将java开发的wordcount程序提交到spark集群上运行
今天来分享下将java开发的wordcount程序提交到spark集群上运行的步骤。
第一个步骤之前,先上传文本文件,spark.txt,然用命令hadoop fs -put spark.txt /spark.txt,即可。
第一:看整个代码视图
打开WordCountCluster.java源文件,修改此处代码:

第二步:
打好jar包,步骤是右击项目文件----RunAs--Run Configurations
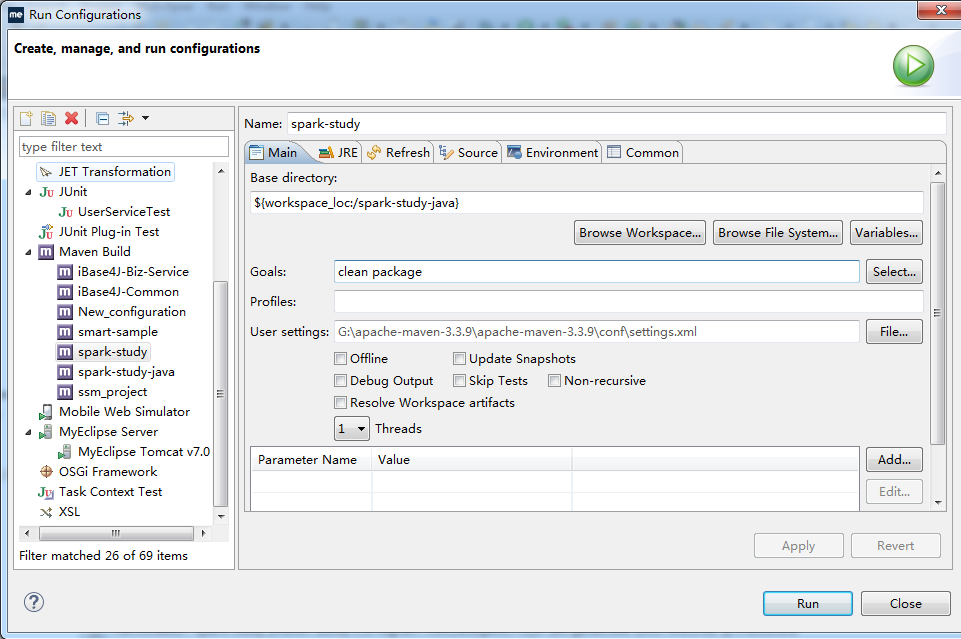
照图填写,然后开始拷贝工程下的jar包,如图,注意是拷贝那个依赖jar包,不是第二个
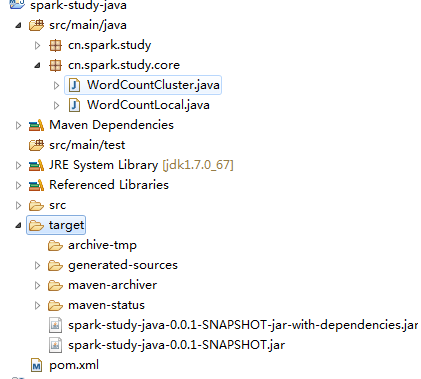
然后将复制到桌面的这个jar包和另外一个文件WordCount.sh上传到平台上,即拖拽到平台上
开始使用上传命令hadoop fs -put spark.txt /spark.txt。
第三步:要启动hadoop集群,启动方式见hadoop配置博文,注意,如果集群里面的datanode或者是namenode之一没有启动,则找到这样一个目录,并删除里面的文件,重新启动即可,如图:即home目录下的文件

打开home目录下的hadoop----dfs-----把里面的两个目录都删除掉,即可
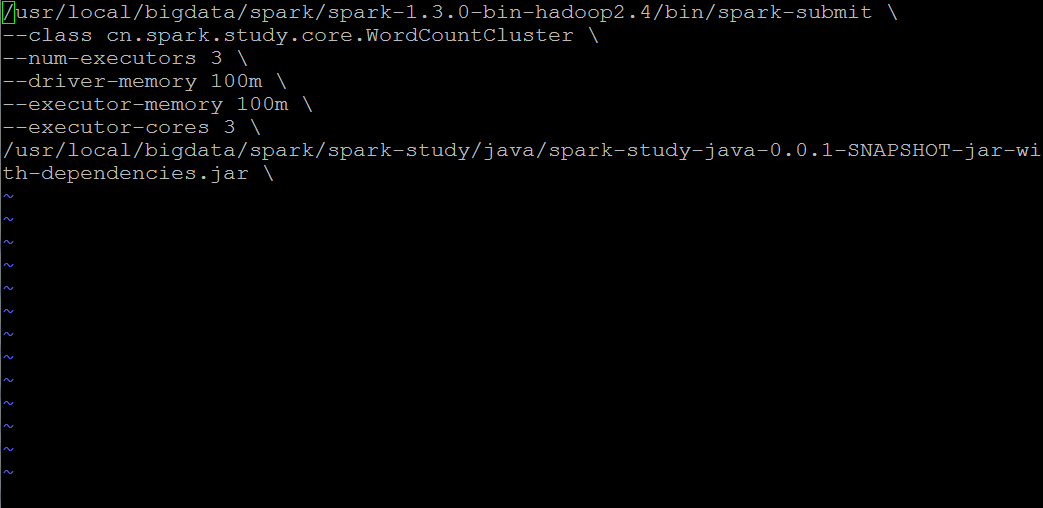
第四步:此时hadoop集群已经启动,然后我们开始修改WordCount.sh配置文件
几点注意:
1,class目录必须对应你的eclipse工程下的项目目录
2,关于spark-submit提交工具,路径要和你的spark集群上面的路径一致 ,这里找的是spark集群下的bin目录里面的文件,不是spark-study下的文件,切记
3,最后一行路径就是你的上传程序jar包到平台上后的路径,注意一定是后缀为jar的文件包,不能上传其它的后缀名,一律无效。
4,注意:修改过本地eclipse的程序文件,一定要生效的话,就要重新上传打包,然后部署。
第五步,启动程序文件,即如下图,在wordcount.sh配置文件的目录下,执行以下命令即可

