centos7.5部署ELk
第1章 环境规划
1.1 ELK介绍
ELK是ElasticSerach、Logstash、Kibana三款产品名称的首字母集合,用于日志的搜集和搜索。
Elasticsearch:是一个开源分布式搜索引擎,提供搜集、分析、存储三大功能,特点是分布式、零配置、自动发现、索引自动分片、索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash:主要用来日志收集、分析、过滤日志的工具,支持大量数据获取方式。一般工作方式为C\S架构,Client端安装在需要收集日志的主机上,server端负责将收集到的各个节点日志进行过滤、修改等操作,然后一并发给elasticsearch。
Kibana:可以作为Logstash和elasticsearch提供的日志分析友好的UI界面,可以帮助汇总、分析和搜索重要数据日志。
Filebeat:轻量级数据收集引擎,ELK Stack 在 Agent 的第一选择。
1.2 Filebeat工作原理
Prospector(勘测者):负责管理Harvester并找到所有读取源。
filebeat.prospectors:
- input_type: log
paths:
- /apps/logs/*/info.log
Prospector会找到/apps/logs/*目录下的所有info.log文件,并为每个文件启动一个Harvester。Prospector会检查每个文件,看Harvester是否已经启动,是否需要启动,或者文件是否可以忽略。若Harvester关闭,只有在文件大小发生变化的时候Prospector才会执行检查。只能检测本地的文件。
1.3 ELk工作原理
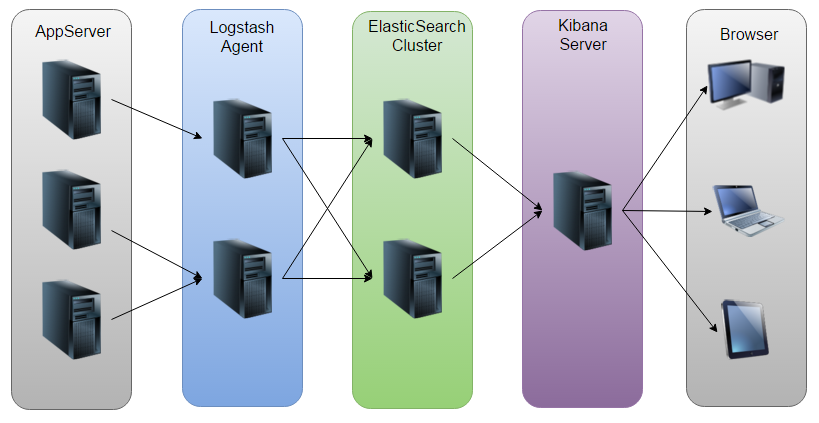
1.4 环境说明
本次实战需要两台电脑(或者vmware下的两个虚拟机),操作系统都是CentOS7,它们的身份、配置、地址等信息如下:
|
Hostname |
Ip地址 |
身份说明 |
配置 |
|
elk-server |
10.0.0.175 |
ELK服务端,接收日志,提供日志搜索服务 |
4G内存 |
|
docker01 |
10.0.0.110 |
Nginx服务端,Tomcat服务端产生的访问日志通过上报到Logstash |
2G内存 |
运行时的部署情况如下图所示:
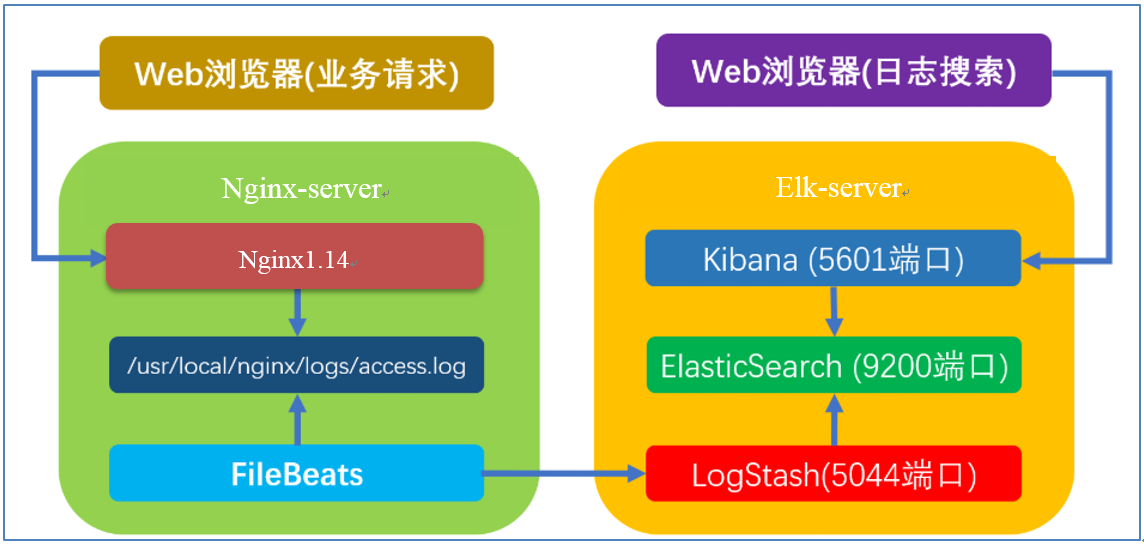
1.5 业务要求
1、业务请求到达nginx-server机器上的Nginx;
2、Nginx响应请求,并在access.log文件中增加访问记录;
3、FileBeat搜集新增的日志,通过LogStash的5044端口上传日志;
4、LogStash将日志信息通过本机的9200端口传入到ElasticSerach;
5、搜索日志的用户通过浏览器访问Kibana,服务器端口是5601;
6、Kibana通过9200端口访问ElasticSerach;
1.6 系统设置
1、设置hostname,打开文件/etc/hostname,将内容改为elk-server
2、关闭防火墙(如果因为其他原因不能关闭防火墙,也请不要禁止80端口):systemctl stop firewalld.service
3、禁止防火墙自动启动:systemctl disable firewalld.service
