hadoop MapReduce 入门
原创播客,如需转载请注明出处。原文地址:http://www.cnblogs.com/crawl/p/7687120.html
----------------------------------------------------------------------------------------------------------------------------------------------------------
笔记中提供了大量的代码示例,需要说明的是,大部分代码示例都是本人所敲代码并进行测试,不足之处,请大家指正~
本博客中所有言论仅代表博主本人观点,若有疑惑或者需要本系列分享中的资料工具,敬请联系 qingqing_crawl@163.com
-----------------------------------------------------------------------------------------------------------------------------------------------------------
前言:这一个月实在是抽不出空来写博客了,最近在为学校开发网上办事大厅,平时还要上课,做任务,很忙,压力也很大,终于在本月的最后一天抽出了点时间。其实,这一篇播客一直在我的草稿箱中,LZ 本来想先仔细写一写 Hadoop
伪分布式的部署安装,然后介绍一些 HDFS 的内容再来介绍 MapReduce,是在是没有抽出空,今天就简单入门一下 MapReduce 吧。
一、MapReduce 概述
1.MapReduce 是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题.
2.MapReduce 由两个阶段组成:Map和Reduce,用户只需要实现map()和reduce()两个函数,即可实现分布式计算
二、具体实现
1.先来看一下 Eclipse 中此应用的包结构

2.创建 map 的任务处理类:WCMapper

/*
* 1.Mapper 类的四个泛型中,前两个指定 mapper 输入数据的类型,后两个指定 mapper 输出数据的类型
* KEYIN 是输入的 key 的类型,VALUEIN 是输入的 value 的类型
* KEYOUT 是输出的 key 的类型,VALUEOUT 是输出的 value 的类型
* 2.map 和 reduce 的数据的输入输出都是以 key-value 对的形式封装的
* 3.默认情况下,框架传递给我们的 mapper 的输入数据中,key 是要处理的文本中一行的起始偏移量,为 Long 类型,
* 这一行的内容为 value,为 String 类型的
* 4.后两个泛型的赋值需要我们结合实际情况
* 5.为了在网络中传输时序列化更高效,Hadoop 把 Java 中的 Long 封装为 LongWritable, 把 String 封装为 Text
*/
public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable> { //重写 Mapper 中的 map 方法,MapReduce 框架每读一行数据就调用一次此方法
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//书写具体的业务逻辑,业务要处理的数据已经被框架传递进来,就是方法的参数中的 key 和 value
//key 是这一行数据的起始偏移量,value 是这一行的文本内容 //1.将 Text 类型的一行的内容转为 String 类型
String line = value.toString(); //2.使用 StringUtils 以空格切分字符串,返回 String[]
String[] words = StringUtils.split(line, " "); //3.循环遍历 String[],调用 context 的 writer()方法,输出为 key-value 对的形式
