算法学习记录-查找——平衡二叉树(AVL)
排序二叉树对于我们寻找无序序列中的元素的效率有了大大的提高。查找的最差情况是树的高度。这里就有问题了,将无序数列转化为
二叉排序树的时候,树的结构是非常依赖无序序列的顺序,这样会出现极端的情况。
【如图1】:

这样的一颗二叉排序树就是一颗比较极端的情况。我们在查找时候,效率依赖树的高度,所以不希望这样极端情况出现,而是希望元素比较均匀
的分布在根节点两端。
技术参考:fun4257.com/
问题提出:
能不能有一种方法,使得我们的二叉排序树不依赖无序序列的顺序,也能使得我们得到的二叉排序树是比较均匀的分布。
引入:
平衡二叉树(Self-Balancing Binary Search Tree 或 Height-Balanced Binary Search Tree),是一种特殊的二叉排序树,其中每一个结点的
左子树和右子树的高度差至多等于1.
这里的平衡从名字中可以看出,Height-Balanced是高度平衡。
它或者是一颗空树,或者是具有下列性质的二叉树:它的左子树和右子树都是平衡二叉树,且左子树和右子树的深度之差的绝对值不超过1.
若将二叉树上的结点的平衡因子BF(Balance Factor)定义为该节点的左子树的深度减去它的右子树的深度,则平衡二叉树上所有结点的平衡因子只
可能是-1、0、1。否则就不是平衡二叉树。
上图图1中,就不是平衡二叉树。
以图1来看看各个结点的平衡因子。
【如下图2】:

技术参考:fun1404.com
如何构成平衡二叉树?






从转化为平衡二叉树的过程中可以提炼出转化的几个基本情况:
下图是在维基百科上摘录的:

可以看出调整的操作分两大类,前两个是一组,后两个是一组,每组之间是对称的。
前两个是对应上图1 2 中情况,
后两个是对应上图5 6 中情况。
分别以其中一种旋转为例,另一种对应的旋转对称。
单次左旋:对应上图1(左左)中情况
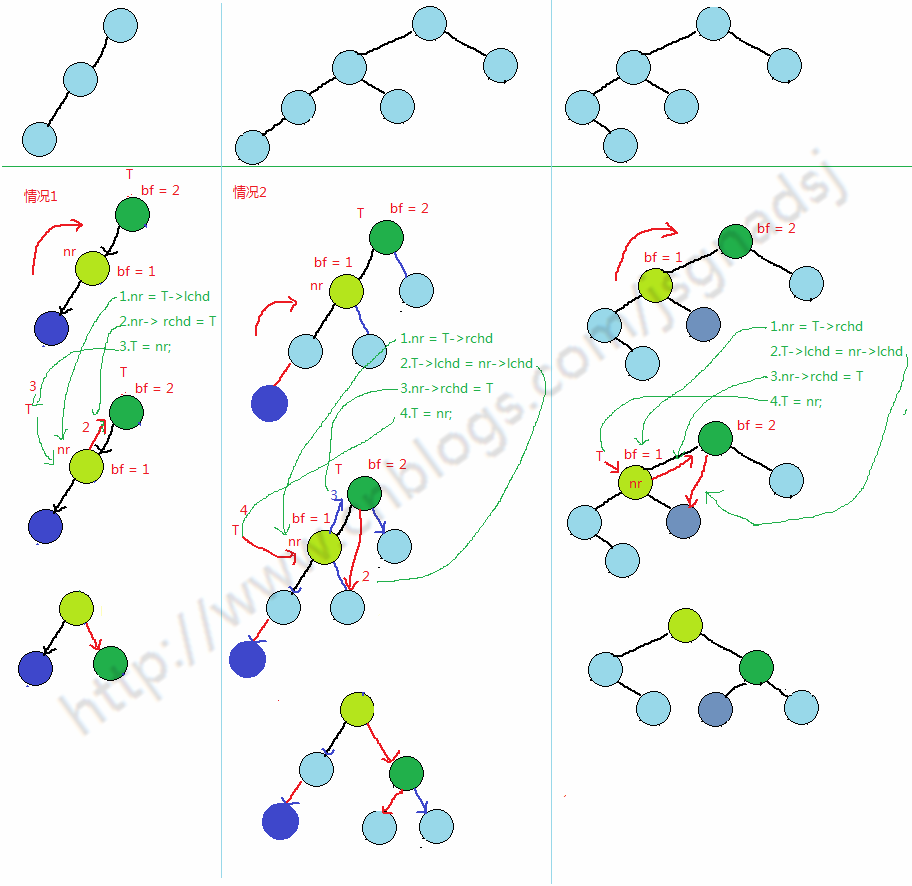
简单左右旋转代码:(只有一次)
void rotateL(pBinTree *p)//左旋转
{
pBinTree r;
r = (*p)->rchd; //r 为新的根
(*p)->rchd = r->lchd;
r->lchd = (*p);
(*p) = r;
} void rotateR(pBinTree *p)//右旋转
{
pBinTree r;
r = (*p)->lchd; //r 为新的根 (*p)->lchd = r->rchd; //新根节点的右孩子附到旧的根结点的左孩子
r->rchd = (*p);
(*p) = r;
}
两次旋转 对应图中3(左右)情况

需要旋转两次简单的左右旋转。基于上面代码就可以实现。
为了方便,AVL引入了BF(平衡因子)来调整树。只要出现非平衡树就调整,把不平衡消除最小的情况。
下面就是通过判断BF来实现调整
void BlanceLeft(pBinTree *p)//从最小非平衡树开始调整
{
pBinTree nR,nRchd;
nR = (*p)->lchd;
switch (nR->bf)
{
case LH: //新插入的结点在左子树
{
(*p)->bf = EH;
nR->bf = EH;
rotateR(p);
break;
}
case RH: //新插入的结点在右子树
{
nRchd = nR->rchd;
switch(nRchd->bf)//增加结点是nR的左孩子还是右孩子?
{
case LH://
{
(*p)->bf = RH;
nR->bf = EH;
break;
}
case EH://
{
(*p)->bf = EH;
nR->bf = EH;
break;
}
case RH:
{
(*p)->bf = EH;
nR->bf = LH;
break;
}
}
nRchd->bf = EH;
rotateL(&((*p)->lchd));
rotateR(p);
}
}
}
void BlanceRight(pBinTree *p)//从最小非平衡树开始调整
{
pBinTree nR,nRchd;
nR = (*p)->rchd; switch (nR->bf){
case RH: //新插入的结点在左子树
{
(*p)->bf = EH;
nR->bf = EH;
rotateL(p);
break;
}
case LH: //新插入的结点在右子树
{
