级实践 参考厦门大学林子雨 1. Spark SQL 基本操作 将下列 json 数据复制到你的 ubuntu 系统/usr/local/spark 下,并 ...
- MySQL概述 - 一条查询sql语句的执行过程
Server层 连接器 建立连接.获取权限.维持和管理连接. 连接建立比较复杂,建议使用长连接 定期断开长连接 mysql_reset_connection指令 查询缓存 建议关闭,任何更新操作会此t ...
- 上传200G文件
最近遇见一个需要上传百G大文件的需求,调研了七牛和腾讯云的切片分段上传功能,因此在此整理前端大文件上传相关功能的实现. 在某些业务中,大文件上传是一个比较重要的交互场景,如上传入库比较大的Excel表 ...
- BZOJ 4883: [Lydsy1705月赛]棋盘上的守卫 最小生成树 + 建模
Description 在一个n*m的棋盘上要放置若干个守卫.对于n行来说,每行必须恰好放置一个横向守卫:同理对于m列来说,每列 必须恰好放置一个纵向守卫.每个位置放置守卫的代价是不一样的,且每个位置 ...
- CDOJ 1070 秋实大哥打游戏 带权并查集
链接 F - 秋实大哥打游戏 Time Limit:1000MS Memory Limit:65535KB 64bit IO Format:%lld & %llu Submit ...
- Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks(用于深度网络快速适应的元学习)
摘要:我们提出了一种不依赖模型的元学习算法,它与任何梯度下降训练的模型兼容,适用于各种不同的学习问题,包括分类.回归和强化学习.元学习的目标是在各种学习任务上训练一个模型,这样它只需要少量的训练样本就 ...