MapReduce数据格式化------<一>
引言:
我们知道:在MapReduce程序的Map阶段,需要有数据输入,而由于数据往往大小不规则,所以在数据输入Mapper之前,需要根据数据的特点和业务逻辑对数据进行格式化。这一步的格式化被称为:InputFormat。
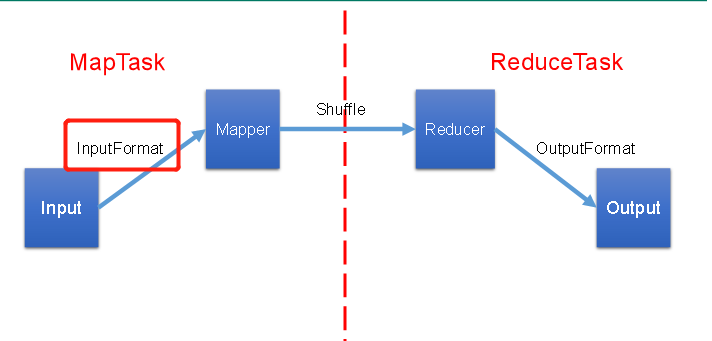
而今天的主角是:

补充:在上一篇对于任务提交的源码分析中,指出了Map阶段开启多少个节点处理Map任务是由切片数决定的,而切片数和MapTask保持一致,也就是说,当MapTask为3时,那么在Map阶段,就会开启三个节点对三个切片做数据处理。这样听起来似乎是开启的节点越多,数据处理的速度越快,就好像人多力量大那样,但事实真是如此吗?还是说会出现杀鸡焉用牛刀的情况呢?
思考:1G的数据(1024mb),启动8个MapTask使用八个节点节点做数据处理,似乎可以提高集群的并发处理能力,那个1kb的数据,也启动8个MapTask,会提高集群性能么?MapTask并行任务是否越多越好呢?哪些因素影响了MapTask并行度呢?
假设1G的数据切成按照128mb规格切片,可以切成8片,如果按照256mb规格切片,可以切成4片,显然:相同的数据,不同的切片规格,会导致切片数不同,进而导致MapTask随着切片数变化。那么这个切片规格从何而来,又如何进行设置呢?
注意:对数据进行切片,并不是从物理上将硬盘中的数据切成片分开存储,而是生成一个job.split文件记录切片信息,在Map阶段按照此文件的规划将数据分片处理。相关的内容可查看:https://www.cnblogs.com/superlsj/p/11853436.html
一、浅谈FileInputFormat切片机制【框架默认的切片机制】:


划红框的公式决定了,默认情况下是按照Blocksize的大小进行切片的,而blockSize默认为128mb。此外,在这种切片方式下,不管文件大小为多少,都在切片时都单独处理,所以当出现大量小文件时,会出现大量切片,创建大量的MapTask而导致集群性能下降。所以针对不同的数据特征,改变切片大小、合并小文件等业务需求被提了出来。
一、CombineTextInputFormat的切片机制
1、应用场景:CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。
2、虚拟存储切片最大值设置
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
注意:虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值。
3、切片机制:生成切片过程包括:虚拟存储过程和切片过程二部分。
①、虚拟存储过程:
将输入目录下所有文件大小,依次和设置的setMaxInputSplitSize值比较,如果不大于设置的最大值,逻辑上划分一个块。如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块;当剩余数据大小超过设置的最大值且不大于最大值2倍,此时将文件均分成2个虚拟存储块(防止出现太小切片)。
例如setMaxInputSplitSize值为4M,输入文件大小为8.02M,则先逻辑上分成一个4M。剩余的大小为4.02M,如果按照4M逻辑划分,就会出现0.02M的小的虚拟存储文件,所以将剩余的4.02M文件切分成(2.01M和2.01M)两个文件。
②、切片:
(a)判断虚拟存储的文件大小是否等于setMaxInputSplitSize值,等于则单独形成一个切片。
(b)如果小于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
③、案例:
有4个小文件大小分别为1.7M、5.1M、3.4M以及6.8M这四个小文件,则虚拟存储之后形成6个文件块,大小分别为:1.7M,(2.55M、2.55M),3.4M以及(3.4M、3.4M)
最终会形成3个切片,大小分别为:(1.7+2.55)M,(2.55+3.4)M,(3.4+3.4)M

如果要使用CombineTextInputFormat,需要在Driver类中指明并且设置虚拟存储的最大值:
// 如果不设置InputFormat,它默认用的是TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class); //虚拟存储切片最大值设置4m
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
那如果将最大值设置成20mb切片数为多少呢:
// 如果不设置InputFormat,它默认用的是TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class); //虚拟存储切片最大值设置20m
CombineTextInputFormat.setMaxInputSplitSize(job, 20971520);
不妨手动算一下,上面的三个切片怎么来的呢?首先第一个虚拟存储文件小于4mb,所以和下一个虚拟存储文件合并,合并后4.25mb,此时就大于4mb了,不再与下一个合并,就形成一个切片。然后是第三个虚拟存储文件2.55mb,小于4mb,所以和下一个文件合并,又形成一个切片,最终形成三个切片。倘若将最大值设置成20mb呢?首先1.7mb小于20mb,与下一个虚拟文件合并,合并后4.25mb,小于20mb,继续往下合并,最终将6个虚拟存储文件合并成了一个,形成了一个切片。
如果不指名使用CombineTextInputFormat,那么会默认使用TextInputFormat,最后再次提醒:虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值。如果文件多为1~4mb的小文件,那么在指定虚拟存储的最大值为2mb并没有多大意义。
二、FileInputFormat及其实现类
从P2可以看出,虽然FileInputFormat作为InputFormat接口的实现类,但我们使用的却是其子类,在默认情况下,我们使用其子类TextInputFormat,当使用TextInputFormat时,数据是一行一行送到map方法内部的,map方法使用偏移量作为接收数据的key。
1、KeyValueInputFormat
与TextInputFormat不同的是,KeyValueInputFormat使用了“其他”类型作为Key,但与TextInputFormat一样,KeyValueInputFormat也是每一行作为一条记录。但使用了分隔符,,使得分隔符左边的内容作为传入map方法时的key,分隔符右边的内容作为传入map方法的value。例如
Tom:Tom get a point
Jack:Jack get a point
Tom:get a point
现在要统计二人的得分,可以采用key - value 的方法,以“:”作为分隔符,名字作为key,get a point作为value。统计get a point的意义似乎不大,只要知道谁的名字作为key出现多少次也就知道各方的得分情况了。怎么实现呢?这时候使用KeyValueInputFormat就方便多了:
代码如下:
