第二百九十六节,python操作redis缓存-Hash哈希类型,可以理解为字典类型
第二百九十六节,python操作redis缓存-Hash哈希类型,可以理解为字典类型
Hash操作,redis中Hash在内存中的存储格式如下图:
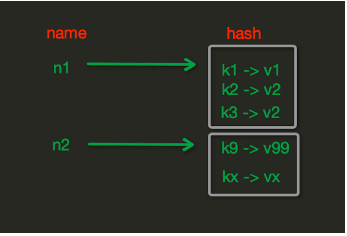
hset(name, key, value)name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
name,redis的name
key,name对应的hash中的key
value,name对应的hash中的value
hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
#!/usr/bin/env python
# -*- coding:utf-8 -*- import redis #导入操作redis模块 pool = redis.ConnectionPool(host='127.0.0.1', port=6379) #配置连接池连接信息 r = redis.Redis(connection_pool=pool) #连接连接池
r.hset('foo', 'k1','v1') #hset(name, key, value)name对应的hash中设置一个键值对(不存在,则创建;否则,修改) f = r.hgetall('foo') #获取名称对应的键和值
print(f)
#返回:{b'k1': b'v1'}
hmset(name, mapping)在name对应的hash中批量设置键值对
name,redis的name
mapping,字典,如:{'k1':'v1', 'k2': 'v2'}
#!/usr/bin/env python
# -*- coding:utf-8 -*- import redis #导入操作redis模块 pool = redis.ConnectionPool(host='127.0.0.1', port=6379) #配置连接池连接信息 r = redis.Redis(connection_pool=pool) #连接连接池
r.hmset('foo',{'k1':'v1', 'k2': 'v2'}) #hmset(name, mapping)在name对应的hash中批量设置键值对 f = r.hgetall('foo') #获取名称对应的键和值
print(f)
#返回:{b'k2': b'v2', b'k1': b'v1'}
hget(name,key)在name对应的hash中获取根据key获取value
#!/usr/bin/env python
# -*- coding:utf-8 -*- import redis #导入操作redis模块 pool = redis.ConnectionPool(host='127.0.0.1', port=6379) #配置连接池连接信息 r = redis.Redis(connection_pool=pool) #连接连接池
r.hmset('foo',{'k1':'v1', 'k2': 'v2'}) #hmset(name, mapping)在name对应的hash中批量设置键值对 # f = r.hgetall('foo') #获取名称对应的键和值 f = r.hget('foo','k1') #hget(name,key)在name对应的hash中获取根据key获取value
print(f)
#返回:b'v1'
hmget(name, keys, *args)在name对应的hash中获取多个key的值
name,reids对应的name
keys,要获取key集合,如:['k1', 'k2', 'k3']
*args,要获取的key,如:k1,k2,k3
如:r.mget('xx', ['k1', 'k2'])
或:r.hmget('xx', 'k1', 'k2')
#!/usr/bin/env python
# -*- coding:utf-8 -*- import redis #导入操作redis模块 pool = redis.ConnectionPool(host='127.0.0.1', port=6379) #配置连接池连接信息 r = redis.Redis(connection_pool=pool) #连接连接池
r.hmset('foo',{'k1':'v1', 'k2': 'v2'}) #hmset(name, mapping)在name对应的hash中批量设置键值对 # f = r.hgetall('foo') #获取名称对应的键和值 f = r.hmget('foo',['k1', 'k2']) #hmget(name, keys, *args)在name对应的hash中获取多个key的值
#或者
f2 = r.hmget('foo','k1', 'k2')
print(f)
print(f2) #返回:
# [b'v1', b'v2']
# [b'v1', b'v2']
hgetall(name)获取name对应hash的所有键值
#!/usr/bin/env python
# -*- coding:utf-8 -*- import redis #导入操作redis模块 pool = redis.ConnectionPool(host='127.0.0.1', port=6379) #配置连接池连接信息 r = redis.Redis(connection_pool=pool) #连接连接池
r.hmset('foo',{'k1':'v1', 'k2': 'v2'}) #hmset(name, mapping)在name对应的hash中批量设置键值对 f = r.hgetall('foo') #获取name对应hash的所有键值
print(f) #返回:
# {b'k1': b'v1', b'k2': b'v2'}
hlen(name)获取name对应的hash中键值对的个数
#!/usr/bin/env python
# -*- coding:utf-8 -*- import redis #导入操作redis模块 pool = redis.ConnectionPool(host='127.0.0.1', port=6379) #配置连接池连接信息 r = redis.Redis(connection_pool=pool) #连接连接池
r.hmset('foo',{'k1':'v1', 'k2': 'v2'}) #hmset(name, mapping)在name对应的hash中批量设置键值对 # f = r.hgetall('foo') #获取name对应hash的所有键值 f = r.hlen('foo') #hlen(name)获取name对应的hash中键值对的个数
print(f) #返回:
#
hkeys(name)获取name对应的hash中所有的key的值
#!/usr/bin/env python
