MySQL explain,type分析(转)
问题:explain结果中的type字段代表什么意思?

MySQL的官网解释非常简洁,只用了3个单词:连接类型(the join type)。它描述了找到所需数据使用的扫描方式。
最为常见的扫描方式有:
system:系统表,少量数据,往往不需要进行磁盘IO;
const:常量连接;
eq_ref:主键索引(primary key)或者非空唯一索引(unique not null)等值扫描;
ref:非主键非唯一索引等值扫描;
range:范围扫描;
index:索引树扫描;
ALL:全表扫描(full table scan);
上面各类扫描方式由快到慢: system > const > eq_ref > ref > range > index > ALL
下面一一举例说明。
一、system

explain select * from mysql.time_zone;
上例中,从系统库mysql的系统表time_zone里查询数据,扫码类型为system,这些数据已经加载到内存里,不需要进行磁盘IO。
这类扫描是速度最快的。

explain select * from (select * from user where id=1) tmp;
再举一个例子,内层嵌套(const)返回了一个临时表,外层嵌套从临时表查询,其扫描类型也是system,也不需要走磁盘IO,速度超快。
二、const
数据准备:
create table user (
id int primary key,
name varchar(20)
)engine=innodb; insert into user values(1,'shenjian');
insert into user values(2,'zhangsan');
insert into user values(3,'lisi');

const扫描的条件为:
(1)命中主键(primary key)或者唯一(unique)索引;
(2)被连接的部分是一个常量(const)值;
explain select * from user where id=1;
如上例,id是PK,连接部分是常量1。
这类扫描效率极高,返回数据量少,速度非常快。
三、eq_ref
数据准备:
create table user (
id int primary key,
name varchar(20)
)engine=innodb; insert into user values(1,'shenjian');
insert into user values(2,'zhangsan');
insert into user values(3,'lisi'); create table user_ex (
id int primary key,
age int
)engine=innodb; insert into user_ex values(1,18);
insert into user_ex values(2,20);
insert into user_ex values(3,30);
insert into user_ex values(4,40);
insert into user_ex values(5,50);

explain select * from user,user_ex where user.id=user_ex.id;
eq_ref扫描的条件为,对于前表的每一行(row),后表只有一行被扫描。
再细化一点:
(1)join查询;
(2)命中主键(primary key)或者非空唯一(unique not null)索引;
(3)等值连接;
如上例,id是主键,该join查询为eq_ref扫描。
这类扫描的速度也异常之快。
四、ref
数据准备:
create table user (
id int,
name varchar(20) ,
index(id)
)engine=innodb; insert into user values(1,'shenjian');
insert into user values(2,'zhangsan');
insert into user values(3,'lisi'); create table user_ex (
id int,
age int,
index(id)
)engine=innodb; insert into user_ex values(1,18);
insert into user_ex values(2,20);
insert into user_ex values(3,30);
insert into user_ex values(4,40);
insert into user_ex values(5,50);
explain select * from user,user_ex where user.id=user_ex.id;
如果把上例eq_ref案例中的主键索引,改为普通非唯一(non unique)索引。
就由eq_ref降级为了ref,此时对于前表的每一行(row),后表可能有多于一行的数据被扫描。