4、打开文件vim /etc/security/limits.conf,添加下面四行内容:
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
5、打开文件vim /etc/sysctl.conf,添加下面一行内容:
vm.max_map_count=655360
加载sysctl配置,执行命令:sysctl -p
第2章 部署ELK
2.1 安装JDK
下载地址:https://www.oracle.com/technetelk/java/javase/downloads/jdk8-downloads-2133151.html
推荐使用JDK版本为8系列。
elk-server服务器上面部署:
将下载好的JDK上传到/opt目录下面
cd /opt/
#进行解压
tar xf jdk-8u181-linux-x64.tar.gz
#创建软连接
ln -s jdk1.8.0_181 /opt/jdk
#定义环境变量
sed -i.ori '$a export JAVA_HOME=/opt/jdk\nexport PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH\nexport CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$JAVA_HOME/lib/tools.jar' /etc/profile
#注释
export JAVA_HOME=/opt/jdk
<-- 定义jdk软件程序目录
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
<-- 定义jdk命令存在于环境变量中,可以直接使用
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$JAVA_HOME/lib/tools.jar
<-- 定义java程序运行所需的库文件环境变量(classpath)
# 加载环境变量配置信息
source /etc/profile
# 确认检查jdk版本信息
java -version
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
2.2 部署elasticsearch
#创建目录/usr/local/elk
mkdir /usr/local/elk
#进入该目录中,下载软件包
cd /usr/local/elk
#下载地址ELK官网https://www.elastic.co/downloads下载
#或者命令行上面直接下载
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.4.tar.gz
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.2.4.tar.gz
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.2.4-linux-x86_64.tar.gz
#下载完毕后,将压缩包解压到/usr/local/elk目录下
tar xf elasticsearch-6.2.4.tar.gz
tar xf logstash-6.2.4.tar.gz
tar xf kibana-6.2.4-linux-x86_64.tar.gz