# -*- coding:utf-8 -*- import redis #导入操作redis模块 pool = redis.ConnectionPool(host='127.0.0.1', port=6379) #配置连接池连接信息 r = redis.Redis(connection_pool=pool) #连接连接池
r.hmset('foo',{'k1':'v1', 'k2': 'v2'}) #hmset(name, mapping)在name对应的hash中批量设置键值对 # f = r.hgetall('foo') #获取name对应hash的所有键值 f = r.hkeys('foo') #hkeys(name)获取name对应的hash中所有的key
print(f) #返回:
# [b'k2', b'k1']
hvals(name)获取name对应的hash中所有的value的值
#!/usr/bin/env python
# -*- coding:utf-8 -*- import redis #导入操作redis模块 pool = redis.ConnectionPool(host='127.0.0.1', port=6379) #配置连接池连接信息 r = redis.Redis(connection_pool=pool) #连接连接池
r.hmset('foo',{'k1':'v1', 'k2': 'v2'}) #hmset(name, mapping)在name对应的hash中批量设置键值对 # f = r.hgetall('foo') #获取name对应hash的所有键值 f = r.hvals('foo') #hvals(name)获取name对应的hash中所有的value的值
print(f) #返回:
# [b'v2', b'v1']
hexists(name, key)检查name对应的hash是否存在当前传入的key
#!/usr/bin/env python
# -*- coding:utf-8 -*- import redis #导入操作redis模块 pool = redis.ConnectionPool(host='127.0.0.1', port=6379) #配置连接池连接信息 r = redis.Redis(connection_pool=pool) #连接连接池
r.hmset('foo',{'k1':'v1', 'k2': 'v2'}) #hmset(name, mapping)在name对应的hash中批量设置键值对 # f = r.hgetall('foo') #获取name对应hash的所有键值 f = r.hexists('foo','k1') #hexists(name, key)检查name对应的hash是否存在当前传入的key
print(f) #返回:
#True
hdel(name,*keys)将name对应的hash中指定key的键值对删除
#!/usr/bin/env python
# -*- coding:utf-8 -*- import redis #导入操作redis模块 pool = redis.ConnectionPool(host='127.0.0.1', port=6379) #配置连接池连接信息 r = redis.Redis(connection_pool=pool) #连接连接池
r.hmset('foo',{'k1':'v1', 'k2': 'v2'}) #hmset(name, mapping)在name对应的hash中批量设置键值对 r.hdel('foo','k1') #hdel(name,*keys)将name对应的hash中指定key的键值对删除 f = r.hgetall('foo') #获取name对应hash的所有键值
print(f) #返回:
#{b'k2': b'v2'}
hincrby(name, key, amount=1)自增整数,name对应的hash中的指定key的值,不存在则创建key=amount
name,redis中的name
key, hash对应的key
amount,自增数(整数)
#!/usr/bin/env python
# -*- coding:utf-8 -*- import redis #导入操作redis模块 pool = redis.ConnectionPool(host='127.0.0.1', port=6379) #配置连接池连接信息 r = redis.Redis(connection_pool=pool) #连接连接池
r.hmset('foo',{'k1':'', 'k2': 'v2'}) #hmset(name, mapping)在name对应的hash中批量设置键值对 r.hincrby('foo','k1',amount=1) #hincrby(name, key, amount=1)自增整数,name对应的hash中的指定key的值,不存在则创建key=amount f = r.hgetall('foo') #获取name对应hash的所有键值
print(f) #返回:
#{b'k1': b'2', b'k2': b'v2'}
hincrbyfloat(name, key, amount=1.0)自增浮点数 name对应的hash中的指定key的值,不存在则创建key=amount
name,redis中的name
key, hash对应的key
amount,自增数(浮点数)
#!/usr/bin/env python
# -*- coding:utf-8 -*- import redis #导入操作redis模块 pool = redis.ConnectionPool(host='127.0.0.1', port=6379) #配置连接池连接信息 r = redis.Redis(connection_pool=pool) #连接连接池
r.hmset('foo',{'k1':'1', 'k2': 'v2'}) #hmset(name, mapping)在name对应的hash中批量设置键值对 r.hincrbyfloat('foo','k1',amount=1.2) #hincrbyfloat(name, key, amount=1.0)自增浮点数 name对应的hash中的指定key的值,不存在则创建key=amount f = r.hgetall('foo') #获取name对应hash的所有键值
print(f) #返回:
#{b'k1': b'2.2', b'k2': b'v2'}
hscan(name, cursor=0, match=None, count=None)增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而防止内存被撑爆
name,redis的name
cursor,游标(基于游标分批取获取数据)
match,匹配指定key,默认None 表示所有的key
count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
如:
第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None)
第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None)
...
