3.10-通过requests、BeautifulSoup、webbrowser模块的相关方法,爬取网页数据示例程序(一)
import requests,bs4
res=requests.get('https://www.hao123.com/')
print('res对象的类型:',type(res))
res.raise_for_status() ###raise_for_status() 方法用来确保程序在下载失败时停止,预防程序发生未知错误。
noStarchSoup=bs4.BeautifulSoup(res.text) ###利用 requests.get()函数下载主页,然后将响应结果的text属性传递给 bs4.BeautifulSoup(),然后再返回的给BeautifulSoup 对象保存在变量 noStarchSoup 中。
type(noStarchSoup)
elems=noStarchSoup.select('div')
print(type(elems))
print('www.hao123.com网站的div个数为:',len(elems))
print(type(elems[2]))
print('www.hao123.com网站第89个div内的内容是:',elems[88].getText())
运行结果为:
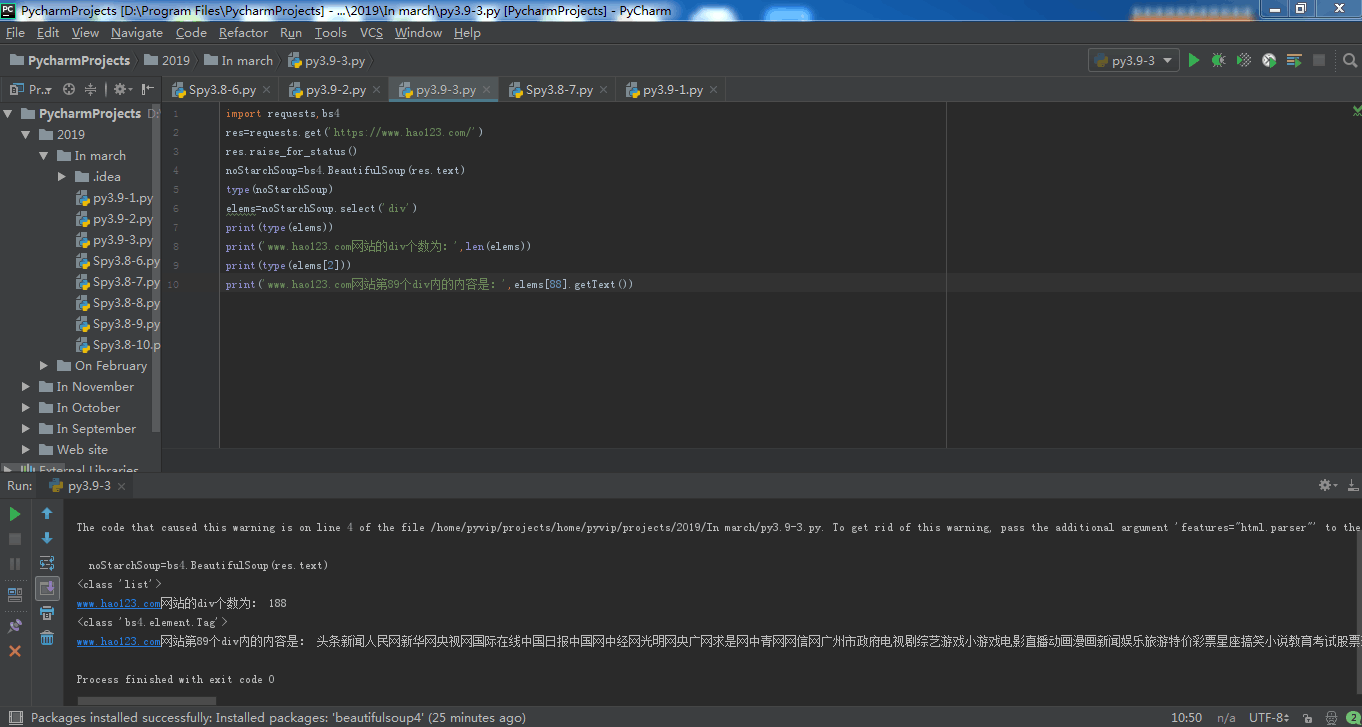
res对象的类型: <class 'requests.models.Response'>
/home/pyvip/projects/home/pyvip/projects/2019/In march/py3.9-3.py:5: UserWarning: No parser was explicitly specified, so I'm using the best available HTML parser for this system ("html.parser"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.
