Lucene.net的简单使用
一.Lucene.net的简单介绍
1.为什么要使用Lucene.net
使用like的模糊查询,模糊度太低,中间添加几个字就无法查找。同时会造成数据库的全文检索,效率低下,数据库服务器造成太大的压力,Lucenenet只是一个全文检索引擎开发包,并不是一个完整的搜索引擎,不像www.baidu.com这些成熟的搜索引擎,它只是一个开发的框架,可以实现某些产品
2.Lucene.net的作用
就是利用某种分词算法将文本文件进行切词,然后将分好的词放在索引库中,查询的时候从索引库中进行搜索
二.分词
Lucene.net的使用的时候需要对对文本进行分词,具体的分词算法:一元分词,二元分词和基于词库的分词,一元分词的Analyzer在Lucene.net中已经集成,二元分词算法的分析器网上也有很多,但是这两种分析器在实际的应用中作用并不是很大,主要有实际应用的还是按照词库进行分词的分析器,常用的就是盘古分词。引入Lucene.net.dll文件,接下来就这些分词算法进行演示。
一元分词
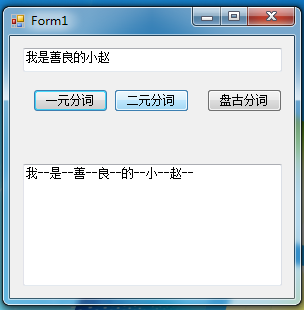
/// <summary>
/// 一元分词
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void button1_Click(object sender, EventArgs e)
{
textBox1.Text = string.Empty;
//分析器
string sentence = textBox2.Text;
if (!string.IsNullOrEmpty(sentence))
{
Analyzer analyzer = new StandardAnalyzer();
TokenStream tokenStream = analyzer.TokenStream("", new StringReader(sentence));
Lucene.Net.Analysis.Token token = null;
while ((token = tokenStream.Next()) != null)
{
textBox1.Text += token.TermText() + "--";
}
}
}
二元分词
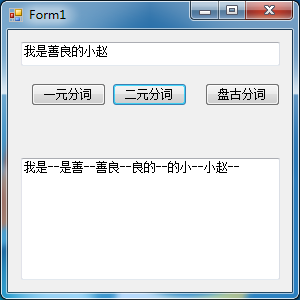
/// <summary>
/// 二元分词 算法分析器是网上写好的类
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void button2_Click(object sender, EventArgs e)
{
textBox1.Text = string.Empty;
string sentence = textBox2.Text;
if (!string.IsNullOrEmpty(sentence))
{
Analyzer analyzer = new CJKAnalyzer();
TokenStream tokenStream = analyzer.TokenStream("", new StringReader(sentence));
Lucene.Net.Analysis.Token token = null;
while ((token = tokenStream.Next()) != null)
{
textBox1.Text += token.TermText() + "--";
}
}
}
盘古分词(此时需要引入盘古分词的两个dll,同时添加票盘古分词的词库文件夹Dict)
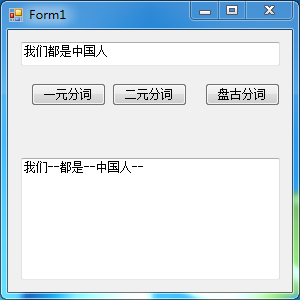
/// <summary>
/// 盘古分词,基于词库的分词
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void button3_Click(object sender, EventArgs e)
{
textBox1.Text = string.Empty;
string sentence = textBox2.Text;
if (!string.IsNullOrEmpty(sentence))
{
Analyzer analyzer = new PanGuAnalyzer();
TokenStream tokenStream = analyzer.TokenStream("", new StringReader(sentence));
Lucene.Net.Analysis.Token token = null;
while ((token = tokenStream.Next()) != null)
{
textBox1.Text += token.TermText() + "--";
}
}
}
盘古分词可能并没有包含你想要的词汇,所以可以通过盘古分词管理工具,对盘古分词的词库进行修改,添加相应的词。
三.使用盘古分词为Lucene.net创建索引库,并实现搜索(粗略的实现,里面一些锁的问题没有解决)
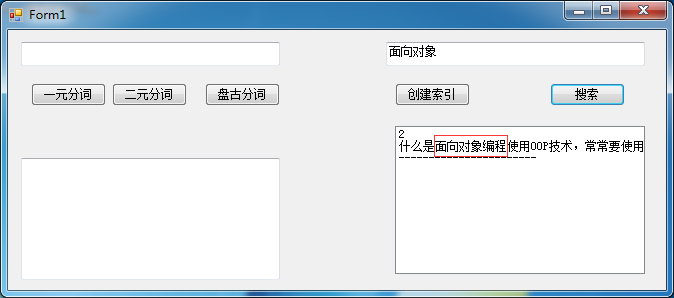
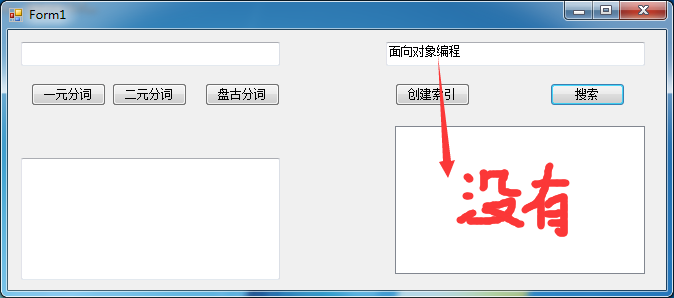
上面进行创建索引的时候,盘古分词的词库中并没有“面向对象编程”这个分词,所以使用它进行查询的时候,Lucene.net的索引库中没有这个词根,可以根据实际情况通过盘古分词管理工具,向词库中添加词汇,然后创建出索引库。
/// <summary>
/// 创建索引