#创建软连接
ln -s /usr/local/elk/elasticsearch-6.2.4 /usr/local/elk/elasticsearch
ln -s /usr/local/elk/logstash-6.2.4 /usr/local/elk/logstash
ln -s /usr/local/elk/kibana-6.2.4-linux-x86_64 /usr/local/elk/kibana
创建用户:
ElasticSerach要求以非root身份启动,所以我们要创建一个用户:
创建用户组:
groupadd elk
创建用户加入用户组:
useradd elk -g elk
创建日志文件
touch /usr/local/elk/elasticsearch/logs/elasticsearch.log
设置ElasticSerach文件夹为用户elasticsearch所有:
chown -R elk. /usr/local/elk/elasticsearch/
启动ElasticSerach
切换到用户elasticsearch:su elasticsearch
su - elk
进入目录/usr/local/elk/elasticsearch;执行启动命令:bin/elasticsearch -d,此时会在后台启动elasticsearch;
cd /usr/local/elk/elasticsearch
bin/elasticsearch -d
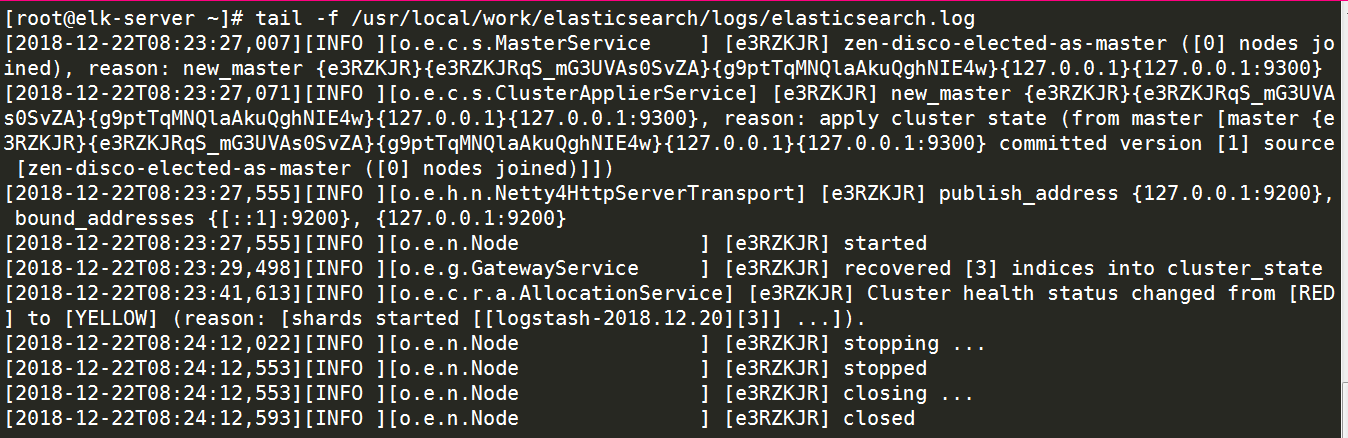
查看启动日志可执行命令:tail -f /usr/local/elk/elasticsearch/logs/elasticsearch.log 提示如下:
tail -f /usr/local/elk/elasticsearch/logs/elasticsearch.log
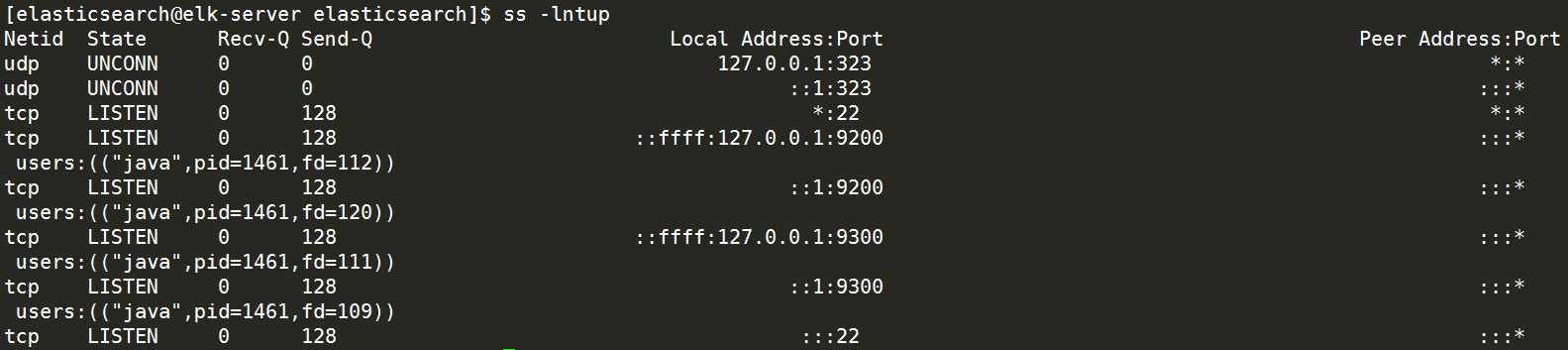
通过ss -lntup查看端口号已经启动
执行curl命令检查服务是否正常响应:curl 127.0.0.1:9200,收到响应如下:

至此,ElasticSerach服务启动成功,接下来是Logstash;
2.3 部署Logstash
#退出当前用户,回到root用户
在目录cd /usr/local/elk/logstash下创建文件vim default.conf,内容如下:
# 监听5044端口作为输入
input {
beats {
port => "5044"
}
}
# 数据过滤
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
geoip {
source => "clientip"
}
}
# 输出配置为本机的9200端口,这是ElasticSerach服务的监听端口
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
}
}
后台启动Logstash服务
nohup bin/logstash -f default.conf --config.reload.automatic &
查看启动日志:tail -f logs/logstash-plain.log,启动成功的信息如下:
通过ss -lntup查看端口号已经启动

2.4 部署配置Kibana
