洗礼灵魂,修炼python(59)--爬虫篇—httplib模块
httplib
1.简介
同样的,httplib默认存在于python2,python3不存在:

httplib是python中http协议的客户端实现,可以用来与 HTTP 服务器进行交互,支持HTTP和HTTPS。httplib功能挺实用,也挺简单,不信的话,接着看
2.方法/属性
httplib的内容不是很多,也比较简单

3.常用方法/属性解析
httplib.HTTPConnection ( host [ , port [ , strict [ , timeout ]]] ):HTTPConnection类的构造函数(有没有发现和urllib.urlopen对象很像?),表示一次与服务器之间的交互,即请求/响应。
- host:服务器ip或者url,如:www.baidu.com
- port:端口号,默认值为80
- strict:默认值为false, 表示在无法解析服务器返回的状态行时( status line),是否抛BadStatusLine 异常(最常见的: HTTP/1.0 200 OK )
- timeout:超时时间
对象HTTPConnection的方法:
HTTPConnection.request ( method , url [ , body [ , headers ]] )(这里是不是又很像urllib2.request):调用request 方法会向服务器发送一次请求
- method:请求的方法,常用有方法有get 和post
- url:请求的资源的url
- body:提交到服务器的数据,必须是字符串(如果method 是”post” ,则可以把body 理解为html 表单中的数据)
- headers:请求的http头
HTTPConnection.connect():连接到Http服务器
HTTPConnection.close():关闭与服务器的连接
HTTPConnection.set_debuglevel ( level ):设置高度级别,参数level的默认值为0 ,表示不输出任何调试信息
HTTPConnection.getresponse():表示服务器对客户端请求的http响应,返回的对象是HTTPResponse 的实例,下面提到
Normal
0
7.8 磅
0
2
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:普通表格;
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0cm 5.4pt 0cm 5.4pt;
mso-para-margin:0cm;
mso-para-margin-bottom:.0001pt;
mso-pagination:widow-orphan;
font-size:10.5pt;
mso-bidi-font-size:11.0pt;
font-family:"Calibri","sans-serif";
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-font-kerning:1.0pt;}
对象httplib.HTTPResponse方法:
HTTPResponse.read([amt]):获取响应的消息体。如果请求的是一个普通的网页,那么该方法返回的是页面的html。可选参数amt表示从响应流中读取指定字节的数据。
HTTPResponse.getheader(name[, default]):获取响应头
- name表示头域(header field)名
- default在头域名不存在的情况下作为默认值返回
HTTPResponse.getheaders():以列表的形式返回所有的头信息
HTTPResponse.msg:获取所有的响应头信息
HTTPResponse.version:获取服务器所使用的http协议版本,比如11表示http/1.1;10表示http/1.0