直到返回值cursor的值为0时,表示数据已经通过分片获取完毕
#!/usr/bin/env python
# -*- coding:utf-8 -*- import redis #导入操作redis模块 pool = redis.ConnectionPool(host='127.0.0.1', port=6379) #配置连接池连接信息 r = redis.Redis(connection_pool=pool) #连接连接池
r.hmset('foo',{'k1':'', 'k2': 'v2','m2':'mm'}) #hmset(name, mapping)在name对应的hash中批量设置键值对 cursor1, data1 = r.hscan('foo',cursor=0,match='*2',count=None) #获取name对应的键,以2结尾的键
print(cursor1, data1) #返回两个值,第一个是获取的游标位置,第二个是获取到的数据 cursor2, data2 = r.hscan('foo',cursor=cursor1,match='*2',count=None) #第二次获取,游标使用第一次返回的游标位置
print(cursor2, data2) #返回:
# 0 {b'm2': b'mm', b'k2': b'v2'}
# 0 {b'm2': b'mm', b'k2': b'v2'}
hscan_iter(name, match=None, count=None)利用yield封装hscan创建生成器,实现分批去redis中获取数据
match,匹配指定key,默认None 表示所有的key
count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
#!/usr/bin/env python
# -*- coding:utf-8 -*- import redis #导入操作redis模块 pool = redis.ConnectionPool(host='127.0.0.1', port=6379) #配置连接池连接信息 r = redis.Redis(connection_pool=pool) #连接连接池
r.hmset('foo',{'k1':'', 'k2': 'v2','m2':'mm'}) #hmset(name, mapping)在name对应的hash中批量设置键值对 for item in r.hscan_iter('foo'):
print(item) #返回:
# (b'm2', b'mm')
# (b'k2', b'v2')
# (b'k1', b'1')
哈希类型设置过期时间
哈希类型只能将整个哈希表设置过期时间,过期后name对应里面的所有键值对就过期了
expire(name,过期时间秒)设置哈希表过期时间
#!/usr/bin/env python
# -*- coding:utf-8 -*- import redis #导入操作redis模块 pool = redis.ConnectionPool(host='127.0.0.1', port=6379) #配置连接池连接信息 r = redis.Redis(connection_pool=pool) #连接连接池
r.hmset('foo',{'k1':'', 'k2': 'v2','m2':'mm'}) #hmset(name, mapping)在name对应的hash中批量设置键值对 r.expire('foo',10) #expire(name,过期时间秒)设置哈希表过期时间
exists(name)判断一个哈希名称是否存在
#!/usr/bin/env python
# -*- coding:utf-8 -*- import redis #导入操作redis模块 pool = redis.ConnectionPool(host='127.0.0.1', port=6379) #配置连接池连接信息 r = redis.Redis(connection_pool=pool) #连接连接池
r.hmset('foo',{'k1':'', 'k2': 'v2','m2':'mm'}) #hmset(name, mapping)在name对应的hash中批量设置键值对 ret = r.exists('foo') #exists(name)判断一个哈希名称是否存在
print(ret)
#返回
#True
Hash哈希类型结合cookie,实现session
session封装模块
#!/usr/bin/env python
#coding:utf-8 import hashlib #导入md5加密模块
import time #导入时间模块
import redis #导入操作redis缓存模块 pool = redis.ConnectionPool(host='127.0.0.1', port=6379) #配置连接池连接信息 r = redis.Redis(connection_pool=pool) #连接连接池 class Session:
def __init__(self,_self):
"""
self._self = _self 接收创建Session时传进来的对象,也就是继承对象
self.cookie 设置self.cookie名称
self.guo_qi 设置cookie和Redis过期时间
self.sui_ji 接收随机密串
"""
self._self = _self
self.cookie = "_session_"
self.guo_qi = 60
self.redis_guo_qi = self.guo_qi
self.cookie_guo_qi = time.time() + self.guo_qi
self.sui_ji = self.suiji_str @property # 声明特性方法,执行方法是不用写括号
def suiji_str(self):
"""
返回值:随机密串
uiji_str 生成随机密串方法
"""
obj = hashlib.md5()
obj.update(bytes(str(time.time()), encoding='utf-8'))
random_str = obj.hexdigest()
return random_str def chuang_jian(self):