The code that caused this warning is on line 5 of the file /home/pyvip/projects/home/pyvip/projects/2019/In march/py3.9-3.py. To get rid of this warning, pass the additional argument 'features="html.parser"' to the BeautifulSoup constructor.
noStarchSoup=bs4.BeautifulSoup(res.text) ###利用 requests.get()函数下载主页,然后将响应结果的text属性传递给 bs4.BeautifulSoup(),然后再返回的给BeautifulSoup 对象保存在变量 noStarchSoup 中。
<class 'list'>
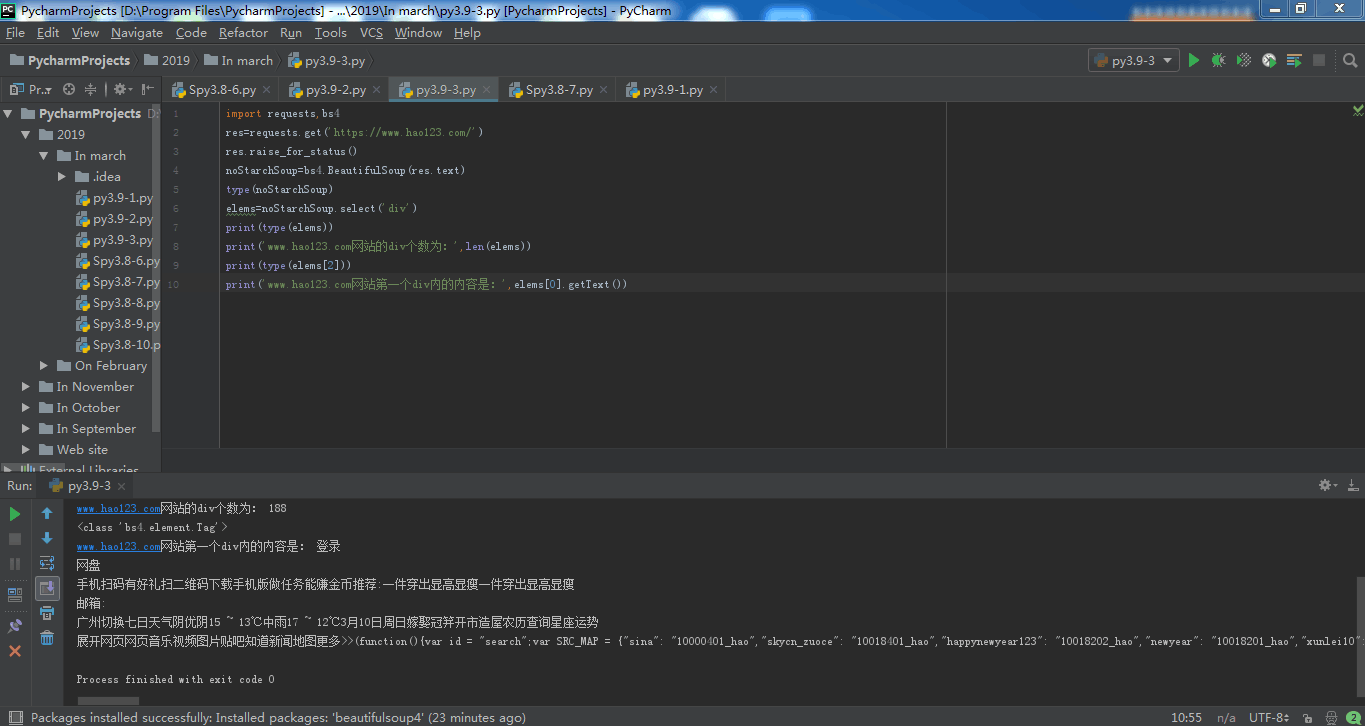
www.hao123.com网站的div个数为: 190
<class 'bs4.element.Tag'>
www.hao123.com网站第89个div内的内容是: 首页电视剧最新电影新闻头条八卦娱乐热门游戏小 游 戏今日特价特价旅游热点车讯头条新闻人民网新华网央视网国际在线中国日报中国网中经网光明网央广网求是网中青网网信网广州市政府电视剧综艺游戏小游戏电影直播动画漫画新闻娱乐旅游特价彩票星座搞笑小说教育考试股票理财推荐社会娱乐生活体育习重视河南“三农工作”对老乡最深的牵挂中国人的努力 从太空也能看到世上最长寿的人打开快递 30万的黄金变塑料大批假冒食品集中销毁 745箱零食堆成山"插座一哥"赔10亿 其公司日赚1亿代表建议:恢复"五一"七天长假 台海军一艘护卫舰遭沙特油轮撞击为何不说是日本?财长为中国辩护男子中数亿大奖 前妻:不后悔离婚美雇员行李中夹带迫击炮弹 俄火了法官顶住压力作出无罪判决 被记二等功分娩之痛 60名中学生撕心尖叫一艘高速船疑似撞到鲸鱼 致超80人受伤百度•贴吧新浪•微博搜狐•热点腾 讯网 易爱 奇 艺天猫•精选凤 凰 网淘 宝 网免费游戏百度地图hao123影视京东商城苏宁易购荣耀专区斗鱼 TV优 酷 网聚 划 算东方财富•理财58 同 城天猫超市携程旅行网12306hao123旅游瓜子二手车萌主页•动漫Booking酒店学 信 网头条新闻体育•NBA4399游戏彩票•双色球爱 淘 宝网易云音乐天涯社区知 乎哔哩哔哩直 播 吧QQ 邮 箱163 邮箱126 邮箱139 邮箱新浪邮箱搜狐邮箱工商银行建设银行农业银行中国银行招商银行交通银行邮政储蓄知 网豆 瓣聚划算优质月嫂新房装修无息贷款英语口语亲子鉴定去除甲醛游戏魔域永恒屠龙荣耀西游零纪元蓝月传奇17游戏大全乾坤战纪魔兽世界屠龙攻沙新热六间房直播苏宁易购7座家用车美女秀场iPhone降价爆款必抢新款帕萨特旧机换新推荐安居客房产二手评估热销楼盘精选二手车二手房急售二手好车三亚免税店大理古城优选名企招聘自考本科热门职位考研真题名师辅导班剑桥英语寒假冬令营同城闪送生活近视眼手术无痛拔牙隐形牙套妇科检查无痛分娩颈椎病治疗皓齿美白眼袋修复广告电视剧电影新闻娱乐体育小游戏新游特价购物综艺软件理财推 