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void button4_Click(object sender, EventArgs e)
{
//将创建的分词内容放在该目录下
string indexPath = @"D:\LuceneTestDir";
//为Lucent.net指定索引文件(打开索引目录) FS指的是就是FileSystem
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NativeFSLockFactory());
//IndexReader:对索引进行读取的类。该语句的作用:判断索引库文件夹是否存在以及索引特征文件是否存在。
bool isUpdate = IndexReader.IndexExists(directory);
if (isUpdate)
{
//同时只能有一段代码对索引库进行写操作。当使用IndexWriter打开directory时会自动对索引库文件上锁。
//如果索引目录被锁定(比如索引过程中程序异常退出),则首先解锁(提示一下:如果我现在正在写着已经加锁了,但是还没有写完,这时候又来一个请求,那么不就解锁了吗?这个问题后面会解决)
if (IndexWriter.IsLocked(directory))
{
IndexWriter.Unlock(directory);
}
}
//向索引库中写索引。这时在这里加锁。同时指定分词算法是盘古分词
//通过writer会将索引写到我们制定的文件夹目录下
IndexWriter writer = new IndexWriter(directory, new PanGuAnalyzer(), !isUpdate, Lucene.Net.Index.IndexWriter.MaxFieldLength.UNLIMITED);
for (int i = ; i <= ; i++)
{
//我们需要添加到Lucene.net索引库的文件
string txt = File.ReadAllText(@"D:\测试文件\" + i + ".txt", System.Text.Encoding.Default);//注意这个地方的编码
Document document = new Document();//表示一篇文档。
//Field.Store.YES:表示是否存储原值。只有当Field.Store.YES在后面才能用doc.Get("number")取出值来.Field.Index. NOT_ANALYZED:不进行分词保存
document.Add(new Field("number", i.ToString(), Field.Store.YES, Field.Index.NOT_ANALYZED)); //Field.Index. ANALYZED:进行分词保存:也就是要进行全文的字段要设置分词 保存(因为要进行模糊查询) //Lucene.Net.Documents.Field.TermVector.WITH_POSITIONS_OFFSETS:不仅保存分词还保存分词的距离。
document.Add(new Field("body", txt, Field.Store.YES, Field.Index.ANALYZED, Lucene.Net.Documents.Field.TermVector.WITH_POSITIONS_OFFSETS));
writer.AddDocument(document); }
writer.Close();//会自动解锁。
directory.Close();//不要忘了Close,否则索引结果搜不到
}
/// <summary>
/// 搜索
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void button5_Click(object sender, EventArgs e)
{
string indexPath = @"D:\LuceneTestDir";
string kw = textBox3.Text;
if (string.IsNullOrEmpty(kw))
{
return;
} FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NoLockFactory());
IndexReader reader = IndexReader.Open(directory, true);
IndexSearcher searcher = new IndexSearcher(reader);
//搜索条件,可以同时制定多个搜索条件
PhraseQuery query = new PhraseQuery();
query.Add(new Term("body", kw));//body中含有kw的文章
query.SetSlop();//多个查询条件的词之间的最大距离.在文章中相隔太远 也就无意义.
//TopScoreDocCollector是盛放查询结果的容器
TopScoreDocCollector collector = TopScoreDocCollector.create(, true);
//根据query查询条件进行查询,查询结果放入collector容器
searcher.Search(query, null, collector);
//得到所有查询结果中的文档,GetTotalHits():表示总条数 TopDocs(300, 20);//表示得到300(从300开始),到320(结束)的文档内容.