打开Kibana的配置文件vim /usr/local/elk/kibana/config/kibana.yml,到第七行
#server.host: "localhost"改成如下内容:
server.host: "10.0.0.175"
这样其他电脑就能用浏览器访问Kibana的服务了;
进入Kibana的目录:/usr/local/elk/kibana ;执行启动命令:nohup bin/kibana &
cd /usr/local/elk/kibana
nohup bin/kibana &
查看启动日志:tail -f nohup.out 以下信息表示启动成功:

在浏览器访问http://10.0.0.175:5601,看到如下页面

至此,ELK服务启动成功,接下来我们将业务日志上报上来,需要操作另一台电脑:docker01;
第3章 部署nginx-server
3.1 安装nginx-server
在已经部署好的docker环境下,部署nginx-server
docker run --name nginx-server -d -p 80:80 -v /var/log/nginx:/var/log/nginx nginx:1.14
通过docker ps -a可以查看到服务已经运行

通过访问页面10.0.0.110

多刷新几次,为增加日志,到此nginx-server部署完成
3.2 安装FileBeat
在nginx-server电脑创建目录/usr/local/elk
mkdir -p /usr/local/elk
进入/usr/local/elk目录下执行以下命令,下载FileBeat安装包
cd /usr/local/elk
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.2.4-linux-x86_64.tar.gz
下载完成后解压压缩包
tar -xf filebeat-6.2.4-linux-x86_64.tar.gz
ln -s /usr/local/elk/filebeat-6.2.4-linux-x86_64 /usr/local/elk/filebeat
打开文件/usr/local/elk/filebeat/filebeat.yml,修改以下内容:
24 enabled: true
28 - /var/log/nginx/*.log
143 #output.elasticsearch:
145 # hosts: ["localhost:9200"]
153 output.logstash:
155 hosts: ["10.0.0.175:5044"]
最后的配置文件为:
egrep -v '^$|#' /usr/local/elk/filebeat/filebeat.yml
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/nginx/*.log
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 3
setup.kibana:
output.logstash:
hosts: ["10.0.0.175:5044"]
启动FileBeat
nohup ./filebeat -e -c filebeat.yml &>/dev/null &
至此,FileBeat也启动成功了,接下来验证服务;
第4章 Kibana页面展示