"""
返回值:无
chuang_jian() 创建浏览器cookie和生成Redis缓冲哈希表
"""
self._self.set_cookie(self.cookie, self.sui_ji, expires=self.cookie_guo_qi)
r.hset(self.sui_ji, 'deng_lu_zhuang_tai', None)
r.expire(self.sui_ji, self.redis_guo_qi) def __setitem__(self, key, value):
"""
返回值:无
接收键和值设置cookie值对应在Redis缓存的哈希表名称里的键值对
使用方式:
session对象[键]=值,如:session['deng_lu_zhuang_tai'] = True
"""
if not r.exists(self._self.get_cookie(self.cookie)):
self.chuang_jian()
r.hset(self.sui_ji, key, value)
if r.exists(self._self.get_cookie(self.cookie)):
r.hset(self._self.get_cookie(self.cookie), key, value) def __getitem__(self,key):
"""
使用方法:Session对象[xxx]
功能:获取cookie对应Redis缓存里哈希表名称里的指定键的值,键为接收到参数的值,存在返回值,不存在返回None
"""
if not r.exists(self._self.get_cookie(self.cookie)):
return None
else:
fanui = r.hget(self._self.get_cookie(self.cookie), key)
if not fanui:
return None
else:
return fanui.decode("utf-8")
Tornado框架逻辑处理
#!/usr/bin/env python
#coding:utf-8 import tornado.ioloop
import tornado.web #导入tornado模块下的web文件
import session as se #导入Session模块 class indexHandler(tornado.web.RequestHandler): #定义一个类,继承tornado.web下的RequestHandler类
def get(self): #get()方法,接收get方式请求
session = se.Session(self)
if session['deng_lu_zhuang_tai']: #判断当前用户session里的登录状态
self.render("index.html") # 显示index.html文件 #显示查看页面
else:
self.redirect("/dlu") class dluHandler(tornado.web.RequestHandler):
def get(self):
session = se.Session(self)
if session['deng_lu_zhuang_tai']: #判断当前用户session里的登录状态
self.redirect("/index") #跳转查看页面
else:
self.render("dlu.html") def post(self):
session = se.Session(self)
if session['deng_lu_zhuang_tai']:
self.redirect("/index")
else:
yong_hu_ming = self.get_argument('yhm') #接收用户输入的登录账号
mi_ma = self.get_argument('mim') #接收用户输入的登录密码
session['yong_hu_ming'] = yong_hu_ming
session['mi_ma'] = mi_ma
session['deng_lu_zhuang_tai'] = True
self.redirect("/index") settings = { #html文件归类配置,设置一个字典
"template_path":"views", #键为template_path固定的,值为要存放HTML的文件夹名称
"static_path":"statics", #键为static_path固定的,值为要存放js和css的文件夹名称
"cookie_secret":"61oETzKXQAGaYdkL5gEmGeJJY",
} #路由映射
application = tornado.web.Application([ #创建一个变量等于tornado.web下的Application方法
(r"/index", indexHandler), #判断用户请求路径后缀是否匹配字符串index,如果匹配执行MainHandler方法
(r"/dlu", dluHandler), ],**settings) #将html文件归类配置字典,写在路由映射的第二个参数里 if __name__ == "__main__":
#内部socket运行起来
application.listen(8888) #设置端口
tornado.ioloop.IOLoop.instance().start()
实现用户登录后,每次访问一个页面让Hash哈希表和合cookie过期时间累加
在Tornado框架逻辑处理,配置好html模板可以调用的py模块
在py模块定义一个执行函数,函数里获取到客户cookie值,根据cookie值找到Redis里对应的哈希表
将cookie时间累加,在将Redis里对应的哈希表时间累加
最后在网站的html模板通用区域执行这个函数实现过期时间累加
第二百九十六节,python操作redis缓存-Hash哈希类型,可以理解为字典类型的更多相关文章
- 第二百九十八节,python操作redis缓存-Set集合类型,可以理解为不能有重复元素的列表
python操作redis缓存-Set集合类型,可以理解为不能有重复元素的列表 sadd(name,values)name对应的集合中添加元素 #!/usr/bin/env python # -*- ...