//key:单词 value:1
for(String word : words) {
context.write(new Text(word), new LongWritable(1));
} } }
2.创建 reduce 的任务处理类:WCReducer:
/*
* 1.Reducer 类的四个泛型中,前两个输入要与 Mapper 的输出相对应。输出需要联系具体情况自定义
*/
public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable> { //框架在 map 处理完之后,将所有的 kv 对缓存起来,进行分组,然后传递一个分组(<key,{values}>,例如:<"hello",{1,1,1,1}>),
//调用此方法
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context)throws IOException, InterruptedException { //1.定义一个计数器
long count = 0; //2.遍历 values的 list,进行累加求和
for(LongWritable value : values) {
//使用 LongWritable 的 get() 方法,可以将 一个 LongWritable 类型转为 Long 类型
count += value.get();
} //3.输出这一个单词的统计结果
context.write(key, new LongWritable(count));
} }
3.创建一个类,用来描述一个特定的作业:WCRunner,(此类了LZ没有按照规范的模式写)
/**
* 此类用来描述一个特定的作业
* 例:1.该作业使用哪个类作为逻辑处理中的 map,哪个作为 reduce
* 2.指定该作业要处理的数据所在的路径
* 3.指定该作业输出的结果放到哪个路径
*/
public class WCRunner { public static void main(String[] args) throws Exception { //1.获取 Job 对象:使用 Job 静态的 getInstance() 方法,传入 Configuration 对象
Configuration conf = new Configuration();
Job wcJob = Job.getInstance(conf); //2.设置整个 Job 所用的类的 jar 包:使用 Job 的 setJarByClass(),一般传入 当前类.class
wcJob.setJarByClass(WCRunner.class); //3.设置本 Job 使用的 mapper 和 reducer 的类
wcJob.setMapperClass(WCMapper.class);
wcJob.setReducerClass(WCReducer.class); //4.指定 reducer 输出数据的 kv 类型 注:若 mapper 和 reducer 的输出数据的 kv 类型一致,可以用如下两行代码设置
wcJob.setOutputKeyClass(Text.class);
wcJob.setOutputValueClass(LongWritable.class); //5.指定 mapper 输出数据的 kv 类型
wcJob.setMapOutputKeyClass(Text.class);
wcJob.setMapOutputValueClass(LongWritable.class); //6.指定原始的输入数据存放路径:使用 FileInputFormat 的 setInputPaths() 方法
FileInputFormat.setInputPaths(wcJob, new Path("/wc/srcdata/")); //7.指定处理结果的存放路径:使用 FileOutputFormat 的 setOutputFormat() 方法