explain select * from user where id=1;
当id改为普通非唯一索引后,常量的连接查询,也由const降级为了ref,因为也可能有多于一行的数据被扫描。
ref扫描,可能出现在join里,也可能出现在单表普通索引里,每一次匹配可能有多行数据返回,虽然它比eq_ref要慢,但它仍然是一个很快的join类型。
五、range
数据准备:
create table user (
id int primary key,
name varchar(20)
)engine=innodb; insert into user values(1,'shenjian');
insert into user values(2,'zhangsan');
insert into user values(3,'lisi');
insert into user values(4,'wangwu');
insert into user values(5,'zhaoliu');
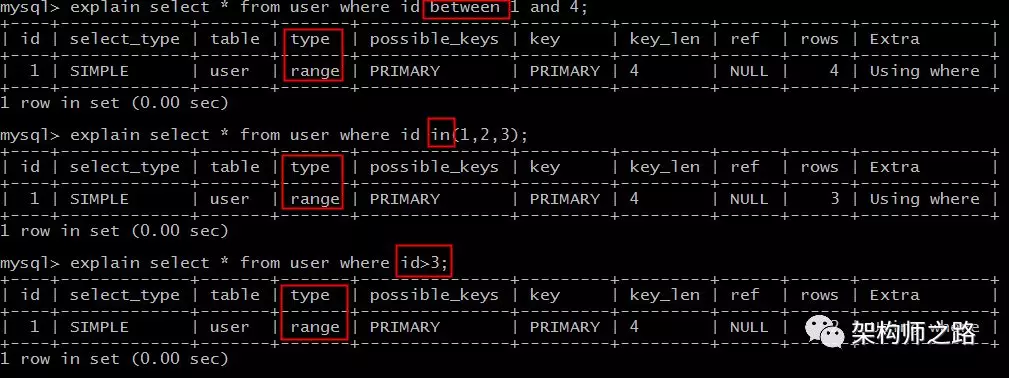
explain select * from user where id between 1 and 4;
explain select * from user where idin(1,2,3);
explain select * from user where id>3;
range扫描就比较好理解了,它是索引上的范围查询,它会在索引上扫码特定范围内的值。
像上例中的between,in,>都是典型的范围(range)查询。
六、index

explain count (*) from user;
index类型,需要扫描索引上的全部数据。
如上例,id是主键,该count查询需要通过扫描索引上的全部数据来计数。 它仅比全表扫描快一点。
七、ALL
数据准备:
create table user (
id int,
name varchar(20)
)engine=innodb; insert into user values(1,'shenjian');
insert into user values(2,'zhangsan');
insert into user values(3,'lisi'); create table user_ex (
id int,
age int
)engine=innodb; insert into user_ex values(1,18);
insert into user_ex values(2,20);
insert into user_ex values(3,30);
insert into user_ex values(4,40);
insert into user_ex values(5,50);