通过浏览器多访问几次nginx服务,这样能多制造一些访问日志,访问地址:http://10.0.0.110
访问Kibana:http://10.0.0.175:5601,点击左上角的Discover,如下图红框,可以看到访问日志已经被ELK搜集了:
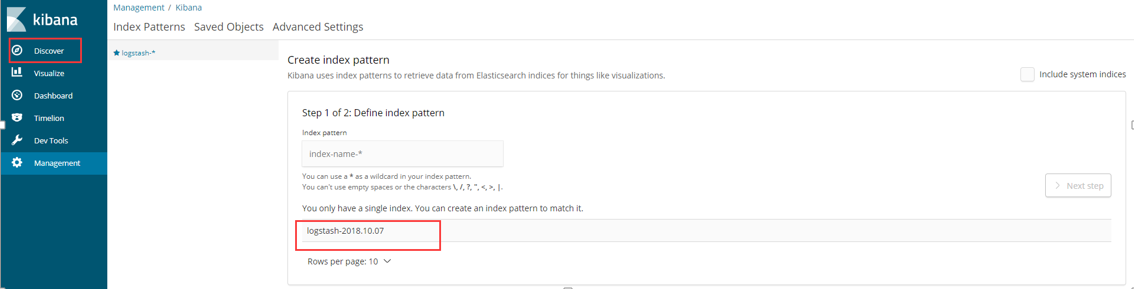
如下图,输入logstash-*,点击”Next step”:
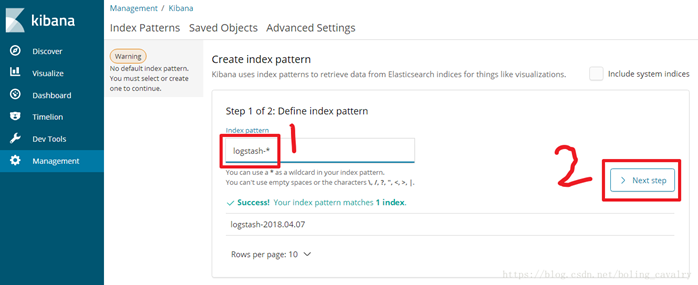
如下图,选择Time Filter,再点击“Create index pattern”:
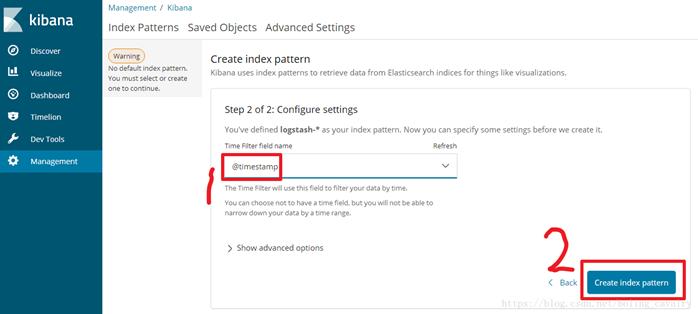
页面提示创建Index Patterns成功:
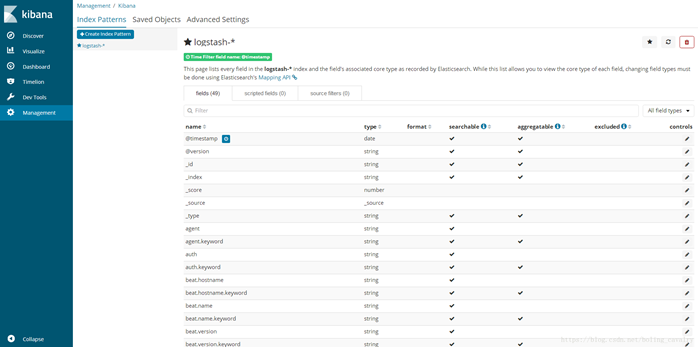
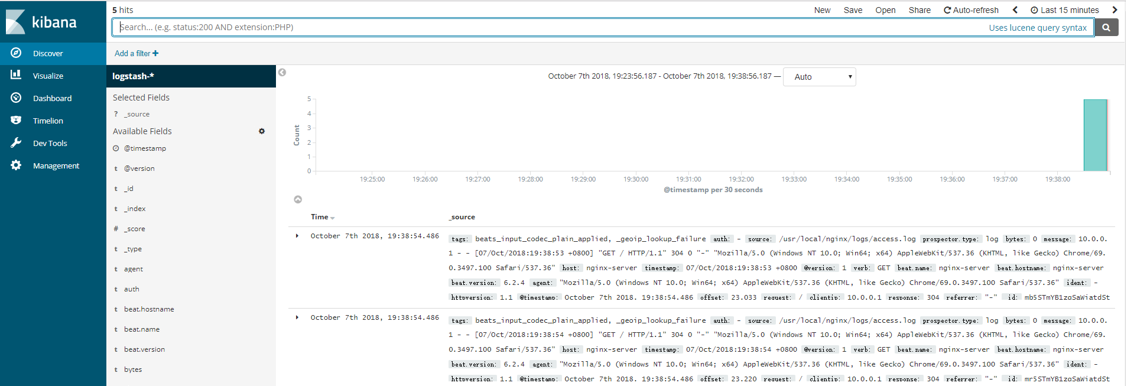
点击左上角的”Discover”按钮,即可看到最新的日志信息,如下图:
在下图的此处可以关键词搜索:error*,也可以查看nginx的报错信息
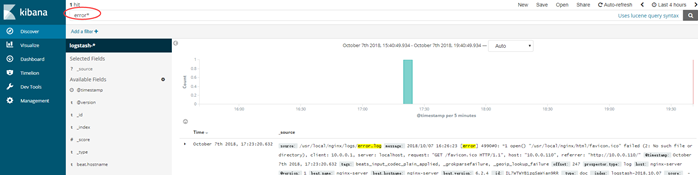
至此,我们已经可以在ELK上查到Nginx的访问日志了,接下来将Tomcat的日志也接进来;
第5章 安装和启动Tomcat
docker run --name tocat-server -d -p 8080:8080 -v /var/log/tomcat:/usr/local/tomcat/logs tomcat:latest
通过docker ps -a可以查看到服务已经运行

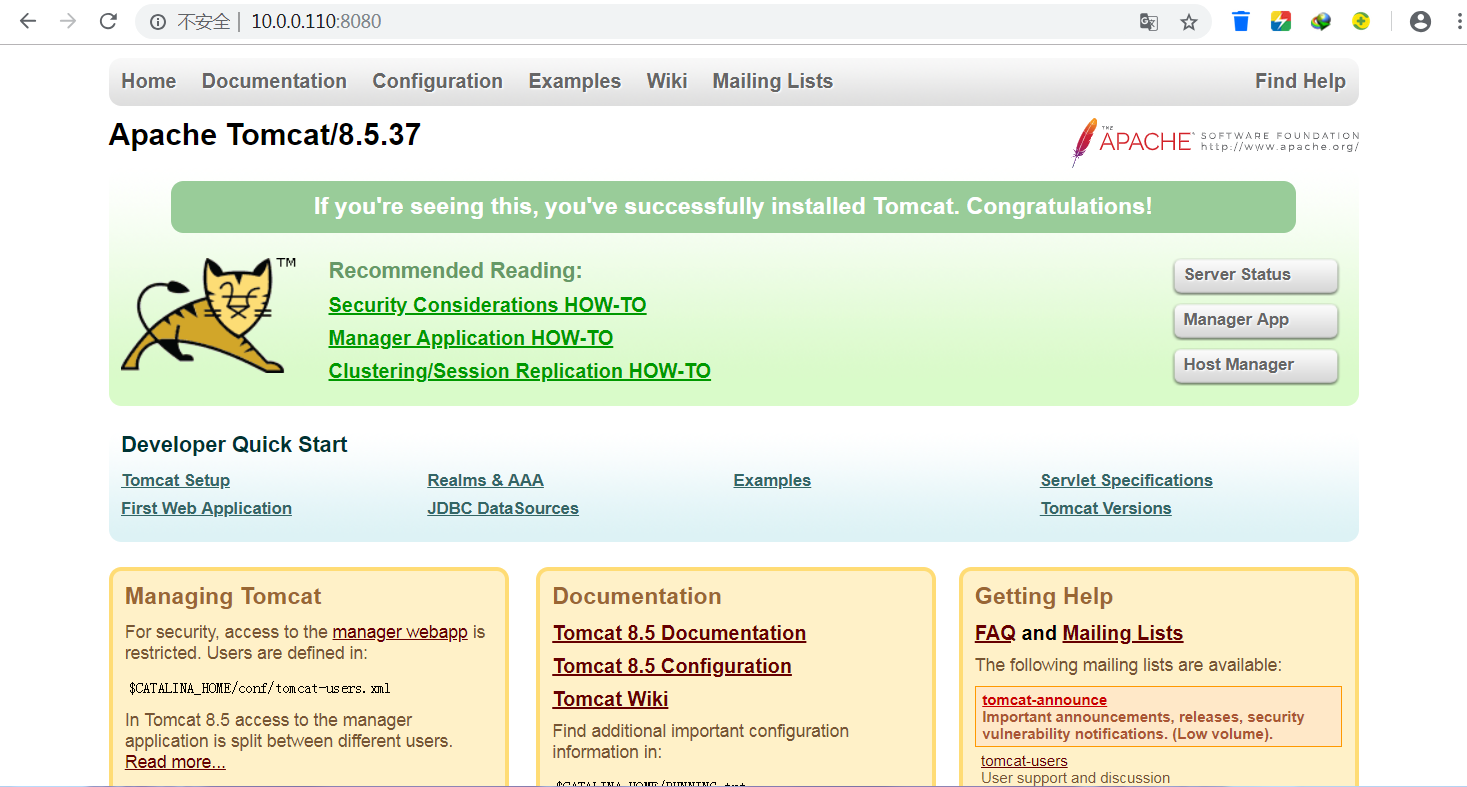
浏览器访问:http://10.0.0.110:8080,看到启动成功,如下图
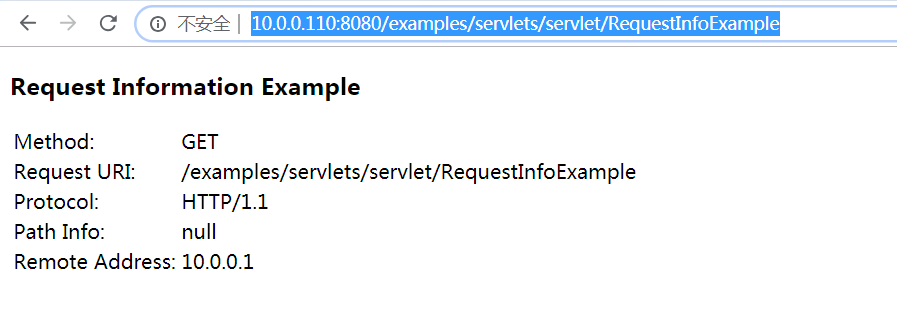
访问Tomcat提供的example服务的子页面,如下图:
http://10.0.0.110:8080/examples/servlets/servlet/RequestInfoExample
至此,Tomcat已经启动成功,接下来将Tomcat的访问日志接入ELK;
5.3 部署filebea
Tomcat访问日志接入ELK
打开FileBeat的配置文件vim /usr/local/elk/filebeat/filebeat.yml,在”filebeat.prospectors:”下面新增一个配置节点,内容如下
- type: log
enabled: true
paths:
- /var/log/tomcat/localhost_access_log.*.txt
最后配置文件内容如下:
egrep -v '^$|#' /usr/local/elk/filebeat/filebeat.yml
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/nginx/*.log
- type: log
enabled: true
paths:
- /var/log/tomcat/*
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 3
setup.kibana:
output.logstash:
hosts: ["10.0.0.175:5044"]
