MapReduce编程:平均成绩
问题描述
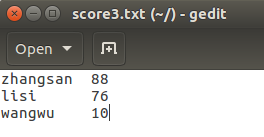
现在有三个文件分别代表学生的各科成绩,编程求各位同学的平均成绩。


编程思想
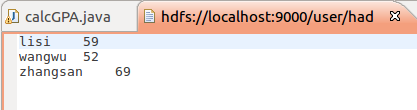
map函数将姓名作为key,成绩作为value输出,reduce根据key即可将三门成绩相加。
代码
package org.apache.hadoop.examples; import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class calcGPA {
public calcGPA() {
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); String fileAddress = "hdfs://localhost:9000/user/hadoop/"; //String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
String[] otherArgs = new String[]{fileAddress+"score1.txt", fileAddress+"score2.txt", fileAddress+"score3.txt", fileAddress+"output"};
if(otherArgs.length < 2) {
System.err.println("Usage: calcGPA <in> [<in>...] <out>");
System.exit(2);
} Job job = Job.getInstance(conf, "calc GPA");
job.setJarByClass(calcGPA.class);
job.setMapperClass(calcGPA.TokenizerMapper.class);
job.setCombinerClass(calcGPA.IntSumReducer.class);
job.setReducerClass(calcGPA.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
} FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
} public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { public IntSumReducer() {
} public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
int count = 0; IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get(),count++) {
val = (IntWritable)i$.next();
} int average = (int)sum/count;
context.write(key, new IntWritable(average));
}
} public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { public TokenizerMapper() {
} public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString(), "\n"); while(itr.hasMoreTokens()) {
StringTokenizer iitr = new StringTokenizer(itr.nextToken());
String name = iitr.nextToken();
String score = iitr.nextToken();
context.write(new Text(name), new IntWritable(Integer.parseInt(score)));
} }
}
}
疑问
在写这个的时候,我遇到个问题,就是输入输出文件的默认地址,为什么是user/hadoop/,我看了一下配置文件的信息,好像也没有出现过这个地址啊,希望有人能解答一下,万分感谢。
MapReduce编程:平均成绩的更多相关文章
- Hadoop 学习笔记 (十一) MapReduce 求平均成绩
china:张三 78李四 89王五 96赵六 67english张三 80李四 82王五 84赵六 86math张三 88李四 99王五 66赵六 77 import java.io.IOEx ...
- 简单的java Hadoop MapReduce程序(计算平均成绩)从打包到提交及运行
[TOC] 简单的java Hadoop MapReduce程序(计算平均成绩)从打包到提交及运行 程序源码 import java.io.IOException; import java.util. ...
- mapreduce实现学生平均成绩
思路: 首先从文本读入一行数据,按空格对字符串进行切割,切割后包含学生姓名和某一科的成绩,map输出key->学生姓名 value->某一个成绩 然后在reduce里面对成绩进行遍历 ...
- Hadoop MapReduce编程学习
一直在搞spark,也没时间弄hadoop,不过Hadoop基本的编程我觉得我还是要会吧,看到一篇不错的文章,不过应该应用于hadoop2.0以前,因为代码中有 conf.set("map ...
- hadoop2.2编程:使用MapReduce编程实例(转)
原文链接:http://www.cnblogs.com/xia520pi/archive/2012/06/04/2534533.html 从网上搜到的一篇hadoop的编程实例,对于初学者真是帮助太大 ...
- MapReduce编程实例6
前提准备: 1.hadoop安装运行正常.Hadoop安装配置请参考:Ubuntu下 Hadoop 1.2.1 配置安装 2.集成开发环境正常.集成开发环境配置请参考 :Ubuntu 搭建Hadoop ...
- MapReduce编程实例5
前提准备: 1.hadoop安装运行正常.Hadoop安装配置请参考:Ubuntu下 Hadoop 1.2.1 配置安装 2.集成开发环境正常.集成开发环境配置请参考 :Ubuntu 搭建Hadoop ...
- MapReduce编程实例4
MapReduce编程实例: MapReduce编程实例(一),详细介绍在集成环境中运行第一个MapReduce程序 WordCount及代码分析 MapReduce编程实例(二),计算学生平均成绩 ...
- MapReduce编程实例3
MapReduce编程实例: MapReduce编程实例(一),详细介绍在集成环境中运行第一个MapReduce程序 WordCount及代码分析 MapReduce编程实例(二),计算学生平均成绩 ...
随机推荐
- Laravel-2
● php发邮件 参考:https://blog.csdn.net/sinat_37390744/article/details/54667794 ● ajax提交表单时防止csrf攻击 1. 在网页 ...
- js 第二课
=赋值 ==比较 ===绝对比较 &&且 || 或 !取反 a?1:0 a=ture a?1:0 function LeyBc() { var a={d:11,b:22,c:&quo ...
- HDFS,MapReduce,Hive,Hbase 等之间的关系
HDFS: HDFS是GFS的一种实现,他的完整名字是分布式文件系统,类似于FAT32,NTFS,是一种文件格式,是底层的. Hive与Hbase的数据一般都存储在HDFS上.Hadoop HDFS为 ...
- Python字符串拼接的6种方法(转)
add by zhj: 对于多行字符串连接,第6种连接方法很方便,连接时不会添加额外的空格. 原文:http://www.cnblogs.com/bigtreei/p/7892113.html 1. ...
- 16.4-uC/OS-III同步 (任务信号量)
信号量和消息队列均是单独的内核对象,是独立于任务存在的. 任务信号量 仅发布给一个特定任务 .任务消息队列 可以发布给多个任务. 任务信号量伴随任务存在,只要创建了任务,其任务信号量就是该任务的一个数 ...
- Mac开发工具汇总
1: Json Parser Mac版 http://www.pc6.com/mac/180470.html
- mysql插入数据会变中文
db.url=jdbc:mysql://192.168.0.149:3306/pack_platform_dev?useUnicode=true&characterEncoding=utf-8 ...
- Java 基础 IO流(转换流,缓冲)
一,前言 在学习字符流(FileReader.FileWriter)的时候,其中说如果需要指定编码和缓冲区大小时,可以在字节流的基础上,构造一个InputStreamReader或者OutputStr ...
- this inspection detects names that should resolved but don't. Due to dynamic dispatch and duck typing, this is possible in a limited but useful number of cases. Top-level and class-level items are sup
输入第一行代码:import logging;logging.basicConfig(level==logging.INFO) 提示:this inspection detects names tha ...
- HBase笔记5(诊断)
阻塞急救: RegionServer内存设置太小: 解决方案: 设置Region Server的内存要在conf/hbase-env.sh中添加export HBASE_REGIONSERVER_OP ...