explain select * from user,user_ex where user.id=user_ex.id;
如果id上不建索引,对于前表的每一行(row),后表都要被全表扫描。
今天这篇文章中,这个相同的join语句出现了三次:
(1)扫描类型为eq_ref,此时id为主键;
(2)扫描类型为ref,此时id为非唯一普通索引;
(3)扫描类型为ALL,全表扫描,此时id上无索引;
有此可见,建立正确的索引,对数据库性能的提升是多么重要。
另外,《类型转换带来的大坑》中,也提到不正确的SQL语句,可能导致全表扫描。
全表扫描代价极大,性能很低,是应当极力避免的,通过explain分析SQL语句,非常有必要。
总结
(1)explain结果中的type字段,表示(广义)连接类型,它描述了找到所需数据使用的扫描方式;
(2)常见的扫描类型有:
system>const>eq_ref>ref>range>index>ALL
其扫描速度由快到慢;
(3)各类扫描类型的要点是:
system最快:不进行磁盘IO
const:PK或者unique上的等值查询
eq_ref:PK或者unique上的join查询,等值匹配,对于前表的每一行(row),后表只有一行命中
ref:非唯一索引,等值匹配,可能有多行命中
range:索引上的范围扫描,例如:between/in/>
index:索引上的全集扫描,例如:InnoDB的count
ALL最慢:全表扫描(full table scan)
(4)建立正确的索引(index),非常重要;
(5)使用explain了解并优化执行计划,非常重要;
出处:https://mp.weixin.qq.com/s/uenONvfT0ZcXl5-WIZtFHQ
MySQL explain,type分析(转)的更多相关文章
- mysql explain type详解
本文转载自最官方的 mysql explain type 字段解读 读了很多别人的笔记都杂乱不堪,很少有实例,什么都不如原装的好,所以当你读到我的笔记的时候如果觉得说的不明白,最好参考官方的手册. 我 ...
- MySQL explain type 连接类型
查看使用的数据库版本 select version(); 5.7.30 官方提供的示例数据sakila 下载地址: https://dev.mysql.com/doc/index-other.html ...
- mysql Explain 性能分析关键字
EXPLAIN 输出格式select_typetabletypepossible_keyskeykey_lenrowsExtra MySQL 提供了一个 EXPLAIN 命令, 它可以对 SELECT ...
- MySQL——explain性能分析的使用
用法:explain sql语句: id:查询的序号. ref:进行连接查询时,表得连接关系.可以通过上图看出. select_type:select查询的类型,主要是区别普通查询和联合查询.子查询之 ...
- [转]Mysql explain用法和性能分析
本文转自:http://blog.csdn.net/haifu_xu/article/details/16864933 from @幸福男孩 MySQL中EXPLAIN解释命令是显示mysql如何 ...
- MySQL 性能优化神器 Explain 使用分析
简介 MySQL 提供了一个 EXPLAIN 命令, 它可以对 SELECT 语句进行分析, 并输出 SELECT 执行的详细信息, 以供开发人员针对性优化. EXPLAIN 命令用法十分简单, 在 ...
- mysql explain 分析sql语句
鉴于最近做的事情,需要解决慢sql的问题,现补充一点sql语句性能分析之explain的使用方式! 综合返回数据情况,分析各个参数,可以了解sql 使用方法:explain + sql语句 如 :e ...
- mysql 执行计划分析三看, explain,profiling,optimizer_trace
http://blog.csdn.net/xj626852095/article/details/52767963 step 1 使用explain 查看执行计划, 5.6后可以加参数 explain ...
- Mysql explain分析sql语句执行效率
mysql优化–explain分析sql语句执行效率 Explain命令在解决数据库性能上是第一推荐使用命令,大部分的性能问题可以通过此命令来简单的解决,Explain可以用来查看SQL语句的执行效 ...
- MySQL 之 Explain 输出分析
MySQL 之 Explain 输出分析 背景 前面的文章写过 MySQL 的事务和锁,这篇文章我们来聊聊 MySQL 的 Explain,估计大家在工作或者面试中多多少少都会接触过这个.可能工作中 ...
随机推荐
- antd不可选择时间
//不能选择今天之前的日期<DatePicker format={this.timeFormat} showTime placeholder="项目结束日期" disable ...
- Linux 环境下 gzip 的加解密命令
1.加密 [root@127-0-0-1 nginx]# gzip -v access.log-20190328 access.log-20190328: 95.8% -- replaced with ...
- Mysql5.7.26解压版(免安装版)简单快速配置步骤,5分钟搞定(win10-64位系统)
第一次安装mysql环境的时候,总会遇到各种各样的坑,在尝试了安装版和解压版的数据库之后,感觉mysql的解压版更加的简单方便,省去好多时间做专业的事情 我这里选择的是5.7.26版本,解压版下载地址 ...
- windows10 gcc编译C程序(简单编译)
参考:http://c.biancheng.net/view/660.html gcc可以一次性完成C语言源程序的编译,也可以分步骤完成:下面先介绍一次性编译过程. 1.生成可执行程序 cd xxx ...
- cvtColor
E:/OpenCV/opencv/sources/modules/imgproc/src/color.cpp CV_RGB2GRAY:RGB--->GRAY.
- 手写ORM
利用ORM把mysql中的数据封装成对象,通过对象点语法来获取mysql中的数据,所以自己手写一个ORM,方便我们操作数据 一.ORM:对象关系映射 类 >>> 数据库的一张表 对象 ...
- mac卸载jdk
在本地gradle打包后,将war包部署到服务器,tomcat的localhost日志报这个错: 严重: Error configuring application listener of class ...
- VS Code报错Module 'xx' has no 'xx' member pylint(no-member)解决办法
pylint是vscode的python语法检查器,pylint是静态检查,在用第三方库的时候有些成员只有在运行代码的时候才会被建立,它就找不到成员,在设置(settings.json)里添加 &qu ...
- es之主分片和复制分片的交互过程
1:索引(创建或者删除)一个文档 首先:发送一个索引或者删除的请求给node1 其次:node1接收到请求之后,会根据请求中携带的参数“文档id”判断出该文档应该存储在具体哪一个shard中 shar ...
- (转载)FM 算法
(转载)FM算法 https://zhuanlan.zhihu.com/p/33184179