Spark共享变量(广播变量、累加器)
转载自:https://blog.csdn.net/Android_xue/article/details/79780463
Spark两种共享变量:广播变量(broadcast variable)与累加器(accumulator)
累加器用来对信息进行聚合,而广播变量用来高效分发较大的对象。
共享变量出现的原因:
通常在向 Spark 传递函数时,比如使用 map() 函数或者用 filter() 传条件时,可以使用驱动器程序中定义的变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,更新这些副本的值也不会影响驱动器中的对应变量。Spark 的两个共享变量,累加器与广播变量,分别为结果聚合与广播这两种常见的通信模式突破了这一限制。
广播变量的引入:
Spark 会自动把闭包中所有引用到的变量发送到工作节点上。虽然这很方便,但也很低效。原因有二:首先,默认的任务发射机制是专门为小任务进行优化的;其次,事实上你可能会在多个并行操作中使用同一个变量,但是 Spark 会为每个操作分别发送。
用一段代码来更直观的解释:
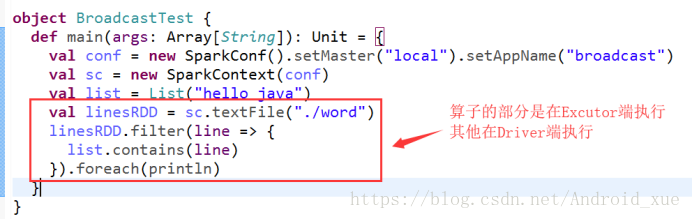
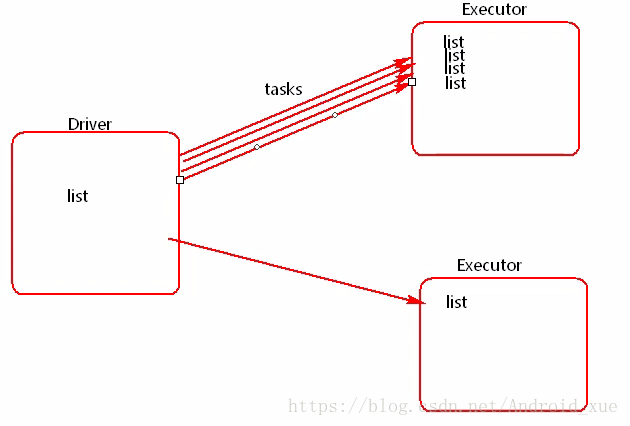
list是在driver端创建的,但是因为需要在excutor端使用,所以driver会把list以task的形式发送到executor端,如果有很多个task,就会有很多给excutor端携带很多个list,如果这个list非常大的时候,就可能会造成内存溢出(如下图所示)。这个时候就引出了广播变量。
使用广播变量后:
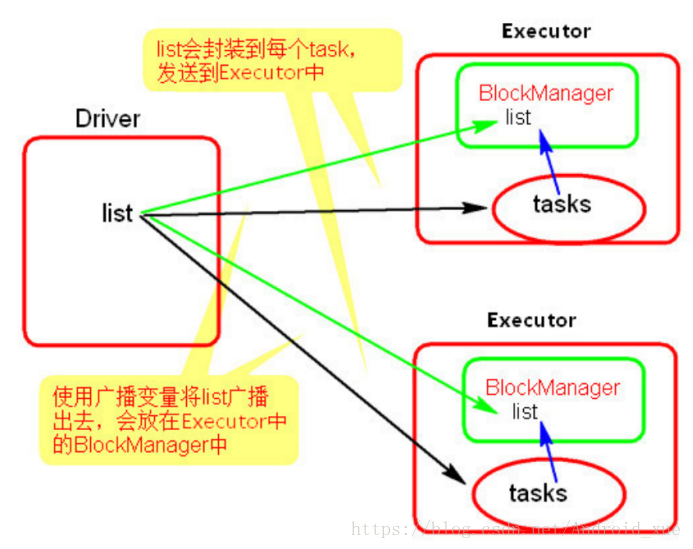
使用广播变量的过程很简单:
(1) 通过对一个类型 T 的对象调用 SparkContext.broadcast 创建出一个 Broadcast[T] 对象。任何可序列化的类型都可以这么实现。
(2) 通过 value 属性访问该对象的值(在 Java 中为 value() 方法)。
(3) 变量只会被发到各个节点一次,应作为只读值处理(修改这个值不会影响到别的节点)。
案例如下:
object BroadcastTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("broadcast")
val sc = new SparkContext(conf)
val list = List("hello java")
val broadcast = sc.broadcast(list)
val linesRDD = sc.textFile("./word")
linesRDD.filter(line => {
broadcast.value.contains(line)
}).foreach(println)
sc.stop()
}
}
注意事项:
能不能将一个RDD使用广播变量广播出去?