荐更多>>教你理财天猫购物季千图网苏宁超市微信 南方网视 频更多>>爱奇艺高清优酷网百度视频腾讯视频芒果TV搜狐视频网络自制影 视更多>>电视剧电影•购票动漫综艺电视直播院线大片热点资讯手绘4年抗癌日记游 戏更多>>4399游戏7k7k游戏1717337游戏hao123游戏游民星空新 闻更多>>新浪新闻腾讯新闻百度新闻搜狐新闻参考消息环球网澎湃新闻看 点更多>>中华军事米尔军事铁血军事环球军事凤凰军事新浪军事void function(e,t){for(var n=t.getElementsByTagName("img"),a=+new Date,i=[],o=function(){this.removeEventListener&&this.removeEventListener("load",o,!1),i.push({img:this,time:+new Date})},s=0;s< n.length;s++)!function(){var e=n[s];e.addEventListener?!e.complete&&e.addEventListener("load",o,!1):e.attachEvent&&e.attachEvent("onreadystatechange",function(){"complete"==e.readyState&&o.call(e,o)})}();alog("speed.set",{fsItems:i,fs:a})}(window,document);
Process finished with exit code 0
知识点总结:
requests模块有如下方法: (1)、requests.get()方法:requests.get()用来下载一个网页,该方法用来接受一个要下载的 URL 字符串,URL放在括号内。通过在 requests.get()的返回值上调用 type(),你可以看到它返回一个 Response 对象,其中包含了 Web 服务器对你的请求做出的响应。
(2)、raise_for_status()方法:用来确保程序在下载失败时停止,预防程序发生未知错误。它总是在调用requests.get()之后再调用raise_for_status(),确保下载确实成功,然后再让程序继续。
(3)、 BeautifulSoup模块:
用来解析html文件,并从html页面中提取信息。该模块名称是bs4。它有如下方法: (1)、bs4.BeautifulSoup()方法:它调用时需要一个字符串,其中包括将要解析的 HTML。
bs4.BeautifulSoup()函数返回一个BeautifulSoup对象,也就是说BeautifulSoup()方法是从html中创建一个BeautifulSoup对象。 (2)、select()方法:用于寻找网页上的元素。select()方法将返回一个Tag对象的列表。针对需要寻找的元素,调用method()方法,传入一个字符串作为CSS选择器,这样就可以取得WEB页面元素了。
传递给select()方法的选择器有: soup.select('div') 所有名为<div>的元素
soup.select('#author') 带有 id 属性为 author 的元素
