模型评估——ROC、KS
无论是利用模型对信用申请人进行违约识别,还是对授信申请人进行逾期识别……在各种各样的统计建模中,永远必不可少的一步是对模型的评价,这样我们就可以根据模型评价指标的取值高低,来决定选取哪个模型。本篇主要讲述一下ROC曲线和K-S曲线的区别和联系。
以二分类问题为例,模型输出会出现四种情况:

我们最关心的结果是正确预测的概率和误判率,常见的指标有:
(1)True Positive Rate,简称为TPR,计算公式为TPR=TP/(TP+FN)——所有真实的“1”中,有多少被模型成功选出;
(2)False Positive Rate,简称为FPR,计算公式为FPR=FP/(FP+TN)——所有真实的“0”中,有多少被模型误判为1了;
(3)Precision=TP/(TP+FP),或2TP/((TP+FN)+(TP+FP))。
其中最常用的是TPR和FPR。最理想的模型,当然是TPR尽量高而FPR尽量低啦,然而任何模型在提高正确预测概率的同时,也会难以避免地增加误判率。听起来有点抽象,好在有ROC曲线非常形象地表达了二者之间的关系。
对于一个二分类模型,输出的最初结果是连续的;假设已经确定一个阀值,那么最初结果大于阀值时,则输出最终结果为1,小于阀值则输出为0。假如阀值取值为0.6,那么FPR和TPR就可以计算出此时的取值,标志为一个点,记为(FPR1,TPR1);如果阀值取值为0.5,同理就可以计算出另一个点,记为(FPR2,TPR2)。设定不同的阀值,就可以计算不同的点(FPR,TPR),
我们以FPR为横坐标,TPR为纵坐标,把不同的点连成曲线,就得到了ROC曲线。理论上ROC就是这么画出来的,那么问题来了,阀值如何确定?
以Logistic模型为例,模型输出的结果其实是概率,然后我们通过设定阀值,把概率转化为最终的输出结果0和1。首先出现在我们脑中的直观想法,就是把(0,1)区间进行等分,比如,等分为十个区间(其实分成多少份都可以,大家可以自由发挥),那么就可以分别以0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9为阈值,首先计算出根据阀值判定出的0和1有多少,以及判定为1真实为1和判断为1真实为0的有多少;然后计算出不同的(FPR,TPR)值;最后把点之间进行连线,画出的曲线即是ROC曲线。
下面,我们以某商业银行某时间段内某支行客户的逾期相关数据为例详细说明:P代表此支行的某客户的逾期率(暂且定义为在此时间段内某客户的逾期可能性),Y代表是否为高逾期客户,X是与逾期有关的相关指标,比如行业、企业规模、客户的五级分类等等。
然而,当把这个直观的想法对案例数据付诸实施的时候,我们发现计算出的概率值都落在[0.0092,0.578]区间范围内。这种情况下,如果还用上面的“直观想法”(即仍然假定P小于阈值时,判定为0),那么设定阈值为0.1到0.5时,能够计算出不同的(FPR,TPR)值;而将阈值取到0.6到0.9时,模型的判定结果为所有的样本就都是0了……so sad!计算出的(FPR,TPR)值都是(0,0),ROC曲线的点由11个变成了6个…….
看来实践是检验真理的唯一标准!面对这个特殊案例,我们的直观想法肯定需要改进。最终,我们的实现方法是:
1. 把(0,1)区间升级为(min(P),max(P));
2. 取值(min(P),max(P))/10,设定阀值为(min(P),max(P))*k/10,其中k=1,2,3,…,9;
3. 根据不同的阀值,计算出不同的(FPR,TPR)值。
这时候再画出ROC曲线,就避免了上面的问题。
以上思路讲完后,可能有的小伙伴要问了:这样在写代码实现的过程中,每次都要和阀值进行做比较,计算量比较大,不如先对样本计算出的P值从小到大排序(当然从大到小也可以),取前百分之几(比如10%)处的值为阀值,那么排序之后前百分之几(比如前10%)的判定为0,其他则判定为1。这样计算量就少了很多啦!