不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。
广播变量只能在Driver端定义,不能在Executor端定义。
在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
我们发现打印的结果为

依然是driver和executor端的数据不能共享的问题。executor端修改了变量,根本不会让driver端跟着修改,这个就是累加器出现的原因。
累加器的作用:
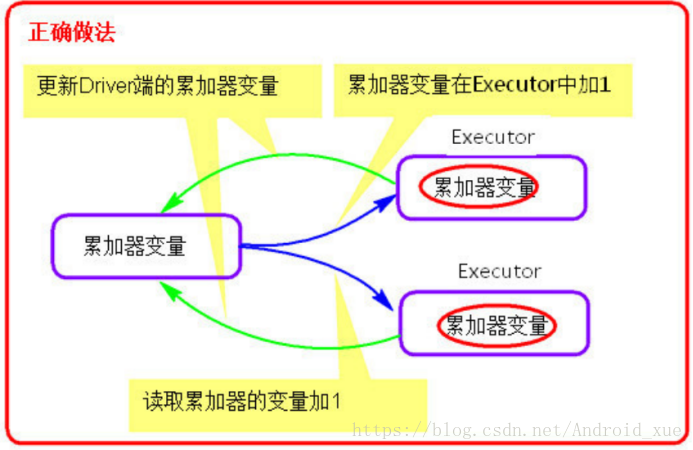
提供了将工作节点中的值聚合到驱动器程序中的简单语法。(如下图)
常用场景:
调试时对作业执行过程中的事件进行计数。

累加器的用法如下所示:
(1)通过在driver中调用 SparkContext.accumulator(initialValue) 方法,创建出存有初始值的累加器。返回值为 org.apache.spark.Accumulator[T] 对象,其中 T 是初始值initialValue 的类型。
(2)Spark闭包(函数序列化)里的executor代码可以使用累加器的 += 方法(在Java中是 add )增加累加器的值。
(3)driver程序可以调用累加器的 value 属性(在 Java 中使用 value() 或 setValue() )来访问累加器的值。
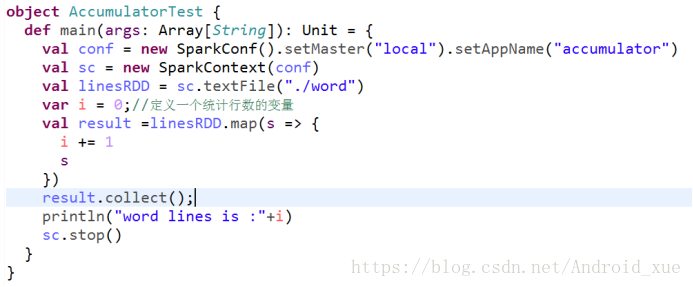
案例如下:
object AccumulatorTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("accumulator")
val sc = new SparkContext(conf)
val accumulator = sc.accumulator(); //创建accumulator并初始化为0
val linesRDD = sc.textFile("./word")
val result = linesRDD.map(s => {
accumulator.add() //有一条数据就增加1
s
})
result.collect();
println("words lines is :" + accumulator.value)
sc.stop()
}
}
输出结果:

注意事项
累加器在Driver端定义赋初始值,累加器只能在Driver端读取,在Executor端更新(如下图)。
Spark共享变量(广播变量、累加器)的更多相关文章
- Spark学习之路 (四)Spark的广播变量和累加器
一.概述 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本.这些变量会被复制到每台机器上 ...