FileOutputFormat.setOutputPath(wcJob, new Path("/wc/output/")); //8.将 Job 提交给集群运行,参数为 true 表示显示运行状态
wcJob.waitForCompletion(true); } }
4.将此项目导出为 jar 文件
步骤:右击项目 ---> Export ---> Java ---> JAR file --->指定导出路径(我指定的为:e:\wc.jar) ---> Finish
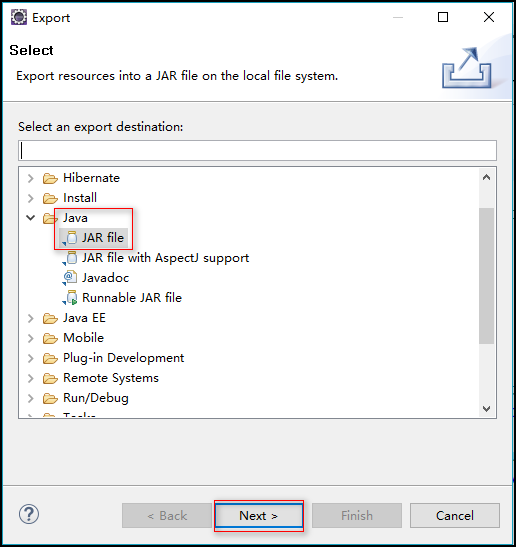
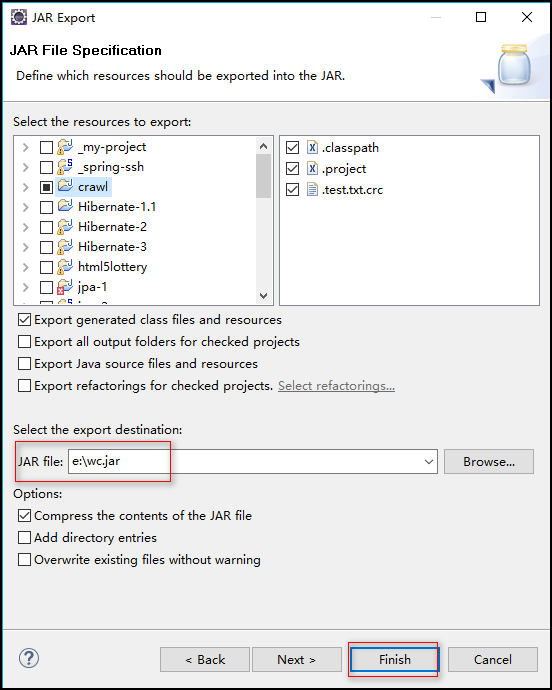
5.将导出的 jar 包上传到 linux 上
LZ使用的方法是:在 SecureCRT 客户端中使用 Alt + p 快捷键打开上传文件的终端,输入 put e"\wc.jar 即可上传

6.创建初始测试文件:words.log
命令: vi words.log 自己输入测试数据即可

7.在 hdfs 中创建存放初始测试文件 words.log 的目录:我们在 WCRunner 中指定的是 /wc/srcdata/
命令:
[hadoop@crawl ~]$ hadoop fs -mkdir /wc
[hadoop@crawl ~]$ hadoop fs -mkdir /wc/srcdata
8.将初始测试文件 words.log 上传到 hdfs 的相应目录
命令:[hadoop@crawl ~]$ hadoop fs -put words.log /wc/srcdata
9.运行 jar 文件
命令:hadoop jar wc.jar com.software.hadoop.mr.wordcount.WCRunner
此命令为 hadoop jar wc.jar 加上 WCRunner类的全类名,程序的入口为 WCRunner 内的 main 方法,运行完此命令便可以看到输出日志信息:
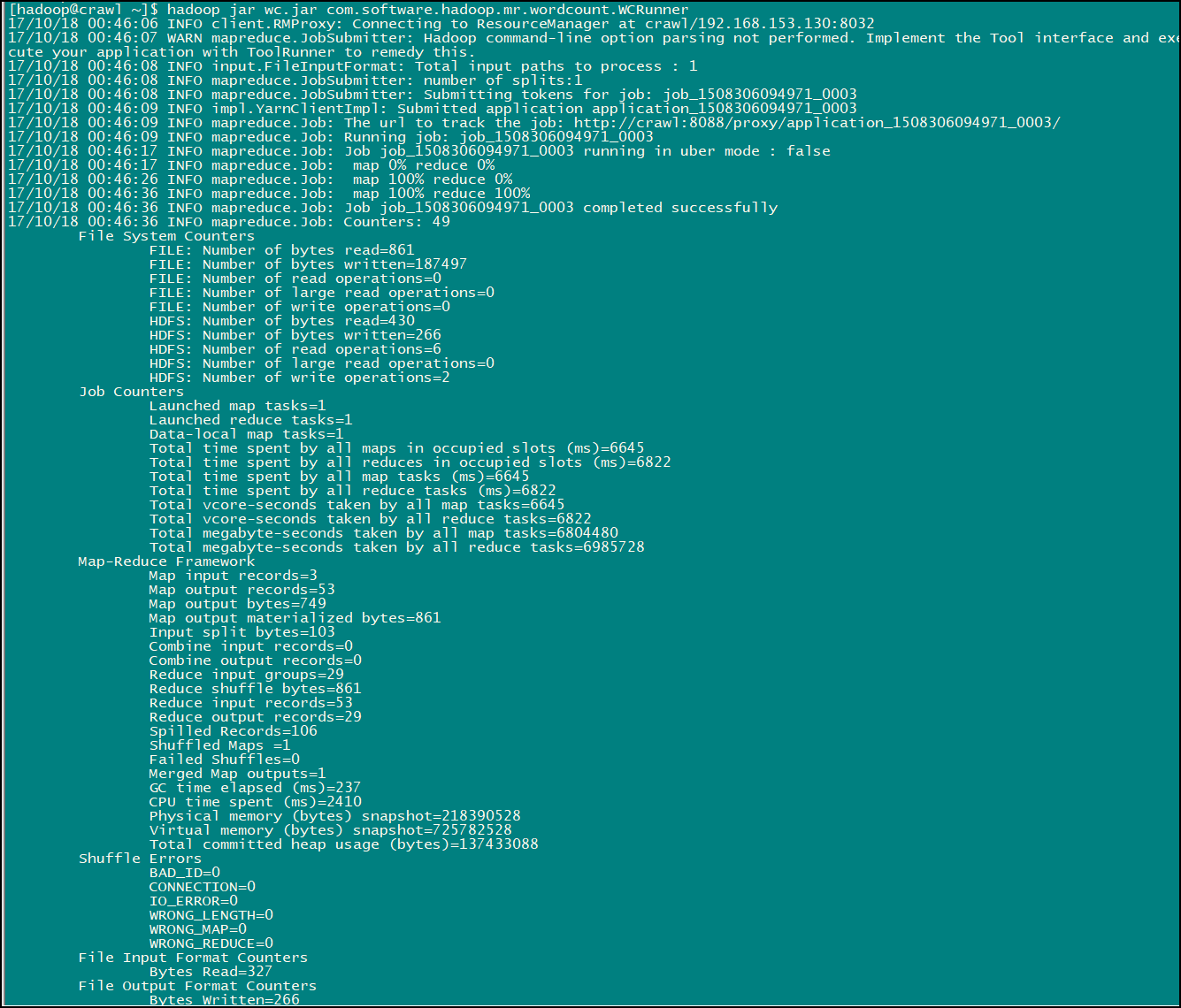
然后前去我们之前配置的存放输出结果的路径(LZ之前设置的为:/wc/output/)就可以看到 MapReduce 的执行结果了
输入命令:hadoop fs -ls /wc/output/ 查看以下 /wc/output/ 路径下的内容

结果数据就在第二个文件中,输入命令:hadoop fs -cat /wc/output/part-r-00000 即可查看:

至此我们的这个小应用就完成了,是不是很有意思的,LZ 在实现的时候还是发生了一点小意外:
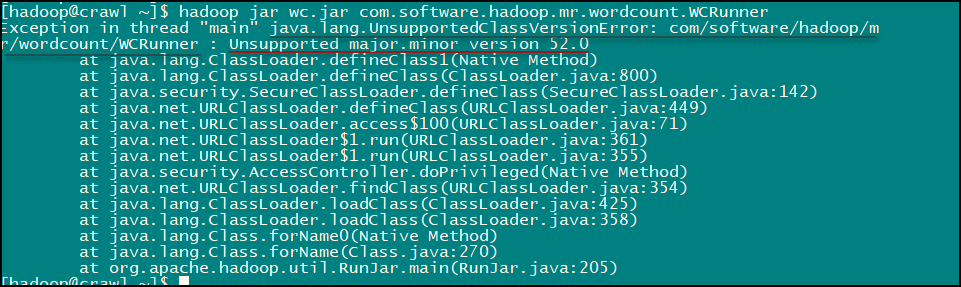
LZ 查阅资料发现这是由于 jdk 版本不一致导致的错误,统一 jdk 版本后便没有问题了。
hadoop MapReduce 入门的更多相关文章
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码
Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习MapReduce时的一些 ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本3(九)
不多说,直接上干货! 下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 下面是版本2. Hadoop MapReduce编程 API入门系列之挖掘气象数 ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2(十)
下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 这篇博文,包括了,实际生产开发非常重要的,单元测试和调试代码.这里不多赘述,直接送上代码. MRUni ...
