Gradient Descent with Momentum and Nesterov Momentum
在Batch Gradient Descent及Mini-batch Gradient Descent, Stochastic Gradient Descent(SGD)算法中,每一步优化相对于之前的操作,都是独立的。每一次迭代开始,算法都要根据更新后的Cost Function来计算梯度,并用该梯度来做Gradient Descent。
Momentum以及Nestrov Momentum相较于前三种算法,虽然也会根据Cost Function来计算当前的梯度,但是却不直接用此梯度去做Gradient Descent。而是赋予当前梯度一个权值,并综合考虑之前N次优化的梯度(使其形成一个动量、或类比为惯性),得到一个加权平均的移动平均值(Weighted Moving Average),之后再来作Gradient Descent。
Gradient Descent with Momentum:
首先,我们需要计算Momentum,即动量。这里使用Exponential Moving Average(EMA)来计算该加权平均值,公式为:
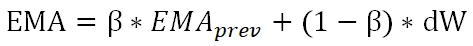
dW为本次计算出的梯度值,β是衰减因子,取值在0-1之间。为了直观的理解指数衰减权值,将上式展开,可以得到:
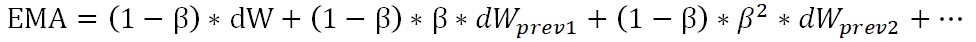
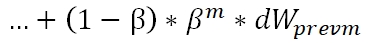
通过上式,我们可以知道,梯度序列的权重是随着β进行指数衰减的。根据β值的大小,可以得出大致纳入考虑范围的步数为1/(1-β),β值越大,衰减满、纳入考虑的步数约多,反之则窗口约窄。
Momentum算法会减小算法的震荡,在实现上也非常有效率,比起Simple Moving Average,EMA所用的存储空间小,并且每次迭代中使用一行代码即可实现。不过,β成为了除α外的又一个Hyperparameter,调参要更难了。
Nesterov Momentum:
如下图左侧所示,Gradient Descent with Momentum实际上是两个分向量的加和。一个分量是包含“惯性”的momentum,另一个分量是当前梯度,二者合并后产生出实际的update梯度。下图右侧,是Nesterov Momentum算法的示意图。其思路是:明知道momentum分量是需要的,不如先将这部分更新了。
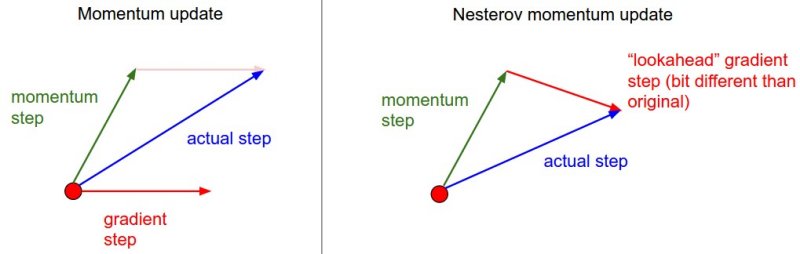
在下图中,Nesterov算法不在红点处计算梯度,而是先更新绿色箭头,并且在绿色箭头处计算梯度,再做更新。两个算法会得出不一样的结果。
Gradient Descent with Momentum and Nesterov Momentum的更多相关文章
- 深度学习(九) 深度学习最全优化方法总结比较(SGD,Momentum,Nesterov Momentum,Adagrad,Adadelta,RMSprop,Adam)
前言 这里讨论的优化问题指的是,给定目标函数f(x),我们需要找到一组参数x(权重),使得f(x)的值最小. 本文以下内容假设读者已经了解机器学习基本知识,和梯度下降的原理. SGD SGD指stoc ...
- (转) An overview of gradient descent optimization algorithms
An overview of gradient descent optimization algorithms Table of contents: Gradient descent variants ...
- An overview of gradient descent optimization algorithms
原文地址:An overview of gradient descent optimization algorithms An overview of gradient descent optimiz ...
- <反向传播(backprop)>梯度下降法gradient descent的发展历史与各版本
梯度下降法作为一种反向传播算法最早在上世纪由geoffrey hinton等人提出并被广泛接受.最早GD由很多研究团队各自发表,可他们大多无人问津,而hinton做的研究完整表述了GD方法,同时hin ...
- FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MINI-BATCH LEARNING. WHAT IS THE DIFFERENCE?
FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MIN ...
- (转)Introduction to Gradient Descent Algorithm (along with variants) in Machine Learning
Introduction Optimization is always the ultimate goal whether you are dealing with a real life probl ...
- Adaptive gradient descent without descent
目录 概 主要内容 算法1 AdGD 定理1 ADGD-L 算法2 定理2 算法3 ADGD-accel 算法4 Adaptive SGD 定理4 代码 Malitsky Y, Mishchenko ...
- 梯度下降(Gradient Descent)小结
在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法.这里就对梯度下降法做一个完整的总结. 1. 梯度 在微 ...
- 机器学习基础——梯度下降法(Gradient Descent)
机器学习基础--梯度下降法(Gradient Descent) 看了coursea的机器学习课,知道了梯度下降法.一开始只是对其做了下简单的了解.随着内容的深入,发现梯度下降法在很多算法中都用的到,除 ...
随机推荐
- Flask 中请求钩子的理解和应用?
请求钩子是通过装饰器的形式实现的,支持以下四种:1,before_first_request 在处理第一个请求前运行2,before_request:在每次请求前运行3,after_request:如 ...
- 【JAVA】input.next().charAt(0);的含义
接收键盘输入的字符串,并且取出它的第一个字符. 分析: Scanner scan=new Scanner(System.in); String s=scan.next(); //返回一个String ...
- 2018-8-10-调试-ms-源代码
title author date CreateTime categories 调试 ms 源代码 lindexi 2018-08-10 19:17:19 +0800 2018-2-13 17:23: ...
- 关于conda-新手必读
一.管理conda 通过anaconda来安装python及python包,让你不必关心系统是否安装了一些依赖,如zlib等等,anaconda已经集成了这些依赖,可以方便的安装python 下载请点 ...
- 零点.Net Core 接触
一.Program.cs类与Startup类 1.一切从Main开始,Main方法包含了是整个应用程序的入口 ASP.NET Core应用程序可以配置和启动主机(Host). 主机负责应用程序启动和生 ...
- 【转】 linux硬链接与软链接
转自:http://www.cnblogs.com/yfanqiu/archive/2012/06/11/2545556.html Linux 系统中有软链接和硬链接两种特殊的“文件”. 软链接可以看 ...
- python基础——对时间进行加减
在datetime模块中有一个timedelta这个方法,它代表两个datetime之间的时间差.. In [42]: datetime.datetime.now().strftime('%Y-%m- ...
- maven 自动编译脚本
在maven工程根目录创建windows批处理脚本文件,例如tool.bat,内容如下 @echo off color 1f :menu echo -------------------------- ...
- LightOJ 1079 Just another Robbery (01背包)
题目链接 题意:Harry Potter要去抢银行(wtf???),有n个银行,对于每个银行,抢的话,能抢到Mi单位的钱,并有pi的概率被抓到.在各个银行被抓到是独立事件.总的被抓到的概率不能超过P. ...
- 【leetcode】885. Boats to Save People
题目如下: 解题思路:本题可以采用贪心算法,因为每条船最多只能坐两人,所以在选定其中一人的情况下,再选择第二个人使得两人的体重最接近limit.考虑到人的总数最大是50000,而每个人的体重最大是30 ...