HTTPResponse.status:获取响应的状态码,如:200
HTTPResponse.reason:返回服务器处理请求的结果说明,多为”OK”
例:
#coding=utf-8
import httplib
test=httplib.HTTPConnection('www.baidu.com',80,False)
test.request('GET','/',headers={'Host': 'www.baidu.com',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0',
'Accept': 'text/plain'})
res = test.getresponse()
print 'version:%s'%res.version
print 'reason:%s'%res.reason
print 'status:%s'%res.status
print 'msg:%s'%res.msg
print 'headers:%s'%res.getheaders()
print res.read()
test.close()
Normal
0
7.8 磅
0
2
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:普通表格;
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0cm 5.4pt 0cm 5.4pt;
mso-para-margin:0cm;
mso-para-margin-bottom:.0001pt;
mso-pagination:widow-orphan;
font-size:10.5pt;
mso-bidi-font-size:11.0pt;
font-family:"Calibri","sans-serif";
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-font-kerning:1.0pt;}
结果:
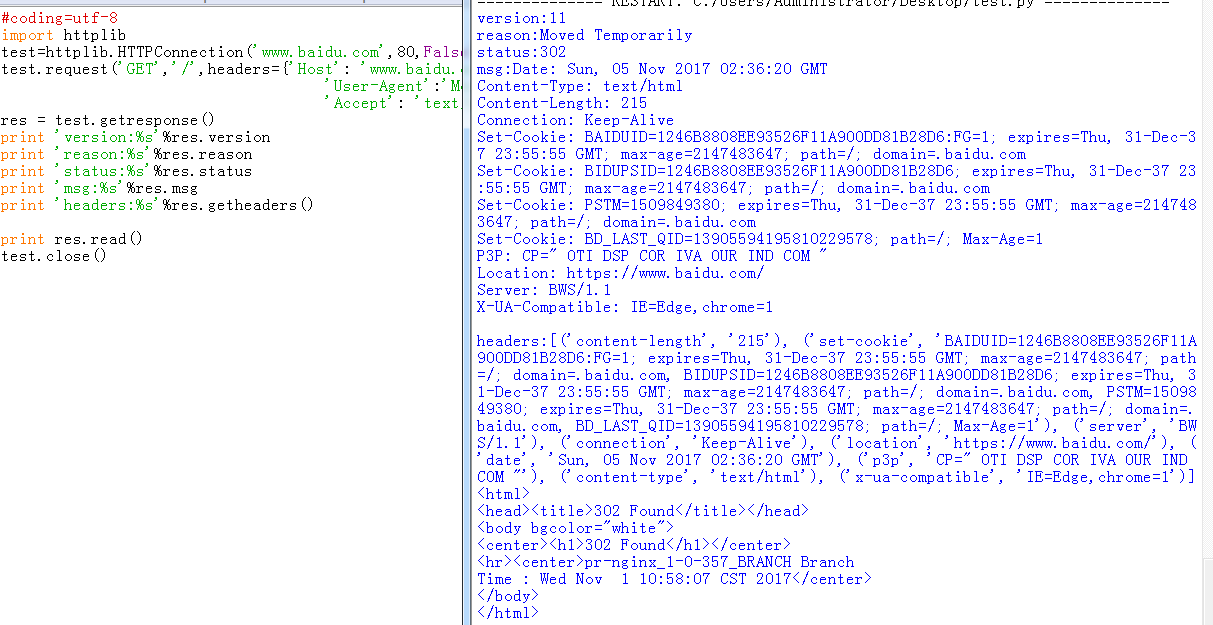
其他方法和属性自己下去再测试了
Httplib模块中还定义了一些常量:
Httplib. HTTP_PORT:值为80,表示默认的端口号为80
Httplib.OK:值为200,表示请求成功返回
Httplib. NOT_FOUND:值为404,表示请求的资源不存在

可以通过httplib.responses 查询相关变量的含义:

其实有没有觉得httplib还相对挺简单的,我个人感觉比urllib功能多点,比urllib2简单。
免责声明
本博文只是为了分享技术和共同学习为目的,并不出于商业目的和用途,也不希望用于商业用途,特此声明。如果内容中测试的贵站站长有异议,请联系我立即删除
洗礼灵魂,修炼python(59)--爬虫篇—httplib模块的更多相关文章
- 洗礼灵魂,修炼python(63)--爬虫篇—re模块/正则表达式(1)
爬虫篇前面的某一章了,我们要爬取网站页面源代码的数据,要从中获取到我们想要的数据,是不是感觉很费力,确实费力对吧?那么有没有什么有利的工具来解决这个问题呢?那就是这一篇博文的主题—— 正则表达式简介 ...
- 洗礼灵魂,修炼python(60)--爬虫篇—httplib2模块
这里先要补充一下,Python3自带两个用于和HTTP web 服务交互的标准库(内置模块): http.client 是HTTP协议的底层库 urllib.request 建立在http.clien ...
- 洗礼灵魂,修炼python(54)--爬虫篇—urllib2模块
urllib2 1.简介 urllib2模块定义的函数和类用来获取URL(主要是HTTP的),他提供一些复杂的接口用于处理: 基本认证,重定向,Cookies等.urllib2和urllib差不多,不 ...