重启filebeat服务,首先找到这个进程,进行kill掉,再启动filebeat
ps -ef|grep filebeat
cd /usr/local/elk/filebeat
nohup ./filebeat -e -c filebeat.yml &>/dev/null &
此时在Kibana页面已经可以搜索到Tomcat的访问日志,
以“RequestInfoExample”作为关键词搜索也能搜到对应的访问日志:
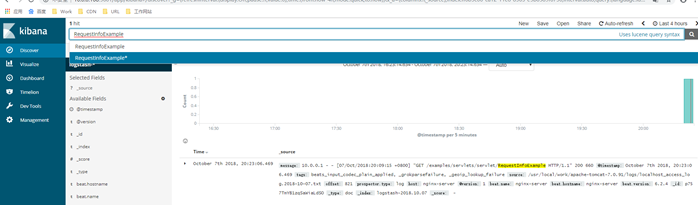
第六章 kibana平台增加安全认证
kibana是nodejs开发的,本身并没有任何安全限制,直接浏览url就能访问,如果公网环境非常不安全,可以通过nginx请求转发增加认证,方法如下:
6.1 安装nginx
yum install -y nginx
在kibana所在的服务器上安装nginx服务,利用nginx的转发指令实现。
安装好nginx后,进入nginx配置页面,修改如下:
user root;
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 80;
server_name elk.wzxmt.com;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
proxy_set_header Host $host;
proxy_pass http://127.0.0.1:5601;
auth_basic "kibana login auth";
auth_basic_user_file /etc/nginx/Kbn_htpasswd;
}
}
}
上面的配置表示将http://elk.wzxmt.com的请求,转发到服务器的5601端口,同时使用最基本的用户名、密码来认证。
6.2 安装生成密码工具:
yum install httpd-tools
生成密码文件:
[root@elk-server nginx]# htpasswd -bc /etc/nginx/Kbn_htpasswd wzxmt admin
Adding password for user wzxmt
[root@elk-server nginx]# chmod 400 /etc/nginx/Kbn_htpasswd
由于我们nginx使用者为root,所以这一块不需要授予属组权限。
6.3 修改kibana、重启kibana与nginx
vim /usr/local/work/kibana/config/kibana.yml
server.host: "127.0.0.1"
重启kibana与nginx就不再述说;
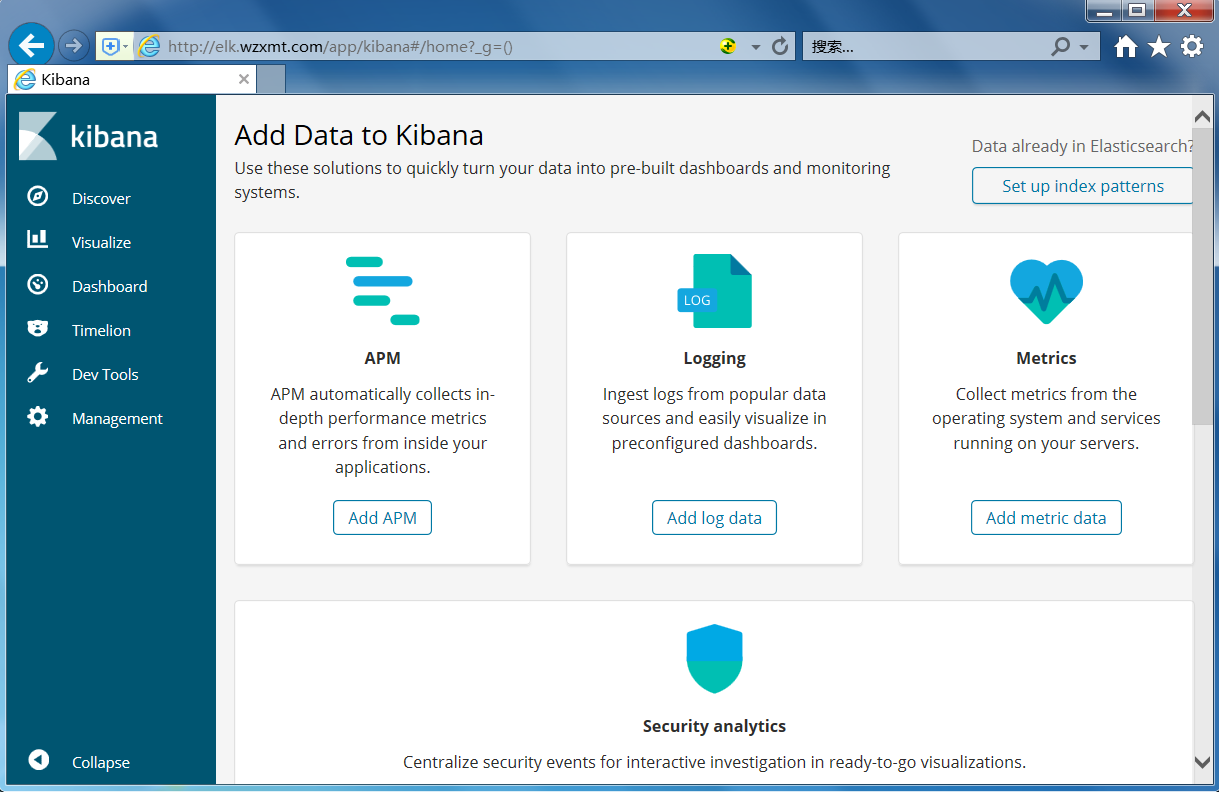
6.4 web测试
在web端测试访问

输入认证信息,即可访问kibana
第7章 汉化kibana
7.1 安装git
yum install -y git
7.2 下载汉化包
git clone https://github.com/anbai-inc/Kibana_Hanization.git
7.3 进行汉化
第一种方法:
cd Kibana_Hanization/old
python main.py /usr/local/elk/kibana/
/timelion.bundle.js]已翻译。
....