soup.select('.notice') 所有使用 CSS class 属性名为 notice 的元素
soup.select('div span') 所有在<div>元素之内的<span>元素
soup.select('div > span') 所有直接在<div>元素之内的<span>元素,中间没有其他元素
soup.select('input[name]') 所有名为<input>,并有一个 name 属性,其值无所谓的元素
soup.select('input[type="button"]') 所有名为<input>,并有一个 type 属性,其值为 button 的元素
webbrowser模块:
webbrowser模块的open()方法可以启动一个新的浏览器,打开指定的URL。例如:
>>> import webbrowser
>>> webbrowser.open('http://inventwithpython.com/')
Python endswith()方法:
描述:endswith() 方法用于判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回True,否则返回False。可选参数"start"与"end"为检索字符串的开始与结束位置。
用法:str.endswith(suffix[, start[, end]])
Python os.makedirs() 方法:
描述:os.makedirs() 方法用于递归创建目录。像 mkdir(), 但创建的所有intermediate-level文件夹需要包含子目录。
makedirs()方法语法格式如下:os.makedirs(path, mode=0o777)
Python 字典(Dictionary) setdefault()方法:
描述:Python 字典 setdefault() 函数和get() 方法类似, 如果键不存在于字典中,将会添加键并将值设为默认值。
setdefault()方法语法:dict.setdefault(key, default=None)
3.10-通过requests、BeautifulSoup、webbrowser模块的相关方法,爬取网页数据示例程序(一)的更多相关文章
- 03:requests与BeautifulSoup结合爬取网页数据应用
1.1 爬虫相关模块命令回顾 1.requests模块 1. pip install requests 2. response = requests.get('http://www.baidu.com ...
- Python使用urllib,urllib3,requests库+beautifulsoup爬取网页
Python使用urllib/urllib3/requests库+beautifulsoup爬取网页 urllib urllib3 requests 笔者在爬取时遇到的问题 1.结果不全 2.'抓取失 ...
- requests爬取网页的通用框架
概述 代码编写完成时间:2017.12.28 写文章时间:2017.12.29 看完中国大学MOOC上的爬虫教程后,觉得自己之前的学习完全是野蛮生长,决定把之前学的东西再梳理一遍,主要是觉得自己写的程 ...