- Python 学习 第九篇:模块
模块是把程序代码和数据封装的Python文件,也就是说,每一个以扩展名py结尾的Python源代码文件都是一个模块.每一个模块文件就是一个独立的命名空间,用于封装顶层变量名:在一个模块文件的顶层定义的 ...
- 洗礼灵魂,修炼python(53)--爬虫篇—urllib模块
urllib 1.简介: urllib 模块是python的最基础的爬虫模块,其核心功能就是模仿web浏览器等客户端,去请求相应的资源,并返回一个类文件对象.urllib 支持各种 web 协议,例如 ...
- 洗礼灵魂,修炼python(64)--爬虫篇—re模块/正则表达式(2)
前面学习了元家军以及其他的字符匹配方法,那得会用啊对吧?本篇博文就简单的解析怎么运用 正则表达式使用 前面说了正则表达式的知识点,本篇博文就是针对常用的正则表达式进行举例解析.相信你知道要用正则表达式 ...
- Python学习——爬虫篇
requests 使用requests进行爬取 下面是我编写的第一个爬虫的脚本 import requests # 导入reques ...
- Python学习—爬虫篇之破解ntml登陆问题
之前帮公司爬取过内部的一个问题单网站,要求将每个问题单的下的附件下载下来.一开始的时候我就遇到一个破解登陆验证的大坑...... (╬ ̄皿 ̄)=○ 由于在公司使用的都是内网,代码和网站的描述 ...
- 04.Python网络爬虫之requests模块(1)
引入 Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用. 警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症.冗余代码症.重新发明轮子症.啃文档 ...
随机推荐
- python之有用的3个内置函数(filter/map/reduce)
这三个内置函数还是非常有用的,在工作中用的还不少,顺手,下面一一进行介绍 1.filter 语法:filter(function,iterable) 解释:把迭代器通过function函数进行过滤出想 ...
- app测试环境搭建(python)
app测试环境的搭建大致如下几个: 1.appium安装 appium-server或者使用appium-desktop都可以,前者已经不再更新 下载地址:appium.io 2.Android SD ...
- 使用POI导出Excel文件
创建表头信息 表头信息用于自动生成表头结构及排序 public class ExcelHeader implements Comparable<ExcelHeader>{ /** * ex ...
- MLlib之NaiveBayes算法源码学习
package org.apache.spark.mllib.classification import breeze.linalg.{DenseMatrix => BDM, DenseVect ...
- Migrate from ASP.NET Core 2.0 to 2.1
http://www.talkingdotnet.com/migrate-existing-aspnet-core-2-application-aspnet-core-2-1/ https://doc ...
- mysql 开发进阶篇系列 32 工具篇(mysqladmin工具)
一.概述 mysqladmin是一个执行管理操作的客户端程序.用来检要服务的配置和当前的状态,创建并删除数据库等.功能与mysql客户端类似,主要区别在于它更侧重于一些管理方面的功能.1. 查找mys ...
- mysql 开发进阶篇系列 23 应用层优化与查询缓存
一.概述 前面章节介绍了很多数据库的优化措施,但在实际生产环境中,由于数据库服务器本身的性能局限,就必须要对前台的应用来进行优化,使得前台访问数据库的压力能够减到最小. 1. 使用连接池 对于访问数据 ...
- jxl 读取xls,并转为二维数组可进行保存
jxl.jar: 通过java操作excel表格的工具类库 支持Excel 95-2000的所有版本 生成Excel 2000标准格式 支持字体.数字.日期操作 能够修饰单元格属性 支持图像和图表 应 ...
- centos6.10搭建ELK之elasticsearch6.5.4
1.环境准备 1.1.安装java环境版本不要低于java8 # java -version java version "1.8.0_191" Java(TM) SE Runtim ...
- js从一个对象数组中根据属性值大小排序
<script type="text/javascript"> var sdts = [ {name:"小明",age:30}, {name:&qu ...