恭喜,Kibana汉化完成!
第二种方法:
(1)拷贝此项目中的translations文件夹到您的kibana目录下的src/legacy/core_plugins/kibana/目录。若您的kibana无此目录,那还是尝试使用第一种方法。
(2)修改您的kibana配置文件kibana.yml中的配置项:i18n.locale: "zh-CN"
(3)重启Kibana,汉化完成
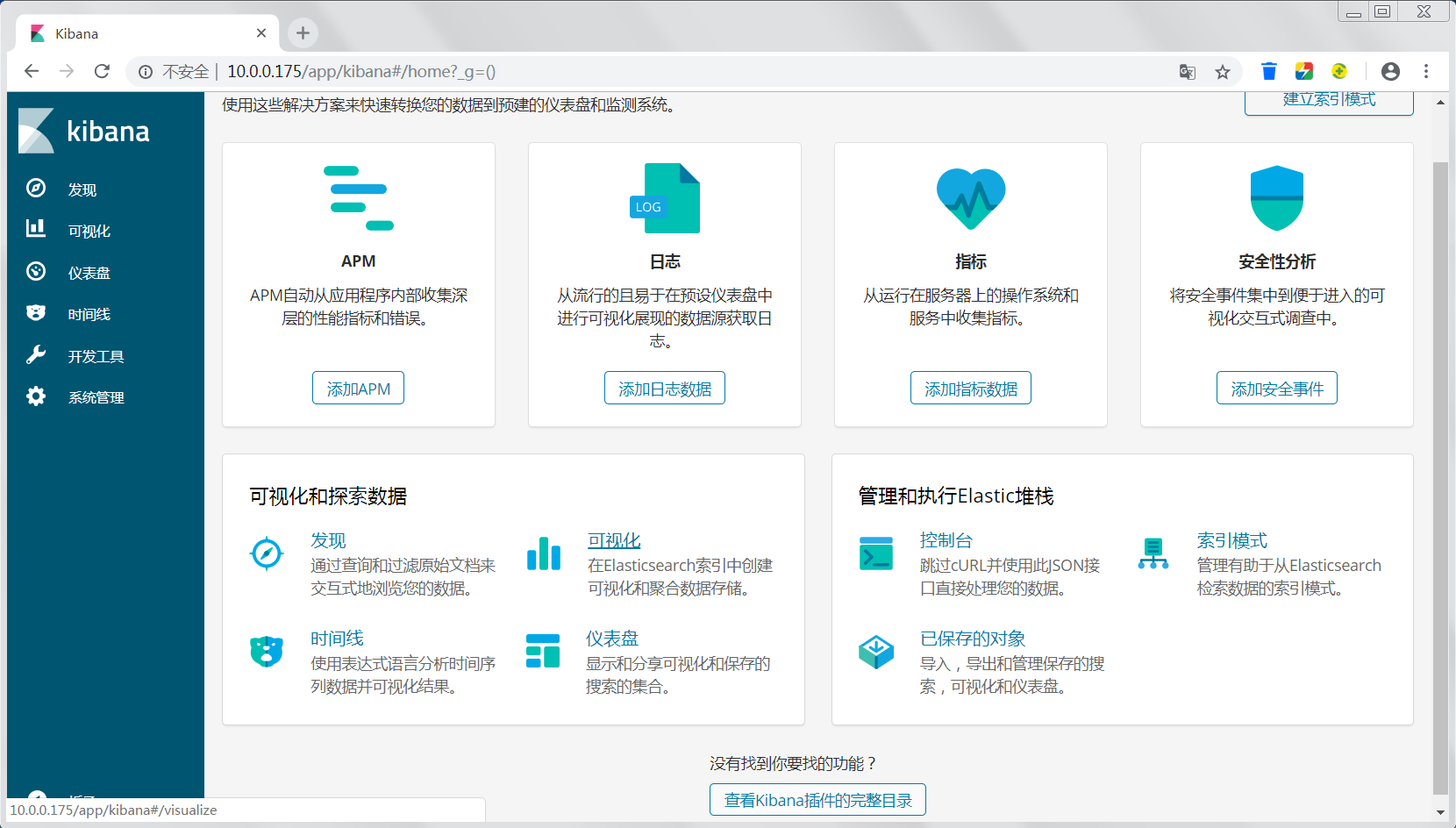
7.4 重启kibana
可以看到汉化成功。
至此,ELK-6.2.4版本的服务和日志上报的搭建已经完成,后续如果还有业务服务器要上报日志,
只需按照上述步骤安装和配置FileBeat即可;此次部署ELK,只是一个简单的了解,后面还需继续
研究ELK。
centos7.5部署ELk的更多相关文章
- Centos7单机部署ELK+x-pack
ELK分布式框架作为现在大数据时代分析日志的常为大家使用.现在我们就记录下单机Centos7部署ELK的过程和遇到的问题. 系统要求:Centos7(内核3.5及以上,2核4G) elk版本:6.2. ...
