Fast R-CNN论文详解 - CSDN博客
废话不多说,上车吧,少年
paper链接:Fast R-CNN
&创新点
规避R-CNN中冗余的特征提取操作,只对整张图像全区域进行一次特征提取;
用RoI pooling层取代最后一层max pooling层,同时引入建议框信息,提取相应建议框特征;
Fast R-CNN网络末尾采用并行的不同的全连接层,可同时输出分类结果和窗口回归结果,实现了end-to-end的多任务训练【建议框提取除外】,也不需要额外的特征存储空间【R-CNN中这部分特征是供SVM和Bounding-box regression进行训练的】;
采用SVD对Fast R-CNN网络末尾并行的全连接层进行分解,减少计算复杂度,加快检测速度。
&问题是什么
R-CNN网络训练、测试速度都很慢:R-CNN网络中,一张图经由selective search算法提取约2k个建议框【这2k个建议框大量重叠】,而所有建议框变形后都要输入AlexNet CNN网络提取特征【即约2k次特征提取】,会出现上述重叠区域多次重复提取特征,提取特征操作冗余;
R-CNN网络训练、测试繁琐:R-CNN网络训练过程分为ILSVRC 2012样本下有监督预训练、PASCAL VOC 2007该特定样本下的微调、20类即20个SVM分类器训练、20类即20个Bounding-box 回归器训练,该训练流程繁琐复杂;同理测试过程也包括提取建议框、提取CNN特征、SVM分类和Bounding-box 回归等步骤,过于繁琐;
R-CNN网络训练需要大量存储空间:20类即20个SVM分类器和20类即20个Bounding-box 回归器在训练过程中需要大量特征作为训练样本,这部分从CNN提取的特征会占用大量存储空间;
R-CNN网络需要对建议框进行形变操作后【形变为227×227 size】再输入CNN网络提取特征,其实像AlexNet CNN等网络在提取特征过程中对图像的大小并无要求,只是在提取完特征进行全连接操作的时候才需要固定特征尺寸【R-CNN中将输入图像形变为227×227可正好满足AlexNet CNN网络最后的特征尺寸要求】,然后才使用SVM分类器分类,R-CNN需要进行形变操作的问题在Fast R-CNN已经不存在,具体见下。
&如何解决问题
。测试过程
Fast R-CNN的网络结构如下图所示。
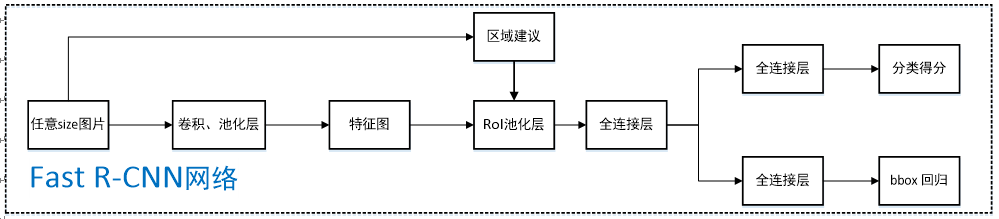
任意size图片输入CNN网络,经过若干卷积层与池化层,得到特征图;
在任意size图片上采用selective search算法提取约2k个建议框;
根据原图中建议框到特征图映射关系,在特征图中找到每个建议框对应的特征框【深度和特征图一致】,并在RoI池化层中将每个特征框池化到H×W【VGG-16网络是7×7】的size;
固定H×W【VGG-16网络是7×7】大小的特征框经过全连接层得到固定大小的特征向量;
第4步所得特征向量经由各自的全连接层【由SVD分解实现】,分别得到两个输出向量:一个是softmax的分类得分,一个是Bounding-box窗口回归;
利用窗口得分分别对每一类物体进行非极大值抑制剔除重叠建议框,最终得到每个类别中回归修正后的得分最高的窗口。
。解释分析
整个测试过程为什么可以只进行一次CNN特征提取操作?