- 爬虫系列4:Requests+Xpath 爬取动态数据
爬虫系列4:Requests+Xpath 爬取动态数据 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参 ...
- python(27)requests 爬取网页乱码,解决方法
最近遇到爬取网页乱码的情况,找了好久找到了种解决的办法: html = requests.get(url,headers = head) html.apparent_encoding html.enc ...
- python requests库爬取网页小实例:爬取网页图片
爬取网页图片: #网络图片爬取 import requests import os root="C://Users//Lenovo//Desktop//" #以原文件名作为保存的文 ...
- Requests爬取网页的编码问题
Requests爬取网页的编码问题 import requests from requests import exceptions def getHtml(): try: r=requests.get ...
- 爬虫-----selenium模块自动爬取网页资源
selenium介绍与使用 1 selenium介绍 什么是selenium?selenium是Python的一个第三方库,对外提供的接口可以操作浏览器,然后让浏览器完成自动化的操作. sel ...
- python网络爬虫(10)分布式爬虫爬取静态数据
目的意义 爬虫应该能够快速高效的完成数据爬取和分析任务.使用多个进程协同完成一个任务,提高了数据爬取的效率. 以百度百科的一条为起点,抓取百度百科2000左右词条数据. 说明 参阅模仿了:https: ...
随机推荐
- mysql将日期字符串转换
举个例子: 给定字符串为07/31/2018,想要把格式转换成20180731 需要用到以下两个函数: date_format(date,’%Y-%m-%d’) ————–>oracle中的to ...
- 关于如何解决bootstrap table 列 切换 刷新 高度不一样
在使用bootstrap table时候,碰到bootstrap table 列 切换 刷新 高度不一样的问题,如图所示: 解决这个问题很简单,在你的页头加一句<!DOCTYPE html> ...
- activeMQ的request-response请求响应模式
一:为什么需要请求响应模式 在消息中间中,生产者只负责生产消息,而消费者只负责消费消息,两者并无直接的关联.但是如果生产者想要知道消费者有没有消费完,或者用不用重新发送的时候,这时就要用到请求响应模式 ...
- centos7添加新网卡实现双IP双网关
问题背景: 业务需要,针对业务需要不同地域的机构访问,所以需要在同一台机器上配置不同IP并配置不同网关,实现不用机构可以访问同一台服务器办理业务. 系统环境: centos linux7 网络环境: ...
- echarts通过ajax动态获取数据的方法
echarts表格的数据一般都需要动态获取,所以总结了一下通过ajax动态获取数据的操作: 插入的方法应该不止一种,我也是接触不久,所以刚学会了一种插入方法: 灵感和经验来自:https://www. ...
- jquery 60s倒计时
前端开发中经常用到的发送按钮倒计时,每次都是重写,挺麻烦的,记录一下,以后直接来复制代码 <!DOCTYPE html> <html> <head> <met ...
- 完美解决 Cydia 不能上网
国行手机比美版.港版.韩版手机新增了网络授权的功能,iOS 10 及以上系统版本,任何应用首次打开,如果有请求网络的行为,都会提示网络请求授权的对话框. 首次打开 Cydia 并没有提示网络请求授权的 ...
- 运行Delphi XE10的MongoDB例程,测试Delphi插入记录性能
Delphi XE10支持MongoDB的数据库,提供了个例子restaurants可批量导入数据. 本文对比Delphi例子与MongoDB自带的mongoimport导入批量数据的性能. 步骤: ...
- 大数据学习--day17(Map--HashMap--TreeMap、红黑树)
Map--HashMap--TreeMap--红黑树 Map:三种遍历方式 HashMap:拉链法.用哈希函数计算出int值. 用桶的思想去存储元素.桶里的元素用链表串起来,之后长了的话转红黑树. T ...
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...