public class KVTextDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
// 设置切割符【重点】
conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, ":");
// 1 获取job对象
Job job = Job.getInstance(conf);
// 2 设置jar包位置,关联mapper和reducer
job.setJarByClass(KVTextDriver.class);
job.setMapperClass(KVTextMapper.class);
job.setReducerClass(KVTextReducer.class);
// 3 设置map输出kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 4 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 5 设置输入输出数据路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 设置输入格式【重点】
job.setInputFormatClass(KeyValueTextInputFormat.class);
// 6 设置输出数据路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交job
job.waitForCompletion(true);
}
}
当设置分隔符“:”后,分隔符左边的内容作为key,右边的作为value。再设置输入格式后,map类只需要简单的将Key写回上下文就行:
public class KVTextMapper extends Mapper<Text, Text, Text, LongWritable>{
// 1 设置value
LongWritable v = new LongWritable(1);
@Override
protected void map(Text key, Text value, Context context)
throws IOException, InterruptedException {
// banzhang ni hao
// 2 写出
context.write(key, v);
}
}
public class KVTextReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
LongWritable v = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0L;
// 1 汇总统计
for (LongWritable value : values) {
sum += value.get();
}
v.set(sum);
// 2 输出
context.write(key, v);
}
}
这样,直接将名字作为key,直接统计key的数量。
2、NLineInputFormat
在前面的案例中,数据处理都是一行一行的,如果要每n行作为一个单元,传入map处理。就要使用NLineInputFormat了。
public class NLineDriver {
public static void main(String[] args) throws IOException, URISyntaxException, ClassNotFoundException, InterruptedException {
// 输入输出路径需要根据自己电脑上实际的输入输出路径设置
args = new String[] { "e:/input/inputword", "e:/output1" };
// 1 获取job对象
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 7设置每个切片InputSplit中划分三条记录
NLineInputFormat.setNumLinesPerSplit(job, 3);
// 8使用NLineInputFormat处理记录数
job.setInputFormatClass(NLineInputFormat.class);
// 2设置jar包位置,关联mapper和reducer
job.setJarByClass(NLineDriver.class);
job.setMapperClass(NLineMapper.class);
job.setReducerClass(NLineReducer.class);
// 3设置map输出kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 4设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 5设置输入输出数据路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 6提交job
job.waitForCompletion(true);
}
}
public class NLineMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
private Text k = new Text();
private LongWritable v = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割
String[] splited = line.split(" ");
// 3 循环写出
for (int i = 0; i < splited.length; i++) {
k.set(splited[i]);
context.write(k, v);
}
}
}
public class NLineReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
LongWritable v = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0l;
// 1 汇总
for (LongWritable value : values) {
sum += value.get();
}
v.set(sum);
// 2 输出
context.write(key, v);
}
}
处理数据:
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang banzhang ni hao
xihuan hadoop banzhang
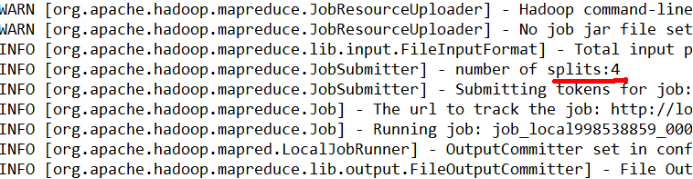
https://www.cnblogs.com/superlsj/p/11853436.html
MapReduce数据格式化------<一>的更多相关文章
- SpringMVC框架下数据的增删改查,数据类型转换,数据格式化,数据校验,错误输入的消息回显
在eclipse中javaEE环境下: 这儿并没有连接数据库,而是将数据存放在map集合中: 将各种架包导入lib下... web.xml文件配置为 <?xml version="1. ...