先看R-CNN网络,它首先采用selective search算法提取约2k个建议框,并对所有建议框都进行了CNN特征提取操作,会出现重叠区域多次重复提取特征,这些操作非常耗时、耗空间。事实上我们并不需要对每个建议框都进行CNN特征提取操作,只需要对原始的整张图片进行1次CNN特征提取操作即可,因为selective search算法提取的建议框属于整张图片,因此对整张图片提取出特征图后,再找出相应建议框在特征图中对应的区域,这样就可以避免冗余的特征提取操作,节省大量时间。为什么要将每个建议框对应的特征框池化到H×W 的size?如何实现?
问题4中已经指出像AlexNet CNN等网络在提取特征过程中对图像的大小并无要求,只是在提取完特征进行全连接操作的时候才需要固定特征尺寸,利用这一点,Fast R-CNN可输入任意size图片,并在全连接操作前加入RoI池化层,将建议框对应特征图中的特征框池化到H×W 的size,以便满足后续操作对size的要求;具体如何实现呢?
首先假设建议框对应特征图中的特征框大小为h×w,将其划分H×W个子窗口,每个子窗口大小为h/H×w/W,然后对每个子窗口采用max pooling下采样操作,每个子窗口只取一个最大值,则特征框最终池化为H×W的size【特征框各深度同理】,这将各个大小不一的特征框转化为大小统一的数据输入下一层。为什么要采用SVD分解实现Fast R-CNN网络中最后的全连接层?具体如何实现?
图像分类任务中,用于卷积层计算的时间比用于全连接层计算的时间多,而在目标检测任务中,selective search算法提取的建议框比较多【约2k】,几乎有一半的前向计算时间被花费于全连接层,就Fast R-CNN而言,RoI池化层后的全连接层需要进行约2k次【每个建议框都要计算】,因此在Fast R-CNN中可以采用SVD分解加速全连接层计算;具体如何实现呢?
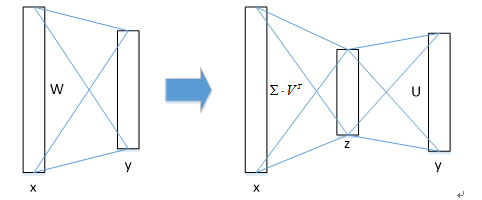
① 物体分类和窗口回归都是通过全连接层实现的,假设全连接层输入数据为x,输出数据为y,全连接层参数为W,尺寸为u×v,那么该层全连接计算为:y=Wx" style="text-align: center; position: relative;">y=Wxy=Wx计算复杂度为u×v;
② 若将W进行SVD分解,并用前t个特征值近似代替,即:
W=U∑VT≈U(u,1:t)⋅∑(1:t,1:t)⋅V(v,1:t)T" style="text-align: center; position: relative;">W=U∑VT≈U(u,1:t)⋅∑(1:t,1:t)⋅V(v,1:t)TW=U∑VT≈U(u,1:t)⋅∑(1:t,1:t)⋅V(v,1:t)T那么原来的前向传播分解成两步:
y=Wx=U⋅(∑⋅VT)⋅x=U⋅z" style="text-align: center; position: relative;">y=Wx=U⋅(∑⋅VT)⋅x=U⋅zy=Wx=U⋅(∑⋅VT)⋅x=U⋅z计算复杂度为u×t+v×t,若t<min(u,v)" style="position: relative;">t<min(u,v)t<min(u,v),则这种分解会大大减少计算量;
在实现时,相当于把一个全连接层拆分为两个全连接层,第一个全连接层不含偏置,第二个全连接层含偏置;实验表明,SVD分解全连接层能使mAP只下降0.3%的情况下提升30%的速度,同时该方法也不必再执行额外的微调操作。
文中仅采用selective search算法提取约2k个候选区域,那候选区域越多越好吗?
文中利用selective search算法提取1k~10k中10种数目【1k,2k…】的候选区域进行训练测试,发现随着候选区域个数的增加,mAP成先增加后缓慢下滑的趋势,这表明更多的候选区域会有损精度;与此同时,作者也做了召回率【所谓召回率即候选区域为真的窗口与Ground Truth的比值【IoU大于阈值即为真】】分析实验,发现随着候选区域个数的增加,召回率并没有和mAP成很好的相关性,而是一直不断增加,也就是说更高的召回率并不意味着更高的mAP;文中也以selective search算法提取的2k个候选区域为基础,每次增加1000 × {2, 4, 6, 8, 10, 32, 45}个密集box【滑动窗口方法】进行训练测试,发现mAP比只有selective search方法的2k候选区域下降幅度更大,最终达到53%。
如何处理尺度不变性问题?即如何使24×24和1080×720的车辆同时在一个训练好的网络中都能正确识别?
