Learning-Python【20】:Python常用模块(3)—— shelve、pickle、json、xml、configparser
什么是序列化/反序列化?
序列化就是将内存中的数据结构转换成一种中间格式存储到硬盘或者基于网络传输,反序列化就是硬盘中或者网络中传来的一种数据格式转换成内存中数据结构
为什么要有序列化/反序列化?
1、可以保存程序的运行状态
2、数据的跨平台交互
shelve模块:也用于序列化,它于 pickle 不同之处在于不需要关心文件模式等,而是直接把它当成一个字典来看待,它可以直接对数据进行修改,而不用覆盖原来的数据,但 pickle 想要修改只能用 wb 模式来覆盖
- import shelve
- dic1 = {'pwd': 'qiu123', 'age': 22}
- dic2 = {'pwd': 'xi456', 'age': 22}
- d = shelve.open('db.txt')
- d['qiu'] = dic1
- d['xi'] = dic2
- print(d['qiu']['pwd'])
- d.close()
shelve序列化
- import shelve
- d = shelve.open('db.txt')
- print(d['qiu'])
- print(d['qiu']['pwd'])
- d.close()
shelve反序列化
- import shelve
- # 对子字典的修改需要参数
- d = shelve.open('db.txt', writeback=True)
- d['qiu']['age'] = 20
- print(d['qiu'])
- d.close()
对子字典的修改需要参数
pickle模块:一个用来序列化的模块
主要功能有dump(序列化)、load(反序列化)、dumps、loads。dump/load 相比于 dumps/loads,封装了 write 和 read,使用操作更方便
- import pickle
- dic = {'a':1, 'b':2, 'c':3}
- # 1. 序列化
- pkl = pickle.dumps(dic)
- print(pkl, type(pkl))
- # 2. 写入文件
- with open('db.pkl', 'wb') as f:
- f.write(pkl)
- # 1和2可以合成一步
- with open('db.pkl', 'wb') as f:
- res = pickle.dump(dic, f)
pickle序列化
- import pickle
- # 1. 从文件中读取pickle格式
- with open('db.pkl', 'rb') as f:
- pkl = f.read()
- # 2. 将pkl_str转成内存中的数据类型
- dic = pickle.loads(pkl)
- print(dic)
- # 1和2可以合成一步
- with open('db.pkl', 'rb') as f:
- dic = pickle.load(f)
- print(dic)
pickle反序列化
优点:可以支持 Python 中所有的数据类型
缺点:只能被 Python 识别,不能跨平台
json模块:一个用于序列化的模块
在使用 json 模块之前,需要先了解 JSON(JavaScript Object Notation,JS的对象简谱),它表示出来的是一个字符串,可以被任何语言解析读取,方便使用
JSON 表示的对象就是标准的 JavaScript 语言的对象,JSON 和 Python 内置的数据类型对应如下:
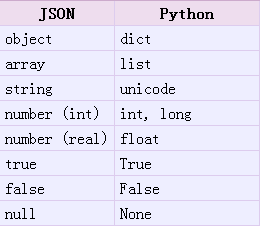
- import json
- dic = {'name': 'qiuxi', 'age': 22}
- # 序列化: 内存中的数据类型转化成中间格式json
- json_str = json.dumps(dic)
- print(json_str, type(json_str))
- # 运行
- {"name": "qiuxi", "age": 22} <class 'str'>
JSON格式不能识别单引号,全都是双引号
- import json
- dic = {'name': 'qiuxi', 'age': 22}
- # 1. 序列化得到json_str
- json_str = json.dumps(dic)
- # 2. 把json_str写入文件
- # 因为json表示出来的都是字符串, 所以用wt且指定编码
- with open('db.json', 'wt', encoding='utf-8') as f:
- f.write(json_str)
- # 1和2合并一步
- with open('db.json', 'wt', encoding='utf-8') as f:
- json.dump(dic, f)
json序列化
- import json
- # 1. 从文件中读取json格式
- with open('db.json', 'rt', encoding='utf-8') as f:
- json_str = f.read()
- # 2. 将json_str转成内存中的数据类型
- dic = json.loads(json_str)
- print(dic)
- # 1和2合并一步
- with open('db.json', 'rt', encoding='utf-8') as f:
- dic = json.load(f)
- print(dic)
json反序列化
当自己手写的 json 文件时,可以到网上进行JSON格式化校验
优点:跨平台性强
缺点:只能支持 Python 部分的数据类型
xml模块:也是用于序列化的一种模块
在使用 xml 模块之前,需要先了解 XML(可扩展标记语言),也是一种通用的数据格式。
语法格式:
1、任何的起始标签都必须有一个结束标签
2、可以采用另一种简化语法,可以在一个标签中同时表示起始和结束标签。这种语法是在大于符号之前紧跟一个斜线(/),例如<百度百科词条/>,XML解析器会将其翻译成 <百度百科词条></百度百科词条>
3、标签必须按合适的顺序进行嵌套,所以结束标签必须按镜像顺序匹配起始签。这好比是将起始和结束标签看作是数学中的左右括号:在没有关闭所有的内部括号之前,是不能关闭外面的括号的。
4、所有的属性都必须有值
5、所有的属性都必须在值的周围加上双引号
标签的组成
- <tagname attributename="value">text