//可以用来实现分页功能
ScoreDoc[] docs = collector.TopDocs(, collector.GetTotalHits()).scoreDocs;
this.listBox1.Items.Clear();
for (int i = ; i < docs.Length; i++)
{
//搜索ScoreDoc[]只能获得文档的id,这样不会把查询结果的Document一次性加载到内存中。降低了内存压力,需要获得文档的详细内容的时候通过searcher.Doc来根据文档id来获得文档的详细内容对象Document.
int docId = docs[i].doc;//得到查询结果文档的id(Lucene内部分配的id)
Document doc = searcher.Doc(docId);//找到文档id对应的文档详细信息
this.listBox1.Items.Add(doc.Get("number") + "\n");// 取出放进字段的值
this.listBox1.Items.Add(doc.Get("body") + "\n");
this.listBox1.Items.Add("-----------------------\n");
}
}
Lucene.net的简单使用的更多相关文章
- 使用Lucene.NET实现简单的站内搜索
使用Lucene.NET实现简单的站内搜索 导入Lucene.NET 开发包 Lucene 是apache软件基金会一个开放源代码的全文检索引擎工具包,是一个全文检索引擎的架构,提供了完整的查询引擎和 ...
- lucene创建索引简单示例
利用空闲时间写了一个使用lucene创建索引简单示例, 1.使用maven创建的项目 2.需要用到的jar如下: 废话不多说,直接贴代码如下: 1.创建索引的类(HelloLucene): packa ...
- Lucene就是这么简单
什么是Lucene?? Lucene是apache软件基金会发布的一个开放源代码的全文检索引擎工具包,由资深全文检索专家Doug Cutting所撰写,它是一个全文检索引擎的架构,提供了完整的创建索引 ...
- Lucene介绍及简单入门案例(集成ik分词器)
介绍 Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和 ...
- Lucene中最简单的索引和搜索示例
package com.jiaoyiping.lucene; import org.apache.lucene.analysis.standard.StandardAnalyzer; import o ...
- 【lucene】一个简单的招聘网站的建立
1.建立索引库: 核心代码如下 package com.tabchanj.job.index; import java.util.ArrayList; import java.util.HashMap ...
- 2、Lucene 最简单的使用(小例子)
在了解了Lucene以后,我打算亲手来做一个Lucene的小例子,这个例子只是Lucene最简单的应用:使用Lucene实现标准的英文搜索: 1.下载Lucene 下载Lucene,到Lucene的官 ...
- Lucene 简单手记http://www.cnblogs.com/hoojo/archive/2012/09/05/2671678.html
什么是全文检索与全文检索系统? 全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查 ...
- Lucene的分析资料【转】
Lucene 源码剖析 1 目录 2 Lucene是什么 2.1.1 强大特性 2.1.2 API组成- 2.1.3 Hello World! 2.1.4 Lucene roadmap 3 索引文件结 ...
随机推荐
- 矩阵分解(Matrix Factorization)与推荐系统
转自:http://www.tuicool.com/articles/RV3m6n 对于矩阵分解的梯度下降推导参考如下:
- Hello World! 这是我的第一个 CGI 程序
Hello World! 这是我的第一个 CGI 程序上面的 C++ 程序是一个简单的程序,把它的输出写在 STDOUT 文件上,即显示在屏幕上.在这里,值得注意一点,第一行输出 Content-ty ...
- Blend for Visual Studio 2013
软件开发中为了使设计师和程序员“并行”工作并直接参与到程序的开发中来. 1.在网络程序开发团队中,草图设计后,设计师们可以使用HTML.CSS.JavaScript直接生成UI,程序员则在这个UI产生 ...
- sql 一些题目
这道SQL笔试题你会怎么写(转) 最近面试了一些Senior BI的候选人,行业经验三年到七年不等,起初觉得这个Level的无需准备笔试题,碍于领导执念,就在真实项目中提取5道SQL题目,这里仅单说其 ...
- IIS 使用多个https和通配证书解决方案
环境:OS :WINDOWS 2008 IIS: IIS7 域名:三个二级域名 问题:由于一个网站只支持一个443,但可以通过更改配置得到绑定不同域名.但由于公用证书,所以问题出来.只能为一个二级域名 ...
- C语言----项目构建Make,Automake,CMake
http://blog.csdn.net/dc_726/article/details/48978849
- 第三章 Spring.Net 环境准备和搭建
在前面一章我们介绍了依赖注入,控制反转的概念.接下来我们来真正动手搭建一下Spring.Net的环境,看一下Spring.Net 中的控制反转和依赖注入是什么样子. 3.1 Spring.Net 下 ...
- 几张图轻松理解String.intern()
https://blog.csdn.net/soonfly/article/details/70147205 在翻<深入理解Java虚拟机>的书时,又看到了2-7的 String.inte ...
- JavaScript实现禁用键盘和鼠标的点击事件
编写自己定义的JavaScript函数maskingKeyboard()和rightKey(); maskingKeyboard():禁用键盘 rightKey():禁用鼠标右键 <script ...
- Windows版Nginx启动失败之1113: No mapping for the Unicode character exists in the target multi-byte code page
Windows版Nginx启动一闪,进程中未发现nginx进程,查看nginx日志,提示错误为1113: No mapping for the Unicode character exists in ...