文中提及两种方式处理:brute-force(单一尺度)和image pyramids(多尺度)。单一尺度直接在训练和测试阶段将image定死为某种scale,直接输入网络训练就好,然后期望网络自己能够学习到scale-invariance的表达;多尺度在训练阶段随机从图像金字塔【缩放图片的scale得到,相当于扩充数据集】中采样训练,测试阶段将图像缩放为金字塔中最为相似的尺寸进行测试;可以看出,多尺度应该比单一尺度效果好。作者在5.2节对单一尺度和多尺度分别进行了实验,不管哪种方式下都定义图像短边像素为s,单一尺度下s=600【维持长宽比进行缩放】,长边限制为1000像素;多尺度s={480,576,688,864,1200}【维持长宽比进行缩放】,长边限制为2000像素,生成图像金字塔进行训练测试;实验结果表明AlexNet【S for small】、VGG_CNN_M_1024【M for medium】下单一尺度比多尺度mAP差1.2%~1.5%,但测试时间上却快不少,VGG-16【L for large】下仅单一尺度就达到了66.9%的mAP【由于GPU显存限制多尺度无法实现】,该实验证明了深度神经网络善于直接学习尺度不变形,对目标的scale不敏感。
为什么不沿用R-CNN中的形式继续采用SVM进行分类?
为什么R-CNN中采用SVM分类而不直接用CNN网络输出端进行分类已经在R-CNN博客中说明,针对Fast R-CNN,文中分别进行实验并对比了采用SVM和采用softmax的mAP结果,不管AlexNet【S for small】、VGG_CNN_M_1024【M for medium】、VGG-16【L for large】中任意网络,采用softmax的mAP都比采用SVM的mAP高0.1%~0.8%,这是由于softmax在分类过程中引入了类间竞争,分类效果更好;Fast R-CNN去掉了SVM这一步,所有的特征都暂存在显存中,就不需要额外的磁盘空间。
。训练过程
有监督预训练
样本 来源 正样本 ILSVRC 20XX 负样本 ILSVRC 20XX ILSVRC 20XX样本只有类别标签,有1000种物体;
文中采用AlexNet【S for small】、VGG_CNN_M_1024【M for medium】、VGG-16【L for large】这三种网络分别进行训练测试,下面仅以VGG-16举例。特定样本下的微调
样本 比例 来源 正样本 25% 与某类Ground Truth相交IoU∈[0.5,1]的候选框 负样本 75% 与20类Ground Truth相交IoU中最大值∈[0.1,0.5)的候选框 PASCAL VOC数据集中既有物体类别标签,也有物体位置标签,有20种物体;
正样本仅表示前景,负样本仅表示背景;
回归操作仅针对正样本进行;
该阶段训练集扩充方式:50%概率水平翻转;微调前,需要对有监督预训练后的模型进行3步转化:
①RoI池化层取代有监督预训练后的VGG-16网络最后一层池化层;
②两个并行层取代上述VGG-16网络的最后一层全连接层和softmax层,并行层之一是新全连接层1+原softmax层1000个分类输出修改为21个分类输出【20种类+背景】,并行层之二是新全连接层2+候选区域窗口回归层,如下图所示;
③上述网络由原来单输入:一系列图像修改为双输入:一系列图像和这些图像中的一系列候选区域;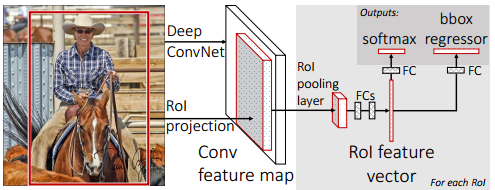
SGD超参数选择:
除了修改增加的层,原有的层参数已经通过预训练方式初始化;
用于分类的全连接层以均值为0、标准差为0.01的高斯分布初始化,用于回归的全连接层以均值为0、标准差为0.001的高斯分布初始化,偏置都初始化为0;
针对PASCAL VOC 2007和2012训练集,前30k次迭代全局学习率为0.001,每层权重学习率为1倍,偏置学习率为2倍,后10k次迭代全局学习率更新为0.0001;
动量设置为0.9,权重衰减设置为0.0005。
。解释分析
Fast R-CNN如何采样进行SGD训练,和R-CNN、SPPnet中SGD采样方式有什么区别和优势?