于是,我们继续改进阀值的设置,首先把Logistic模型输出的概率从小到大排序,然后取10%的值(也就是概率值)作为阀值,同理把10%*k(k=1,2,3,…,9)处的值作为阀值,计算出不同的(FPR,TPR)值,就可以画出ROC曲线啦。
可是,从小到大排序之后,每次取前百分之几处的值为阀值呢?总共分成10份还是100还是1000份呢?有选择困难症的小伙伴又纠结了,告诉你个办法,别纠结,有多少个模型输出的概率值就分成多少份,不再考虑百分之几!比如Logistic模型输出的概率有214个,那么我们把214个目标变量从小到大进行排序,然后分别以这214个的概率值为阀值,可以计算出214个不同的(FPR,TPR)值,也可以画出ROC曲线。
ROC曲线画好后,就要发挥用处!对于一个模型一组参数可以画出一条ROC曲线,此时最优的阀值是什么呢?TPR和FPR是正相关的,也就是说,正确判定出1的数量增加时,必然要伴随着代价:误判为1的FP也增加。
从ROC曲线上也可以反映出这种变化,从ΔTPR>ΔFPR到ΔTPR<ΔFPR,最理想的阀值是ΔTPR=ΔFPR时。但是在实际应用中,我们很少能够给出ROC曲线的函数表达式,这时的解决方法包括:
(1)给出ROC曲线的拟合函数表达式,然后计算出最优的阀值,这个目前通过软件实现难度不大:如何给出最优拟合函数,计算数学上有很多方法;
(2)计算出ΔTPR≈ΔFPR的点即为最优的阀值;
(3)从业务上给出最优的阀值。
对于一个模型多个参数的情况,就可以画出多条ROC曲线,此时哪组参数是最优的呢?我们可以结合AUC指标,哪组参数的AUC值越高,说明此组参数下的模型效果越好。另外,在SAS的评分模型输出中,常用来判断收入分配公平程度的gini系数也用来评价模型,此时gini=2*AUC-1.
对了,解释一下AUC指标:ROC曲线下方的面积Area Under the ROC Curve,简称为AUC。这是评价模型的另一个方法,AUC值越大,说明模型的分辨效果越好。
常用的模型评价还有K-S曲线,它和ROC曲线的画法异曲同工。以Logistic模型为例,首先把Logistic模型输出的概率从大到小排序,然后取10%的值(也就是概率值)作为阀值,同理把10%*k(k=1,2,3,…,9)处的值作为阀值,计算出不同的FPR和TPR值,以10%*k(k=1,2,3,…,9)为横坐标,分别以TPR和FPR的值为纵坐标,就可以画出两个曲线,这就是K-S曲线。
从K-S曲线就能衍生出KS值,KS=max(TPR-FPR),即是两条曲线之间的最大间隔距离。当(TPR-FPR)最大时,也就是ΔTPR-ΔFPR=0,这和ROC曲线上找最优阀值的条件ΔTPR=ΔFPR是一样的。从这点也可以看出,ROC曲线、K-S曲线、KS值的本质是相同的。
以某模型的评价为例,在K-S曲线的横坐标0.4时取KS=0.53,可以认为最优的阀值是从小到大排序的40%处的值:

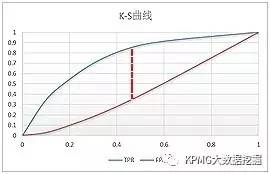
K-S曲线能直观地找出模型中差异最大的一个分段,比如评分模型就比较适合用KS值进行评估;但同时,KS值只能反映出哪个分段是区分度最大的,不能反映出所有分段的效果。所以,在实际应用中,模型评价一般需要将ROC曲线、K-S曲线、KS值、AUC指标结合起来使用。
在目前常用的统计软件中,基本都可以直接输出ROC曲线、AUC值、K-S曲线等。不过有的小伙伴会问,我用的软件没有这些内嵌指标,怎么办?还能怎么办,自己写几行代码画呗,相信你们可以的。
转自:http://www.sohu.com/a/132667664_278472
模型评估——ROC、KS的更多相关文章
- 笔记︱风控分类模型种类(决策、排序)比较与模型评估体系(ROC/gini/KS/lift)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 本笔记源于CDA-DSC课程,由常国珍老师主讲 ...
- 风控分类模型种类(决策、排序)比较与模型评估体系(ROC/gini/KS/lift)
python信用评分卡建模(附代码,博主录制) https://study.163.com/course/introduction.htm?courseId=1005214003&utm_ca ...
- 评价指标的局限性、ROC曲线、余弦距离、A/B测试、模型评估的方法、超参数调优、过拟合与欠拟合
1.评价指标的局限性 问题1 准确性的局限性 准确率是分类问题中最简单也是最直观的评价指标,但存在明显的缺陷.比如,当负样本占99%时,分类器把所有样本都预测为负样本也可以获得99%的准确率.所以,当 ...