- <subtags/>
- </tagname>
- <标签名 属性="属性值">文本
- </子标签>
- </标签名>
标签组成格式
- import xml.etree.ElmentTree # 表示节点树
- <studentinfo>
- <stu age="" name="张三">
- <phone name="华为">这是华为手机</phone>
- <computer name="Mac">14888</computer>
- </stu>
- <stu age="" name="李四">
- <phone name="华为">这是华为手机</phone>
- <computer name="联想">4888</computer>
- </stu>
- </studentinfo>
初始的数据
标签的三个特征:标签名tag、标签属性attrib、标签的文本内容text
- import xml.etree.ElementTree as ET
- # 解析d.xml
- tree = ET.parse('d.xml')
- print(tree)
- # 获取根标签
- rootTree = tree.getroot()
- # 第一种获取标签的方式
- # iter用于在全文范围获取标签
- for item in rootTree.iter('phone'):
- print(item.tag) # 标签名
- print(item.attrib) # 标签的属性
- print(item.text) # 文本内容
- # 第二种获取标签的方式
- # find用于从根标签的子标签中查找一个名为stu的标签, 如果有多个, 找到的是第一个
- print(rootTree.find('stu').attrib)
- # 第三种获取标签的方式
- # findall用于从同级标签中查找所有名为phone的标签
- print(rootTree.findall('phone'))
- # 1、查
- # 遍历整个文档
- for stu in rootTree:
- for item in stu:
- print(item.tag)
- print(item.attrib)
- print(item.text)
- # 2、改
- for phone in rootTree.iter('phone'):
- print(phone.tag)
- phone.attrib = {'name': '华为'}
- phone.text = '这是华为手机'
- tree.write('d.xml',encoding='utf-8')
- # 3、增
- for stu in rootTree:
- computer = stu.find('computer')
- if int(computer.text) > 5000:
- print('价钱大于5000的电脑的使用者', stu.attrib)
- tag = ET.Element('qiuxi')
- tag.attrib = {'hobby': 'music'}
- tag.text = '喜欢音乐'
- stu.append(tag)
- tree.write('d.xml', encoding='utf-8')
- # 4、删
- for stu in rootTree:
- tag = stu.find('qiuxi')
- if tag is not None:
- print("========")
- stu.remove(tag)
- tree.write('d.xml', encoding='utf-8')
xml模块的使用
configparser模块:用于解析配置文件的模块
配置文件即包含配置程序信息的文件,一些需要修改但不经常修改的信息,例如数据文件的路径等
配置文件中只有两种内容,一种是 section 分区,另一种是 option 选项,就是一个 key=value 形式
使用最多的是 get ,用来从配置文件获取一个配置选项
- # 路径的相关配置
- [path]
- db_path = C://myfile/test.txt
- # 用户相关的配置
- [user]
- name = qiuxi
- age = 22
初始的配置文件
- import configparser
- # 创建一个解析器
- config = configparser.ConfigParser()
- # 读取并解析test.cfg
- config.read('test.cfg', encoding='utf-8')
- # 获取需要的信息
- print(config.sections()) # 获取分区
- print(config.options('user')) # 获取选项
- # 获取某个选项的值
- print(config.get('path', 'db_path'))
- print(config.get('user', 'age'))
- # get返回的都是字符串类型, 如果需要转换类型, 直接使用get+对应的类型
- print(type(config.getint("user","age")))
- # 是否有某个分区
- print(config.has_section('user'))
- # 是否有某个选项
- print(config.has_option('user', 'name'))
- # 一些不太常用的操作
- # 添加
- config.add_section("server")
- config.set("server","url","192.168.1.2")
- # 删除
- config.remove_option("user","age")
- # 修改
- config.set("server","url","192.168.1.2")
- # 增删改查操作完成后写回文件中
- with open("test.cfg", "wt", encoding="utf-8") as f:
- config.write(f)
configparser模块操作
Learning-Python【20】:Python常用模块(3)—— shelve、pickle、json、xml、configparser的更多相关文章
- python常用模块之shelve模块
python常用模块之shelve模块 shelve模块是一个简单的k,v将内存中的数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据类型 我们在上面讲json.pickle ...