R-CNN和SPPnet中采用RoI-centric sampling:从所有图片的所有候选区域中均匀取样,这样每个SGD的mini-batch中包含了不同图像的样本,不同图像之间不能共享卷积计算和内存,运算开销大;
Fast R-CNN中采用image-centric sampling: mini-batch采用层次采样,即先对图像采样【N个】,再在采样到的图像中对候选区域采样【每个图像中采样R/N个,一个mini-batch共计R个候选区域样本】,同一图像的候选区域卷积共享计算和内存,降低了运算开销;
image-centric sampling方式采样的候选区域来自于同一图像,相互之间存在相关性,可能会减慢训练收敛的速度,但是作者在实际实验中并没有出现这样的担忧,反而使用N=2,R=128的RoI-centric sampling方式比R-CNN收敛更快。这里解释一下为什么SPPnet不能更新spatial pyramid pooling层前面的卷积层,而只能更新后面的全连接层?
博主没有看过SPPnet的论文,有网友解释说卷积特征是线下计算的,从而无法在微调阶段反向传播误差;另一种解释是,反向传播需要计算每一个RoI感受野的卷积层梯度,通常所有RoI会覆盖整个图像,如果用RoI-centric sampling方式会由于计算too much整幅图像梯度而变得又慢又耗内存。训练数据越多效果越好吗?
实验 训练集 测试集 mAP 实验1 VOC 2007训练集 VOC 2007测试集 66.9% 实验1 VOC 2007+VOC 2012训练集 VOC 2007测试集 70.0% 实验2 VOC 2012训练集 VOC 2010测试集 66.1% 实验2 VOC 2007+VOC 2012训练集+VOC2007测试集 VOC 2010测试集 68.8% 实验3 VOC 2012训练集 VOC 2012测试集 65.7% 实验3 VOC 2007+VOC 2012训练集+VOC2007测试集 VOC 2012测试集 68.4% 文中分别在VOC 2007、VOC 2010、VOC 2012测试集上测试,发现训练数据越多,效果确实更好。这里微调时采用100k次迭代,每40k次迭代学习率都缩小10倍。
哪些层参数需要被微调?
SPPnet论文中采用ZFnet【AlexNet的改进版】这样的小网络,其在微调阶段仅对全连接层进行微调,就足以保证较高的精度,作者文中采用VGG-16【L for large】网路,若仅仅只对全连接层进行微调,mAP会从66.9%降低到61.4%, 所以文中也需要对RoI池化层之前的卷积层进行微调;那么问题来了?向前微调多少层呢?所有的卷积层都需要微调吗?
作者经过实验发现仅需要对conv3_1及以后卷积层【即9-13号卷积层】进行微调,才使得mAP、训练速度、训练时GPU占用显存三个量得以权衡;
作者说明所有AlexNet【S for small】、VGG_CNN_M_1024【M for medium】的实验结果都是从conv2往后微调,所有VGG-16【L for large】的实验结果都是从conv3_1往后微调。Fast R-CNN如何进行多任务训练?多任务训练有效果吗?