- 第二百九十五节,python操作redis缓存-字符串类型
python操作redis缓存-字符串类型 首先要安装redis-py模块 python连接redis方式,有两种连接方式,一种是直接连接,一张是通过连接池连接 注意:以后我们都用的连接池方式连接,直 ...
- 第二百九十九节,python操作redis缓存-SortSet有序集合类型,可以理解为有序列表
python操作redis缓存-SortSet有序集合类型,可以理解为有序列表 有序集合,在集合的基础上,为每元素排序:元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值, ...
- 第二百九十七节,python操作redis缓存-List类型,可以理解为列表
python操作redis缓存-List类型,可以理解为列表,是可以有重复元素的列表 List操作,redis中的List在在内存中按照一个name对应一个List来存储.如图: lpush(name ...
- 第三百零一节,python操作redis缓存-管道、发布订阅
python操作redis缓存-管道.发布订阅 一.管道 redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pi ...
- 第三百九十六节,Django+Xadmin打造上线标准的在线教育平台—其他插件使用说,自定义列表页上传插件
第三百九十六节,Django+Xadmin打造上线标准的在线教育平台—其他插件使用说,自定义列表页上传插件 设置后台列表页面字段统计 在当前APP里的adminx.py文件里的数据表管理器里设置 ag ...
- Python操作redis系列以 哈希(Hash)命令详解(四)
# -*- coding: utf-8 -*- import redis #这个redis不能用,请根据自己的需要修改 r =redis.Redis(host=") 1. Hset 命令用于 ...
- 第三百节,python操作redis缓存-其他常用操作,用于操作redis里的数据name,不论什么数据类型
python操作redis缓存-其他常用操作,用于操作redis里的数据name,不论什么数据类型 delete(*names)根据删除redis中的任意数据类型 #!/usr/bin/env pyt ...
- python操作Redis缓存
python操作Redis缓存 https://www.cnblogs.com/guotianbao/p/8683037.html 学习资料:电子书资源 联系邮箱:gmu1592618@gmail.c ...
随机推荐
- ArraySegmentSample
class Program { static void Main() { , , , , , }; , , , , , , }; ] { , ), , ) }; var sum = SumOfSegm ...
- starUML破解方法(Windows10 & MAC)
安装好,打开安装目录,依次找到[www\license\node],找到名为[LicenseManagerDomain]的js文件,打开它,在第25行位置插入以下几句代码: return { name ...
- 使用xshell远程登录ubuntu使用vi编辑不能使用删除键方向键
近期安装了xshell,远程登录上ubuntu后,在插入模式下,按删除键没有任何反应,按方向键分别打印出A.B.C.D,每个字符一行. 这是因为ubuntu初始化安装的是vi的tiny版本,解决办法安 ...
- scrapy 的一个例子
1.目标: scrapy 是一个爬虫构架,现用一个简单的例子来讲解,scrapy 的使用步骤 2.创建一个scrapy的项目: 创建一个叫firstSpider的项目,命令如下: scrapy sta ...
- GNU的strong symbol和weak symbol
首先,同样的原型的两个函数在连个不同的c文件中都有定义,把这两个c文件编译.连接在一起,也没有什么错误.原因就是因为,gcc中有一个strong symbol和weak symbol的概念.默认函数定 ...
- c语言中使用宏,需要注意的的几点
使用#define来定义一些宏,进行一些简洁的替换甚至一些带参数的宏,在linux c代码中很常见,说明它很好.很有用, 但是它也有一些复杂的规矩和陷阱需要注意,下面我记录一些,仅供参考. 1.当使用 ...
- [na][tools]tcp/udp连通性测试
一 端口连通性测试意义 目的端可以使用nc来临时开一个端口,客户端用telnet来连接测试 测试网络端口可达性,确保给某些使用特定端口的app做链路连通性检测.使它们能够正常的运行起来. 二 测试方法 ...
- 在windows下codeblocks中配置pthread库
转自:http://blog.csdn.net/u013172314/article/details/50846198 如果添加方法不正确,可能会出现pthread_create’未定义的引用,所以下 ...
- 关于locate这个NB命令我不得不深入的学习
先看看locate的安装包和生成的文件: [root@NB mlocate]# which locate /usr/bin/locate [root@NB mlocate]# rpm -qf /usr ...
- CCMotionStreak(一)
void MotionStreakTest1::onEnter() { MotionStreakTest::onEnter(); CCSize s = CCDirector::sharedDirect ...