nRchd = nR->lchd;
switch(nRchd->bf)//增加结点是nR的左孩子还是右孩子?
{
case LH://
{
(*p)->bf = EH;
nR->bf = RH;
break;
}
case EH://
{
(*p)->bf = EH;
nR->bf = EH;
break;
}
case RH:
{
(*p)->bf = LH;
nR->bf = EH;
break;
}
}
nRchd->bf = EH;
rotateR(&((*p)->rchd));
rotateL(p);
}
}
}
然后再就是插入算法,这里采用递归的方式插入。
bool InsertAVL(pBinTree *T,int key,bool *taller)
{
if (!*T)
{
*T = (pBinTree)malloc(sizeof(BinTree));
(*T)->data = key;
(*T)->bf = EH;
(*T)->lchd = NULL;
(*T)->rchd = NULL;
*taller = true;
}
else {
if (key == (*T)->data)
{
*taller = false;
return false;
}
if (key < (*T)->data)
{
if (!InsertAVL(&((*T)->lchd),key,taller))
{
return false;
}
if (*taller)
{
switch ((*T)->bf)
{
case LH:
{
BlanceLeft(T);
*taller = false;
break;
}
case EH:
{
(*T)->bf = LH;
*taller = true;
break;
}
case RH:
{
(*T)->bf = EH;
*taller = false;
break;
}
}
}
}
else // key > (*T)->data
{
if (!InsertAVL(&((*T)->rchd),key,taller))
{
return false;
}
if (*taller)
{
switch ((*T)->bf)
{
case LH:
{
(*T)->bf = EH;
*taller = false;
break;
}
case EH:
{
(*T)->bf = RH;
*taller = true;
break;
}
case RH:
{
BlanceRight(T);
*taller = false;
break;
}
} }
}
}
return true;
}
以上的代码用switch case 显得非常的繁琐。会导致删除结点的程序判断BF调整非平衡的步骤更多。
以后添加删除部分代码。
完整代码:
// AVL.cpp : 定义控制台应用程序的入口点。
// #include "stdafx.h" #include
#define LH 1
#define EH 0
#define RH -1 typedef int dataType; typedef struct BinTNode {
dataType data;
int bf;
struct BinTNode *lchd,*rchd;
}BinTree,*pBinTree; void rotateL(pBinTree *p)
{
pBinTree r;
r = (*p)->rchd; //r 为新的根 (*p)->rchd = r->lchd;
r->lchd = (*p);
(*p) = r;
} void rotateR(pBinTree *p)
{
pBinTree r;
r = (*p)->lchd; //r 为新的根 (*p)->lchd = r->rchd; //新根节点的右孩子附到旧的根结点的左孩子
r->rchd = (*p);
(*p) = r;
} void BlanceLeft(pBinTree *p)//从最小非平衡树开始调整
{
pBinTree nR,nRchd;
nR = (*p)->lchd;
switch (nR->bf)
{
case LH: //新插入的结点在左子树
{
(*p)->bf = EH;
nR->bf = EH;
rotateR(p);
break;
}
case RH: //新插入的结点在右子树
{
nRchd = nR->rchd;
switch(nRchd->bf)//增加结点是nR的左孩子还是右孩子?