Fast R-CNN网络分类损失和回归损失如下图所示【仅针对一个RoI即一类物体说明】,黄色框表示训练数据,绿色框表示输入目标: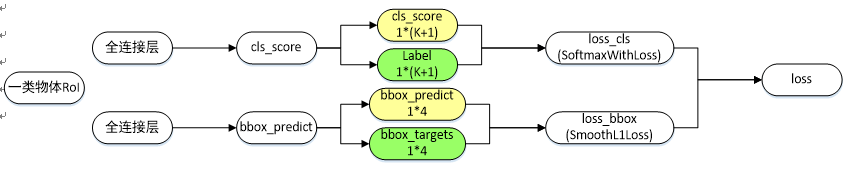
-cls_score层用于分类,输出K+1维数组p,表示属于K类物体和背景的概率;
-bbox_predict层用于调整候选区域位置,输出4*K维数组,也就是说对于每个类别都会训练一个单独的回归器;
-loss_cls层评估分类代价,由真实分类u对应的概率决定:Lcls(p,u)=−logpu" style="text-align: center; position: relative;">Lcls(p,u)=−logpuLcls(p,u)=−logpu-loss_bbox评估回归损失代价,比较真实分类u对应的预测平移缩放参数tu=(txu,tyu,twu,thu) " style="position: relative;">tu=(tux,tuy,tuw,tuh) tu=(txu,tyu,twu,thu) 和真实平移缩放参数v=(vx,vy,vw,vh) " style="position: relative;">v=(vx,vy,vw,vh) v=(vx,vy,vw,vh) 的差距:
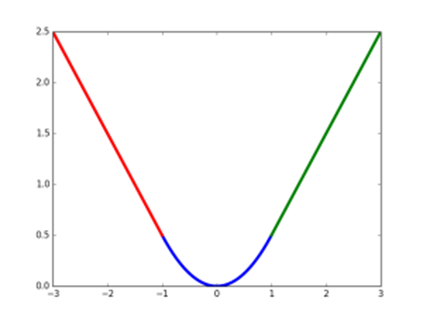
Lloc(tu,v)=∑i∈{x,y,w,h}smoothL1(tiu−vi)" style="text-align: center; position: relative;">Lloc(tu,v)=∑i∈{x,y,w,h}smoothL1(tui−vi)Lloc(tu,v)=∑i∈{x,y,w,h}smoothL1(tiu−vi)smoothL1(x)={0.5x2, |x|<1 |x|−0.5,otherwise" style="text-align: center; position: relative;">smoothL1(x)={0.5x2,|x|−0.5, |x|<1 otherwisesmoothL1(x)={0.5x2, |x|<1 |x|−0.5,otherwisesmooth L1损失函数曲线如下图所示,相比于L2损失函数,其对离群点、异常值不敏感,可控制梯度的量级使训练时不容易跑飞;
结合分类损失和回归损失,Fast R-CNN微调阶段总的损失函数为:
约定u=0为背景分类,那么[u≥1] " style="position: relative;">[u≥1] [u≥1] 函数表示背景候选区域即负样本不参与回归损失,不需要对候选区域进行回归操作;
λ" style="position: relative;">λλ 控制分类损失和回归损失的平衡,文中所有实验λ=1" style="position: relative;">λ=1λ=1;
那多任务训练有效果吗?
首先不看多任务训练效果,至少比起R-CNN其训练方便、简洁。多任务训练考虑各任务间共享卷积层的相互影响,是有潜在可能提高检测效果的;
文中通过实验发现AlexNet【S for small】、VGG_CNN_M_1024【M for medium】、VGG-16【L for large】三种网络采用多任务训练比不采用mAP提高了0.8%~1.1%【测试时不采用Bounding-box regression】。