- SpringMVC 数据转换 & 数据格式化 & 数据校验
数据绑定流程 1. Spring MVC 主框架将 ServletRequest 对象及目标方法的入参实例传递给 WebDataBinderFactory 实例,以创建 DataBinder 实例对象 ...
- ECharts图表中级入门之formatter:夜谈关于ECharts图表内的数据格式化方法
来源于:http://www.ithao123.cn/content-3751220.html 格式化之所以存在,主要是因为我们想把一些不够人性化的内容通过某种处理让其变得人性化,便于用户更好地理解内 ...
- PHP json数据格式化方法
php 的json_encode能把数组转换为json格式的字符串.字符串没有缩进,中文会转为unicode编码,例如\u975a\u4ed4.人阅读比较困难.现在这个方法在json_encode的基 ...
- 一个通用的DataGridView导出Excel扩展方法(支持列数据格式化)
假如数据库表中某个字段存放的值“1”和“0”分别代表“是”和“否”,要在DataGridView中显示“是”和“否”,一般用两种方法,一种是在sql中直接判断获取,另一种是在DataGridView的 ...
- PAT IO-04 混合类型数据格式化输入(5)
/* *PAT IO-04 混合类型数据格式化输入(5) *2015-08-01 作者:flx413 */ #include<stdio.h> int main() { int a; fl ...
- IO-04. 混合类型数据格式化输入
/** *A4-IO-04. 混合类型数据格式化输入 *C语言实现 *测试已通过 */ #include "stdio.h" int main() { float m1,m2; i ...
- SpringMVC(三)-- 视图和视图解析器、数据格式化标签、数据类型转换、SpringMVC处理JSON数据、文件上传
1.视图和视图解析器 请求处理方法执行完成后,最终返回一个 ModelAndView 对象 对于那些返回 String,View 或 ModeMap 等类型的处理方法,SpringMVC 也会在内部将 ...
- python json.dumps()函数输出json格式,使用indent参数对json数据格式化输出
在python中,要输出json格式,需要对json数据进行编码,要用到函数:json.dumps json.dumps() :是对数据进行编码 #coding=gbkimport json dict ...
随机推荐
- 2019hdu多校3 hdu4893(线段树单点 区间更新
补这题主要是因为第三个操作要维护区间,而不是点,否则会T. https://vjudge.net/problem/HDU-4893 题意:输入n.q.表示有n个数,初始化默认这n个数都为零,有q次操作 ...
- eclipse没有Web项目和Server选项
(1)在Eclipse中菜单help选项中选择install new software选项 (2)在work with 栏中输入 http://download.eclipse.org/release ...
- AOP技术介绍--(.Net中关于AOP的实现)
一.AOP实现初步 AOP将软件系统分为两个部分:核心关注点和横切关注点.核心关注点更多的是业务逻辑,关注的是系统核心的业务:而横切关注点虽与核心的业务实现无关,但它却是一种更通用的业务, ...
- 在Node.js环境下使用Express创建Web项目实例
序:如果你还不知道Node.js是什么,那么你可以先看看这篇:Node.js 究竟是什么?或者任何关于它的介绍. 一.安装Node.js 1.进入Node.js官网下载并安装 2.启动cmd输入命令查 ...
- 如何搭建一个spring boot项目
什么是springboot? Spring Boot俗称微服务.Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程.该框架使用了特 ...
- 如何将数组中的元组包转化为字典通过json序列化给前端
- [CF959F]Mahmoud and Ehab and yet another xor task题解
搞n个线性基,然后每次在上一次的基础上插入读入的数,前缀和线性基,或者说珂持久化线性基. 然后一个num数组记录当时线性基里有多少数 然后每次前缀操作一下就珂以了 代码 #include <cs ...
- mysql 1067 - Invalid default value for 'addtime'错误处理
错误描述 TABLE `bota_payment_closing` ( `id` int(11) NOT NULL AUTO_INCREMENT, `monthly` varchar(8) NOT N ...
- 关于JS的面向对象的思考和总结
面向对象编程的概念和原理 1.面向对象编程是什么 它是用抽象的方式创建基于现实世界模型的编程模式(将数据和程序指令组合到对象中) 2.面向对象编程的目的 在编程中促进更好的灵活性和可维护性,在大型软件 ...
- 不间断电源(UPS)
UPS电源一般指不间断电源 UPS(Uninterruptible Power System/Uninterruptible Power Supply),即不间断电源,是将蓄电池(多为铅酸免维护蓄电池 ...