{
case LH://
{
(*p)->bf = RH;
nR->bf = EH;
break;
}
case EH://
{
(*p)->bf = EH;
nR->bf = EH;
break;
}
case RH:
{
(*p)->bf = EH;
nR->bf = LH;
break;
}
}
nRchd->bf = EH;
rotateL(&((*p)->lchd));
rotateR(p);
}
}
}
void BlanceRight(pBinTree *p)//从最小非平衡树开始调整
{
pBinTree nR,nRchd;
nR = (*p)->rchd; switch (nR->bf){
case RH: //新插入的结点在左子树 {
(*p)->bf = EH;
nR->bf = EH;
rotateL(p);
break;
}
case LH: //新插入的结点在右子树
{
nRchd = nR->lchd;
switch(nRchd->bf)//增加结点是nR的左孩子还是右孩子?
{
case LH://
{
(*p)->bf = EH;
nR->bf = RH;
break;
}
case EH://
{
(*p)->bf = EH;
nR->bf = EH;
break;
}
case RH:
{
(*p)->bf = LH;
nR->bf = EH;
break;
}
}
nRchd->bf = EH;
rotateR(&((*p)->rchd));
rotateL(p);
}
}
} bool InsertAVL(pBinTree *T,int key,bool *taller)
{
if (!*T)
{
*T = (pBinTree)malloc(sizeof(BinTree));
(*T)->data = key;
(*T)->bf = EH;
(*T)->lchd = NULL;
(*T)->rchd = NULL;
*taller = true;
}
else {
if (key == (*T)->data)
{
*taller = false;
return false;
}
if (key < (*T)->data)
{
if (!InsertAVL(&((*T)->lchd),key,taller))
{
return false;
}
if (*taller)
{
switch ((*T)->bf)
{
case LH:
{
BlanceLeft(T);
*taller = false;
break;
}
case EH:
{
(*T)->bf = LH;
*taller = true;
break;
}
case RH:
{
(*T)->bf = EH;
*taller = false;
break;
}
} }
}
else // key > (*T)->data
{
if (!InsertAVL(&((*T)->rchd),key,taller))
{
return false;
}
if (*taller)
{
switch ((*T)->bf)
{
case LH:
{
(*T)->bf = EH;
*taller = false;
break;
}
case EH:
{
(*T)->bf = RH;
*taller = true;
break;
}
case RH:
{
BlanceRight(T);
*taller = false;
break;
}
} }
}
}
return true;
} int _tmain(int argc, _TCHAR* argv[])
{
int a[] = {,,,,,,,,,};
int i;
bool taller;
pBinTree T = NULL; for (i=;i<;i++)
{
InsertAVL(&T,a[i],&taller);
}
getchar();
return ;
}
算法学习记录-查找——平衡二叉树(AVL)的更多相关文章
- 算法学习记录-查找——二叉排序树(Binary Sort Tree)
二叉排序树 也称为 二叉查找数. 它具有以下性质: 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值. 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值. 它的左.右子树也分别 ...