5. RoI池化层如何进行反向求导训练?
首先看普通max pooling层如何求导,设xi" style="position: relative;">xixi为输入层节点,yi" style="position: relative;">yiyi为输出层节点,那么损失函数L对输入层节点xi" style="position: relative;">xixi的梯度为:

其中判决函数δ(i,j)" style="position: relative;">δ(i,j)δ(i,j)表示输入i节点是否被输出j节点选为最大值输出。不被选中【δ(i,j)=false" style="position: relative;">δ(i,j)=falseδ(i,j)=false】有两种可能:xi" style="position: relative;">xixi不在yi" style="position: relative;">yiyi范围内,或者xi" style="position: relative;">xixi不是最大值。若选中【δ(i,j)=true" style="position: relative;">δ(i,j)=trueδ(i,j)=true 】则由链式规则可知损失函数L相对xi" style="position: relative;">xixi的梯度等于损失函数L相对yi" style="position: relative;">yiyi的梯度×(yi" style="position: relative;">yiyi对xi" style="position: relative;">xixi的梯度->恒等于1),故可得上述所示公式;
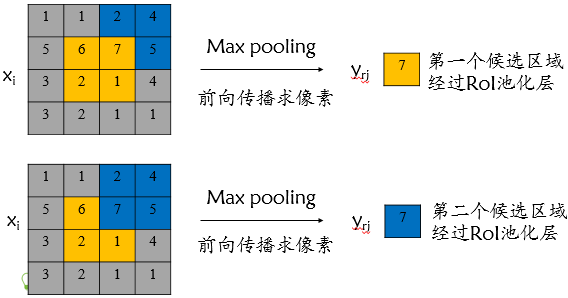
对于RoI max pooling层,设xi" style="position: relative;">xixi为输入层的节点,yri" style="position: relative;">yriyri 为第r个候选区域的第j个输出节点,一个输入节点可能和多个输出节点相关连,如下图所示,输入节点7和两个候选区域输出节点相关连;
该输入节点7的反向传播如下图所示。对于不同候选区域,节点7都存在梯度,所以反向传播中损失函数L对输入层节点xi" style="position: relative;">xixi的梯度为损失函数L对各个有可能的候选区域r【xi" style="position: relative;">xixi被候选区域r的第j个输出节点选为最大值 】输出yri" style="position: relative;">yriyri梯度的累加,具体如下公式所示:
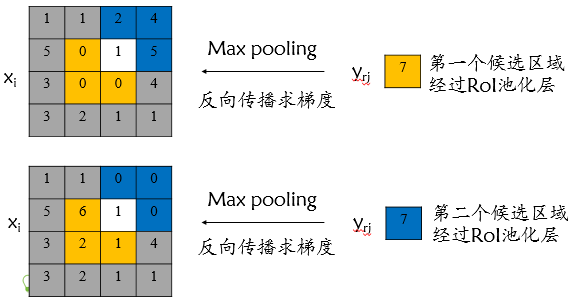
判决函数[i=i∗(r,j)]" style="position: relative;">[i=i∗(r,j)][i=i∗(r,j)]表示i节点是否被候选区域r的第j个输出节点选为最大值输出,若是,则由链式规则可知损失函数L相对xi" style="position: relative;">xixi的梯度等于损失函数L相对yrj" style="position: relative;">yrjyrj的梯度×(yrj" style="position: relative;">yrjyrj对xi" style="position: relative;">xixi的梯度->恒等于1),上图已然解释该输入节点可能会和不同的yrj" style="position: relative;">yrjyrj有关系,故损失函数L相对xi" style="position: relative;">xixi的梯度为求和形式。
&结果怎么样
PASCAL VOC 2007训练集上,使用VGG-16【L for large】网络Fast R-CNN训练时间为9.5h,同等条件下R-CNN需要84h,快8.8倍;
PASCAL VOC 2007测试集上,使用VGG-16【L for large】网络不采用SVD Fast R-CNN测试时间为0.32s/image【不包括候选区域提取时间】,同等条件下R-CNN需要47.0s/image,快146倍;采用SVD测试时间为0.22s/image【不包括候选区域提取时间】,快213倍;
PASCAL VOC 2007测试集上,使用VGG-16【L for large】网络不采用SVD Fast R-CNN mAP为66.9%,同等条件下R-CNN mAP为66.0%;Fast R-CNN采用SVD mAP为66.6%。
&还存在什么问题
Fast R-CNN中采用selective search算法提取候选区域,而目标检测大多数时间都消耗在这里【selective search算法候选区域提取需要2~3s,而提特征分类只需要0.32s】,这无法满足实时应用需求,而且Fast R-CNN并没有实现真正意义上的端到端训练模式【候选区域是使用selective search算法先提取出来的】;
那有没有可能使用CNN直接产生候选区域并对其分类呢?Faster R-CNN框架就是符合这样需求的目标检测框架,请看Faster R-CNN博客。
Fast R-CNN论文详解 - CSDN博客的更多相关文章
- R-CNN论文详解 - CSDN博客
废话不多说,上车吧,少年 paper链接:Rich feature hierarchies for accurate object detection and semantic segmentatio ...