- 十八. Python基础(18)常用模块
十八. Python基础(18)常用模块 1 ● 常用模块及其用途 collections模块: 一些扩展的数据类型→Counter, deque, defaultdict, namedtuple, ...
- python笔记之常用模块用法分析
python笔记之常用模块用法分析 内置模块(不用import就可以直接使用) 常用内置函数 help(obj) 在线帮助, obj可是任何类型 callable(obj) 查看一个obj是不是可以像 ...
- python基础31[常用模块介绍]
python基础31[常用模块介绍] python除了关键字(keywords)和内置的类型和函数(builtins),更多的功能是通过libraries(即modules)来提供的. 常用的li ...
- Python学习 :常用模块(四)----- 配置文档
常用模块(四) 八.configparser 模块 官方介绍:A configuration file consists of sections, lead by a "[section]& ...
- pickle,shelve,json,configparser 的模块使用
主要内容1. 什么是序列化2. pickle3. shelve4. json5. configparser模块 一. 什么是序列化在我们存储数据或者网络传输数据的时候. 需要对我们的对象进行处理. 把 ...
- Python 常用模块(2) 序列化(pickle,shelve,json,configpaser)
主要内容: 一. 序列化概述 二. pickle模块 三. shelve模块 四. json模块(重点!) 五. configpaser模块 一. 序列化概述1. 序列化: 将字典,列表等内容转换成一 ...
- Day5 - Python基础5 常用模块学习
Python 之路 Day5 - 常用模块学习 本节大纲: 模块介绍 time &datetime模块 random os sys shutil json & picle shel ...
- Python全栈开发之路 【第六篇】:Python基础之常用模块
本节内容 模块分类: 好处: 标准库: help("modules") 查看所有python自带模块列表 第三方开源模块: 自定义模块: 模块调用: import module f ...
- Python基础5 常用模块学习
本节大纲: 模块介绍 time &datetime模块 random os sys shutil json & picle shelve xml处理 yaml处理 configpars ...
随机推荐
- mysql存储emoji问题
前一段时间,项目中需要在数据库中存储emoji,由于编码格式不对,直接导致数据库报错,后来修改mysql的编码,就解决了 emoji符号实际上是文本,并不是图片,它们仅仅显示为图片 在mysql5.5 ...
- vue 拍照上传图片 demo
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 16.3-uC/OS-III同步 (事件标志组实验)
事件标志组,顾名思义,就是若干个事件标志的组合,代表若干个事件是否发生,通常用于集合两个或两个以上事件的状态 . 1.如果想要使用事件标志组,就必须事先使能事件标志组.消息队列的使能位于“os_cfg ...
- React-Router4.x中文文档
以下为翻译的中文API(水平有限,凑合看,欢迎纠正补充~) <BrowserRouter> 使用HTML5历史记录API(pushState,replaceState和popstate事件 ...
- (3.1)mysql备份与恢复之mysqldump
目录: 1.单实例联系 1.1.备份单个数据库联系多种参数使用 [1]mysqldump命令备份演示 [2]查看备份文件 [3]用备份文件还原 1.2.mysqldump 各类参数释义 [1]--de ...
- Cartographer源码阅读(8):imu_tracker
IMU的输入为imu_linear_acceleration 和 imu_angular_velocity 线加速和角速度.最终作为属性输出的是方位四元数. Eigen::Quaterniond ...
- Centos不能上外网解决
检查路由 # route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0 ...
- #WEB安全基础 : HTTP协议 | 0x0 TCP/IP四层结构
学完HTML/CSS了? 做了这么多网页,但是你知道它们是怎么工作的吗? 作为你的朋友,我也对这些东西感兴趣,在写博客的同时也在和你一起学. 废话少说,进入正题 网络中的通信包括两个端分别为:客户端( ...
- bzoj4195(并查集+离散化)
题目大意:给出n个变量互相的相等或不等关系,求这些关系是否矛盾 思路:把相等的变量加入并查集,不等的查询是否合法 eg:数据很大,离散化(然而我用的是map) #include<stdio.h& ...
- html5 javascript 事件练习1
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8&qu ...