- Centos7单机部署ELK
一. 简介 1.1 介绍 ELK是三个开源工具组成,简单解释如下: Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风 ...
- 最新Centos7.6 部署ELK日志分析系统
下载elasticsearch 创建elk用户并授权 useradd elk chown -R elk:elk /home/elk/elasticsearch chown -R elk:elk /ho ...
- 在 CentOS7 上部署 MySQL 主从
在 CentOS7 上部署 MySQL 主从 通过 SecureCRT 连接至 MySQL 主服务器: 找到 my.cnf 文件所在的目录: mysql --help | grep my.cnf 一般 ...
- 在 CentOS7 上部署 zookeeper 服务
在 CentOS7 上部署 zookeeper 服务 1 用 SecureCRT 或 XShell 等 Linux 客户端工具连接至 CentOS7 服务器: 2 进入到 /usr/local/too ...
- [原创]ubuntu14.04部署ELK+redis日志分析系统
ubuntu14.04部署ELK+redis日志分析系统 [环境] host1:172.17.0.4 搭建ELK+redis服务 host2:172.17.0.3 搭建logstash+nginx服务 ...
- GIT-Linux(CentOS7)系统部署git服务器
GIT-Linux(CentOS7)系统部署git服务器 root账号登录 一. 安装并配置必要的依赖关系在CentOS系统上安装所需的依赖:ssh,防火墙,postfix(用于邮件通知) ,wget ...
- 在阿里云ECS CentOS7上部署基于MongoDB+Node.js的博客
前言:这是一篇教你如何在阿里云的ECS CentOS 7服务器上搭建一个个人博客的教程,教程比较基础,笔者尽可能比较详细的把每一步都罗列下来,包括所需软件的下载安装和域名的绑定,笔者在此之前对Linu ...
- CentOS7.4部署Python3+Django+uWSGI+Nginx
CentOS7.4部署Python3+Django+uWSGI+Nginx http://www.showerlee.com/archives/2590
随机推荐
- mysql8.0.15出错
昨天装了一个wireshark,一个fiddler,导致晚上项目启动一直报init database出错,卸载了两个软件,还是不行,后来一看mysql服务停止了,但启动总是失败.按照网上的方法好了. ...
- vue循环渲染变量类样式
由于需求的需要,将五种不同的颜色样式通过v-for进行遍历渲染,所以我这里采用绑定类函数进行判断方式.代码: 效果: 灵感来自:https://www.jianshu.com/p/33e181be3d ...
- Ant Design(ui框架)
官方文档:https://ant.design/docs/react/introduce-cn 说明:Ant Design 是一个 ui框架,和 bootstrap 一样是ui框架.里面的组件很完善, ...
- [bzoj3462]DZY Loves Math II (美妙数学+背包dp)
Description Input 第一行,两个正整数 S 和 q,q 表示询问数量. 接下来 q 行,每行一个正整数 n. Output 输出共 q 行,分别为每个询问的答案. Sample Inp ...
- git filter-branch
https://github.com/git-for-windows/git/issues/2206 https://git-scm.com/docs/git-filter-branch The -- ...
- Map-Amap:自定义地图
ylbtech-Map-Amap:自定义地图 1.返回顶部 1. http://lbs.amap.com/getting-started/mapstyle 2. 2.返回顶部 1. 自定义地图,地图从 ...
- 使用命令将ipa包上传到蒲公英
参考:官文文档 请根据开发者自己的账号,将其中的 uKey 和 _api_key 的值替换为相应的值. curl -F "file=@/Users/chenpeisong/Desktop ...
- 九条命令检查Linux服务器性能
一.uptime命令 这个命令可以快速查看机器的负载情况.在Linux系统中,这些数据表示等待CPU资源的进程和阻塞在不可中断IO进程(进程状态为D)的数量.这些数据可以让我们对系统资源使用有一个宏观 ...
- C++ 关于const引用的测试
C++ 关于const引用的测试 今天学习了<C++ primer>第五版中的const相关内容,书中关于const的部分内容如下: 由书中内容(P55~P56)可知,const引用有如下 ...
- 洛谷 P1972 [SDOI2009]HH的项链——树状数组
先上一波题目 https://www.luogu.org/problem/P1972 这道题是询问区间内不同数的个数 明显不是正常的数据结构能够维护的 首先考虑 因为对于若干个询问的区间[l,r],如 ...