[javaEE] response实现图片下载
在Servlet中的doGet()方法中
获取FileInputStream对象,new出来,构造参数:String的文件路径
得到文件路径,调用this.getServletContext().getRealPath(“这里是应用根路径”)
调用HttpServletResponse对象的getOutputStream()方法,得到OutputStream对象
正常读取和写入流
输入流可以关闭,输出流不要关闭
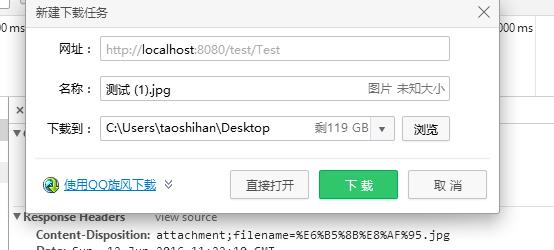
此时图片会直接显示出来,并没有出现下载
使用http协议头Content-Disposition:attachment;filename=1.jpg
调用HttpServletResponse对象的setHeader()方法,参数:key,value
此时问题,http协议头里不允许有中文,会出错,编码是iso8859-1
使用url编码方式解决,二进制转十六进制加上个%
调用UrlEncoder.encode()方法,进行url编码,参数:String文本,编码”utf-8”
response.setHeader("Content-Disposition", "attachment;filename="+URLEncoder.encode("测试.jpg", "utf-8"));
FileInputStream file=new FileInputStream(this.getServletContext().getRealPath("1.jpg"));
OutputStream os=response.getOutputStream();
byte[] b=new byte[1024];
int len=0;
while((len=file.read(b))!=-1){
os.write(b,0,len);
}
file.close();
[javaEE] response实现图片下载的更多相关文章
- response读取图片+下载图片
读取图片 import java.io.FileInputStream; import java.io.IOException; import java.io.InputStream; import ...
- C#实体图片下载与批量下载(自动保存功能)
新工作,第一个小任务,制作一个点击下载图片的功能.并提供批量下载操作.图片是字节流的形式,存放在数据库中的. 为了避免直接从数据库中,下载失败,会在本地保存一份. 进行压缩的是SharpZip这个压缩 ...
- 使用Servlet实现图片下载
package chensi.com; import java.io.FileInputStream; import java.io.IOException; import java.net.URLE ...
- (8)分布式下的爬虫Scrapy应该如何做-图片下载(源码放送)
转载主注明出处:http://www.cnblogs.com/codefish/p/4968260.html 在爬虫中,我们遇到比较多需求就是文件下载以及图片下载,在其它的语言或者框架中,我们可能 ...
- Scrapy学习篇(九)之文件与图片下载
Media Pipeline Scrapy为下载item中包含的文件(比如在爬取到产品时,同时也想保存对应的图片)提供了一个可重用的 item pipelines . 这些pipeline有些共同的方 ...
- 第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器
第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器 编写spiders爬虫文件循环 ...
- 二十 Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器
编写spiders爬虫文件循环抓取内容 Request()方法,将指定的url地址添加到下载器下载页面,两个必须参数, 参数: url='url' callback=页面处理函数 使用时需要yield ...
- 给安卓端调用的apk、图片下载接口
package com.js.ai.modules.pointwall.action; import java.io.File; import java.io.FileInputStream; imp ...
- 爬虫实战【7】Ajax解析续-今日头条图片下载
昨天我们分析了今日头条搜索得到的信息,一直对图集感兴趣的我还是选择将所有的图片下载下来. 我们继续讲一下如何通过各个图集的url得到每个图集下面的照片. 分析图集的组成 [插入图片,某个图集的页面] ...
随机推荐
- python中的MRO和C3算法
一. 经典类和新式类 1.python多继承 在继承关系中,python子类自动用友父类中除了私有属性外的其他所有内容.python支持多继承.一个类可以拥有多个父类 2.python2和python ...
- SQL语句优化 (二) (53)
接上一部分 (4)如果不是索引列的第一部分,如下例子:可见虽然在money上面建有复合索引,但是由于money不是索引的第一列,那么在查询中这个索引也不会被MySQL采用. mysql> exp ...
- jenkins+gitlab+robot framework 中遇到的坑
问题一:拉Git源代码时提示无权限 原来之前用的ssh密钥一直都是自己的用户生成的.其实在Jenkins系统使用的都是Jenkins这个系统帐号的. 解决方法: 切换到jenkins这个帐号下生成个新 ...
- 渗透日常之 花式实战助你理解CSRF
本文作者:i春秋签约作家——onls辜釉 最近比较忙,很久没发文章了,Onls本就只是一个安全爱好者,工作也不是安全相关.以往的文章也更像是利用简单漏洞的“即兴把玩”,更多的是偏向趣味性,给大家增加点 ...
- 如何无人值守安装linux系统(上)
如何开始 Linux 的无人值守安装 一.预备知识: I.什么是PXE PXE并不是一种安装方式,而是一种引导方式.进行PXE安装的必要条件是要安装的计算机中包含一个PXE支持的网卡(NIC),即网卡 ...
- 谷歌将对欧洲 Android 设备制造商收取其应用服务费用
简评:欧盟就谷歌违反了<反垄断法>开出天价罚单,导致谷歌运营生态被打破,为了配合这一裁决,谷歌将调整其运营模式.欧盟似乎赢了,而这最后买单的却是消费者. 今年七月份,谷歌要求 Androi ...
- python --爬虫基础 --爬取今日头条 使用 requests 库的基本操作, Ajax
'''思路一: 由于是Ajax的网页,需要先往下划几下看看XHR的内容变化二:分析js中的代码内容三:获取一页中的内容四:获取图片五:保存在本地 使用的库1. requests 网页获取库 2.fro ...
- webpack+vue中安装使用vue-layer弹窗插件
1.安装vue-layer插件 npm install vue-layer --save-dev 2.打包入口文件main.js中引入vue.vue-layer.并且将vue-layer添加到vue原 ...
- 46.ActiveMQ开篇(Hello World、安全认证、Connection、Session、MessageProducer、MessageConsumer)
要给有能力的人足够的发挥空间,公司可以养一些能力平平甚至是混日子的人,但绝不能让这些人妨碍有能力的人,否则这样的环境不留也罢. 一.背景介绍 CORBA\DCOM\RMI等RPC中间件技术已经广泛应用 ...
- L03-Linux RHEL6.5系统中配置本地yum源
1.将iso镜像文件上传到linux系统.注意要将文件放在合适的目录下,因为后面机器重启时还要自动挂载,所以此次挂载成功之后该文件也不要删除. 2.将iso光盘挂载到/mnt/iso目录下. (1)先 ...