- Faster R-CNN论文详解 - CSDN博客
废话不多说,上车吧,少年 paper链接:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks ...
- python之configparser模块详解--小白博客
configparse模块 一.ConfigParser简介 ConfigParser 是用来读取配置文件的包.配置文件的格式如下:中括号“[ ]”内包含的为section.section 下面为类似 ...
- python之socket模块详解--小白博客
主要是创建一个服务端,在创建服务端的时候,主要步骤如下:创建socket对象socket——>绑定IP地址和端口bind——>监听listen——>得到请求accept——>接 ...
- python之subprocess模块详解--小白博客
subprocess模块 subprocess是Python 2.4中新增的一个模块,它允许你生成新的进程,连接到它们的 input/output/error 管道,并获取它们的返回(状态)码.这个模 ...
- Python爬取CSDN博客文章
0 url :http://blog.csdn.net/youyou1543724847/article/details/52818339Redis一点基础的东西目录 1.基础底层数据结构 2.win ...
- Python采集CSDN博客排行榜数据
文章目录 前言 网络爬虫 搜索引擎 爬虫应用 谨防违法 爬虫实战 网页分析 编写代码 运行效果 反爬技术 前言 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知 ...
- 2016年年终CSDN博客总结
2015年12月1日,结束了4个月的尚观嵌入式培训生涯,经过了几轮重重面试,最终来到了伟易达集团.经过了长达3个月的试用期,正式成为了伟易达集团的助理工程师. 回顾一年来的学习,工作,生活.各种酸甜苦 ...
- spider csdn博客和quantstart文章
spider csdn博客和quantstart文章 功能 提取csdn博客文章 提取quantstart.com 博客文章, Micheal Hall-Moore 创办的网站 特色功能就是: 想把原 ...
随机推荐
- XP 终端服务组件 恢复补丁包 terminal service patch
terminal 终端服务组件恢复包 下载地址(点击) winconnect server xp软件 下载地址(点击)
- makefile--参数传递、条件判断、include (五)
原创博文,转载请标明出处--周学伟http://www.cnblogs.com/zxouxuewei/ 在多个Makefile嵌套调用时,有时我们需要传递一些参数给下一层Makefile.比如我们在顶 ...
- HLS图像处理系列——肤色检測
本博文採用Xilinx HLS 2014.4工具.实现一个肤色检測的模块.当中,本文重点是构建HLS图像处理函数. 新建HLSproject的步骤,本博文不再详述. 本project新建之后,仅仅加入 ...
- php 网络爬虫,爬一下花瓣的图片
今天无聊看在知乎上看到有人写网络爬虫爬图片( ̄▽  ̄) 传送门: 福利 - 不过百行代码的爬虫爬取美女图:https://zhuanlan.zhihu.com/p/24730075 福利 - 不过十行 ...
- 【RF库Collections测试】Remove From Dictionary
Name:Remove From DictionarySource:Collections <test library>Arguments:[ dictionary | *keys ]Re ...
- docker学习-docker安装
win10之外的系统:https://www.docker.com/products/docker-toolbox win10系统: https://www.docker.com/pro ...
- linux系统UDP的socket通信编程2
UDP套接字编程范例: server端代码如下: ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 2 ...
- Win7下使用Putty代替超级终端通过COM串口连接开发板方法
1.如果电脑(笔记本)没有串口接口,则需要使用一个 USB-Serial 转换线,这里使用 prolific usb-serial USB--串口转换线,首先需要在win7上安装对应的 USB--串口 ...
- Oracle里 用sql*plus 登陆时,用户名和密码是多少啊?
Oracle里sql*plus的用户名即system用户,密码是自己设置的密码. 如果密码忘记,可通过如下方法重置. 1.win键+R键,输入cmd,打开命令提示符. 2.输入sqlplus /nol ...
- 图片上传Security Error
jQuery.Uploadify v3.2.js 现在得到的一个原因是跨域 http://www.xuebuyuan.com/848255.html 最近项目中要用文件上传控件,我就想到了Upload ...