- 算法学习记录-查找——折半查找(Binary Search)
以前有个游戏,一方写一个数字,另一方猜这个数字.比如0-100内一个数字,看谁猜中用的次数少. 这个里面用折半思想猜会大大减少次数. 步骤:(加入数字为9) 1.因为数字的范围是0-100,所以第一次 ...
- Manacher回文串算法学习记录
FROM: http://hi.baidu.com/chenwenwen0210/item/482c84396476f0e02f8ec230 #include<stdio.h> #inc ...
- 算法学习记录-图——最小生成树之Kruskal算法
之前的Prim算法是基于顶点查找的算法,而Kruskal则是从边入手. 通俗的讲:就是希望通过 边的权值大小 来寻找最小生成树.(所有的边称为边集合,最小生成树形成的过程中的顶点集合称为W) 选取边集 ...
- 算法学习记录-图(DFS BFS)
图: 目录: 1.概念 2.邻接矩阵(结构,深度/广度优先遍历) 3.邻接表(结构,深度/广度优先遍历) 图的基本概念: 数据元素:顶点 1.有穷非空(必须有顶点) 2.顶点之间为边(可空) 无向图: ...
- PID算法学习记录
最近做项目需要用到PID算法,这个本来是我的专业(控制理论与控制工程),可是我好像是把这个东西全部还给老师了. 没办法,只好抽时间来学习了. 先占个座,后续将持续更新!
- 算法学习 - 平衡二叉查找树实现(AVL树)
平衡二叉查找树 平衡二叉查找树是非常早出现的平衡树,由于全部子树的高度差不超过1,所以操作平均为O(logN). 平衡二叉查找树和BS树非常像,插入和删除操作也基本一样.可是每一个节点多了一个高度的信 ...
- 算法学习记录-排序——插入排序(Insertion Sort)
插入排序: 在<算法导论>中是这样描述的 这是一个对少量元素进行排序的有效算法.插入排序的工作机理与打牌时候,整理手中的牌做法差不多. 在开始摸牌时,我们的左手是空的,牌面朝下放在桌子上. ...
- 算法学习记录-排序——冒泡排序(Bubble Sort)
冒泡排序应该是最常用的排序方法,我接触的第一个排序算法就是冒泡,老师也经常那这个做例子. 冒泡排序是一种交换排序, 基本思想: 通过两两比较相邻的记录,若反序则交换,知道没有反序的记录为止. 例子: ...
随机推荐
- react框架 Dva & Umi
概念 // http://localhost:3000/ //models import IndexPage from './routes/IndexPage'; import Products fr ...
- 【PyQt5 学习记录】002:添加部件及网格布局
#!/usr/bin/python3 # -*- coding:utf-8 -*- import sys from PySide2.QtWidgets import (QApplication, QW ...
- Linux / mysql: is it safe to copy mysql db files with cp command from one db to another?
Copying is very simple for MyISAM and completely 100% risky (near suicidal) with InnoDB. From your q ...
- 02_Netty实现的Echo服务器和客户端
[Echo服务端] [EchoServer] public class EchoServer { private final int port; public EchoServer(int port) ...
- Binary Tree Inorder/Preorder Traversal 返回中序和前序/遍历二叉树的元素集合
给定一个二叉树,以集合方式返回其中序/先序方式遍历的所有元素. 有两种方法,一种是经典的中序/先序方式的经典递归方式,另一种可以结合栈来实现非递归 Given a binary tree, retur ...
- Python套接字
1.客户端/服务器架构 什么是客户端/服务器架构?对于不同的人来说,它意味着不同的东西,这取决于你问谁以及描述的是软件还是硬件系统.在这两种情况中的任何一种下,前提都很简单:服务器就是一系列硬件或软件 ...
- 安装PHPphp-5.4.4
一.下载PHPphp-5.4.4 [root@aliyun software]# pwd /software[root@aliyun software]# wget http://mirrors.so ...
- JavaScript学习---JavaScript深入学习
对象的概念 对象分类[3种]: ECMScript(JS自己的对象), BOM(浏览器对象) DOM(文档对象,操作HTML的) 11种内置对象: Array ,String ...
- VS 2012 在 windows 8 中无法使用 Deubgger.Lunch() 对服务进行调试
找到了外文资料: Debugger.Launch() not displaying JIT debugger selection popup on Windows 8/8.1 If execu ...
- January 11 2017 Week 2nd Wednesday
One always has time enough, if one will apply it well. 如果你能好好地利用,你总有足够的时间. If you always feel that y ...