- Hadoop MapReduce编程入门案例
Hadoop入门例程简介 一个.有些指令 (1)Hadoop新与旧API差异 新API倾向于使用虚拟课堂(象类),而不是接口.由于这更easy扩展. 比如,能够无需改动类的实现而在虚类中加入一个方法( ...
- 【Hadoop离线基础总结】MapReduce入门
MapReduce入门 Mapreduce思想 概述 MapReduce的思想核心是分而治之,适用于大量复杂的任务处理场景(大规模数据处理场景). 最主要的特点就是把一个大的问题,划分成很多小的子问题 ...
- Hadoop 专栏 - MapReduce 入门
MapReduce的基本思想 先举一个简单的例子: 打个比方我们有三个人斗地主, 要数数牌够不够, 一种最简单的方法可以找一个人数数是不是有54张(传统单机计算); 还可以三个人各分一摞牌数各自的(M ...
- Hadoop MapReduce编程 API入门系列之薪水统计(三十一)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.SalaryCount; import java.io.IOException; import jav ...
- Hadoop MapReduce编程 API入门系列之Crime数据分析(二十五)(未完)
不多说,直接上代码. 一共12列,我们只需提取有用的列:第二列(犯罪类型).第四列(一周的哪一天).第五列(具体时间)和第七列(犯罪场所). 思路分析 基于项目的需求,我们通过以下几步完成: 1.首先 ...
随机推荐
- P4208 [JSOI2008]最小生成树计数
现在给出了一个简单无向加权图.你不满足于求出这个图的最小生成树,而希望知道这个图中有多少个不同的最小生成树.(如果两颗最小生成树中至少有一条边不同,则这两个最小生成树就是不同的)输出方案数对31011 ...
- [06] Bean属性的注入
之前我们提到了Bean实例化的三种方式:构造器方式.静态工厂方式.普通工厂方式.那么对于Bean中的属性,又是如何进行注入的(依赖注入),这个篇章就来提一提. 1.先提提什么是"依赖注入&q ...
- YOU AND ME 不见不散(转载)
(看到一篇挺不错的文章,看了挺有感触的,与大家共勉.) 泰戈尔说: 有一个夜晚,我烧毁了所有的记忆, 从此我的梦就透明了: 有个早晨我扔掉了所有的昨天, 从此我的脚步就轻盈了! 越过山丘,才发现无人等 ...
- 计算机网络协议OSI TCP/IP协议--001
网桥:连接同构的LAN的网络互联设备,(同构的LAN 网是,应用层到逻辑层) 实 现的功能是:MAC子层和物理层.1.帧的发送与接收.2.缓冲的管理.3.协议转换. 路由器:在网络层实现互联,他 ...
- [WPF] How to bind to data when the datacontext is not inherited
原文:[WPF] How to bind to data when the datacontext is not inherited 原文地址:http://www.thomaslevesque.co ...
- 关于LCA
LCA:最近公共祖先 指在有根树中,找出某两个结点u和v最近的公共祖先 如图,5,7的最近公共祖先就是3 接下来,我们来了解如何求解LCA No.1 暴力 首先想到的肯定是暴力,我们搜索,从两个节点一 ...
- vue-cli 3.0 路由懒加载
当打包构建应用时,Javascript 包会变得非常大,影响页面加载.如果我们能把不同路由对应的组件分割成不同的代码块,然后当路由被访问的时候才加载对应组件,这样就更加高效了. 1. 安装 synta ...
- 分布式全文搜索引擎ElasticSearch
一 什么是 ElasticSearch Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎.当然 Elas ...
- VitualBox安装linux记录
下载镜像 CentOS 7镜像下载 阿里云站点:http://mirrors.aliyun.com/centos/7/isos/x86_64/ VirtualBox安装linux https://ww ...
- 来不及说什么了,Python 运维开发剁手价仅剩最后 2 天
51reboot 运维开发又双叒叕的搞活动了—— Python 运维开发 18 天训练营课程, 剁手价1299 最后2天 上课方式:网络直播/面授(仅限北京) DAY1 - DAY4 Python3 ...