将java开发的wordcount程序提交到spark集群上运行的更多相关文章
- IntelliJ IDEA编写的spark程序在远程spark集群上运行
准备工作 需要有三台主机,其中一台主机充当master,另外两台主机分别为slave01,slave02,并且要求三台主机处于同一个局域网下 通过命令:ifconfig 可以查看主机的IP地址,如下图 ...
- Eclipse提交代码到Spark集群上运行
Spark集群master节点: 192.168.168.200 Eclipse运行windows主机: 192.168.168.100 场景: 为了测试在Eclipse上开发的代码在Spa ...
- [Spark Core] 在 Spark 集群上运行程序
0. 说明 将 IDEA 下的项目导出为 Jar 包,部署到 Spark 集群上运行. 1. 打包程序 1.0 前提 搭建好 Spark 集群,完成代码的编写. 1.1 修改代码 [添加内容,判断参数 ...
- hadoop 把mapreduce任务从本地提交到hadoop集群上运行
MapReduce任务有三种运行方式: 1.windows(linux)本地调试运行,需要本地hadoop环境支持 2.本地编译成jar包,手动发送到hadoop集群上用hadoop jar或者yar ...
- win10下将spark的程序提交给远程集群中运行
一,开发环境: 操作系统:win19 64位 IDE:IntelliJ IDEA JDK:1.8 scala:scala-2.10.6 集群:linux上cdh集群,其中spark为1.5.2,had ...
- 大数据学习day18----第三阶段spark01--------0.前言(分布式运算框架的核心思想,MR与Spark的比较,spark可以怎么运行,spark提交到spark集群的方式)1. spark(standalone模式)的安装 2. Spark各个角色的功能 3.SparkShell的使用,spark编程入门(wordcount案例)
0.前言 0.1 分布式运算框架的核心思想(此处以MR运行在yarn上为例) 提交job时,resourcemanager(图中写成了master)会根据数据的量以及工作的复杂度,解析工作量,从而 ...
- MapReduce编程入门实例之WordCount:分别在Eclipse和Hadoop集群上运行
上一篇博文如何在Eclipse下搭建Hadoop开发环境,今天给大家介绍一下如何分别分别在Eclipse和Hadoop集群上运行我们的MapReduce程序! 1. 在Eclipse环境下运行MapR ...
- 06、部署Spark程序到集群上运行
06.部署Spark程序到集群上运行 6.1 修改程序代码 修改文件加载路径 在spark集群上执行程序时,如果加载文件需要确保路径是所有节点能否访问到的路径,因此通常是hdfs路径地址.所以需要修改 ...
- 在集群上运行caffe程序时如何避免Out of Memory
不少同学抱怨,在集群的GPU节点上运行caffe程序时,经常出现"Out of Memory"的情况.实际上,如果我们在提交caffe程序到某个GPU节点的同时,指定该节点某个比较 ...
随机推荐
- ECShop全系列版本远程代码执行漏洞复现
前言 问题发生在user.php的display函数,模版变量可控,导致注入,配合注入可达到远程代码执行 漏洞分析 0x01-SQL注入 先看user.php $back_act变量来源于HTTP_R ...
- MySQL事务异常
在做大屏系统的时候,遇到十分奇怪的问题,同样的代码,测试环境插入与更新操作正常,但是上了生产环境之后,插入与更新不生效, 插入数据的时候,主键会自增,但是查询表中没有数据,同样一个@Transacti ...
- python -keras
Numpy 1. np. shape np.reshape np.prod() astype() dtype() From keras.layers import Input Input():用来实例 ...
- NodeJS设置Header解决跨域问题
转载: NodeJS设置Header解决跨域问题 app.all('*', function (req, res, next) { res.header('Access-Control-Allow-O ...
- C语言复习20170826
数组 先定义,再初始化,最后使用. 访问数组中的元素可以采用数组名加下标的方式,下标是从0开始,c并不检查数组下标是否越界,所以在访问数组中的元素时需要注意,需要对数组下标做判断,防止访问数组越界. ...
- mysql的启动,停止与重启
启动mysql:方式一:sudo /etc/init.d/mysql start 方式二:sudo start mysql方式三:sudo service mysql start 停止mysql:方式 ...
- WPF 带水印的密码输入框实现
原文:WPF 带水印的密码输入框实现 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/BYH371256/article/details/835055 ...
- sql语句-6-高级查询
- set get方法诡异的空指针异常
发现原来是我的bean没有实例化 我的一直都是这么实例化的: UserEntity userEntity = null;难怪每次用不了set方法 原来是没有实例化 实例化之后就能正常使用了 UserE ...
- com.genuitec.runtime.generic.jee60 is not defined 导入项目的异常
系统加载工程后,报错Target runtime com.genuitec.runtime.generic.jee60 is not defined,在发布工程的同事电脑上正常 新导入的工程,出问题很 ...