- Scikit-learn:模型评估Model evaluation
http://blog.csdn.net/pipisorry/article/details/52250760 模型评估Model evaluation: quantifying the qualit ...
- sklearn中的模型评估-构建评估函数
1.介绍 有三种不同的方法来评估一个模型的预测质量: estimator的score方法:sklearn中的estimator都具有一个score方法,它提供了一个缺省的评估法则来解决问题. Scor ...
- 模型构建<1>:模型评估-分类问题
对模型的评估是指对模型泛化能力的评估,主要通过具体的性能度量指标来完成.在对比不同模型的能力时,使用不同的性能度量指标可能会导致不同的评判结果,因此也就意味着,模型的好坏只是相对的,什么样的模型是较好 ...
- 模型的性能评估(二) 用sklearn进行模型评估
在sklearn当中,可以在三个地方进行模型的评估 1:各个模型的均有提供的score方法来进行评估. 这种方法对于每一种学习器来说都是根据学习器本身的特点定制的,不可改变,这种方法比较简单.这种方法 ...
- python大战机器学习——模型评估、选择与验证
1.损失函数和风险函数 (1)损失函数:常见的有 0-1损失函数 绝对损失函数 平方损失函数 对数损失函数 (2)风险函数:损失函数的期望 经验风险:模型在数据集T上的平均损失 根据大 ...
- ML 04、模型评估与模型选择
机器学习算法 原理.实现与实践——模型评估与模型选择 1. 训练误差与测试误差 机器学习的目的是使学习到的模型不仅对已知数据而且对未知数据都能有很好的预测能力. 假设学习到的模型是$Y = \hat{ ...
随机推荐
- 如何在chrome上打开SSL3.0
Chrome默认关闭对SSL3.0的支持,无法访问一些Web应用.可以手动打开他. 启动chrome依次选择 设置->高级->系统->打开代理设置->安全 将使用SSL 3.0 ...
- C语言输出格雷码
格雷码是以n位的二进制来表示数. 与普通的二进制表示不同的是,它要求相邻两个数字只能有1个数位不同. 首尾两个数字也要求只有1位之差. 有很多算法来生成格雷码.以下是较常见的一种: 从编码全0开始生成 ...
- 防火墙/IDS测试工具Ftester
防火墙/IDS测试工具Ftester FTester 全称Firewall Tester,是一个用来测试防火墙的过滤策略和入侵检测(IDS)能力的工具.这个工具主要是有两个perl的脚本组成: 1. ...
- android studio 关闭SVN关联
<?xml version="1.0" encoding="UTF-8"?> <project version="4"&g ...
- ubuntu,day 2 ,退出当前用户,创建用户,查找,su,sudo,管道符,grep,alias,mount,tar解压
本节内容: 1,文件权限的控制,chmod,chown 2,用户的增删和所属组,useradd,userdel 3,用户组的增删,groupadd,groupdel 4,su,sudo的介绍 5,别名 ...
- delphi三层结构常出现的问题和解决方案
以下问题出现原因有可能多个,暂时将我遇见的记录下来,以后有新的在陆续更新上去,有网友愿意的话也可以共同测试一下. 一,无法更新定位行.一些值可能已在最后一次读取已更改. 错误出现前提: 1, 录数据时 ...
- mysql的innodb和myisam的区别和应用场景
1. 区别: (1)事务处理: MyISAM是非事务安全型的,而InnoDB是事务安全型的(支持事务处理等高级处理): (2)锁机制不同: MyISAM是表级锁,而InnoDB是行级锁: (3)sel ...
- 第39章:MongoDB-集群--Replica Sets(副本集)---副本集基本原理
①操作日志oplog Oplog是主节点的local数据库中的一个固定集合,按顺序记录了主节点的每一次写操作,MongoDB的复制功能是使用oplog来实现的,备份节点通过查询这个集合就可以知道需要进 ...
- ssm框架中处理json格式的数据步骤
1.导架包 <!--处理json--> <dependency> <groupId>com.fasterxml.jackson.core</groupId&g ...
- SELECT版FTP
功能: 1.使用SELECT或SELECTORS模块实现并发简单版FTP 2.允许多用户并发上传下载文件环境: python 3.5特性: select 实现并发效果运行: get 文件名 #从服务器 ...