- Spark学习之路 (四)Spark的广播变量和累加器[转]
概述 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本.这些变量会被复制到每台机器上,并 ...
- 【Spark篇】---Spark中广播变量和累加器
一.前述 Spark中因为算子中的真正逻辑是发送到Executor中去运行的,所以当Executor中需要引用外部变量时,需要使用广播变量. 累机器相当于统筹大变量,常用于计数,统计. 二.具体原理 ...
- Spark的广播变量模块
有人问我,如果让我设计广播变量该怎么设计,我想了想说,为啥不用zookeeper呢? 对啊,为啥不用zookeeper,也许spark的最初设计哲学就是尽量不使用别的组件,他有自己分布式内存文件系统, ...
- spark的广播变量
直接上代码:包含了,map,filter,persist,mapPartitions等函数 String master = "spark://192.168.2.279:7077" ...
- Spark RDD持久化、广播变量和累加器
Spark RDD持久化 RDD持久化工作原理 Spark非常重要的一个功能特性就是可以将RDD持久化在内存中.当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内 ...
- Spark(八)【广播变量和累加器】
目录 一. 广播变量 使用 二. 累加器 使用 使用场景 自定义累加器 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的 ...
- Spark——共享变量
Spark执行不少操作时都依赖于闭包函数的调用,此时如果闭包函数使用到了外部变量驱动程序在使用行动操作时传递到集群中各worker节点任务时就会进行一系列操作: 1.驱动程序使将闭包中使用变量封装成对 ...
- SPARK共享变量:广播变量和累加器
Shared Variables Spark does provide two limited types of shared variables for two common usage patte ...
随机推荐
- 【转载】vi/vim使用进阶: 指随意动,移动如飞 (一)
vi/vim使用进阶: 指随意动,移动如飞 (一) << 返回vim使用进阶: 目录 本节所用命令的帮助入口: :help usr_03.txt :help motion.txt :hel ...
- Linux时区详解
全球24个时区的划分 相较于两地时间表,可以显示世界各时区时间和地名的世界时区表(World Time),就显得精密与复杂多了,通常世界时区表的表盘上会标示着全球24个时区的城市名称,但究竟这24个时 ...
- Tensorflow 与Caffe(转)
TensorFlow TensorFlow 是相对高阶的机器学习库,用户可以方便地用它设计神经网络结构,而不必为了追求高效率的实现亲自写 C++或 CUDA 代码.它和 Theano 一样都支持自动求 ...
- perl 里面如何写出阅读友好的代码提示
在我们使用别人写好的程序时,经常会使用-h 之类的东西查看一下简单的帮助手册或者说明信息: 对于perl 语言而言,写起来简单,经常随手一写,解决了当时的问题,但是过几天去看,你都不知道这个脚本该怎么 ...
- 基于物理规则的渲染(PBR)
为毛我的效果那么挫,我也是按照公式来的 2017 -3 -20
- Kibana学习笔记——安装和使用
1.首先下载Kibana https://www.elastic.co/downloads 2.解压 tar -zxvf kibana-6.2.1-linux-x86_64.tar.gz -C ~/s ...
- TensorFlow 1.4利用Keras+Estimator API进行训练和预测
Tensorflow 1.4中,Keras作为作为核心模块可以直接通过tf.keas进行调用,但是考虑到keras对tfrecords文件进行操作比较麻烦,而将keras模型转成tensorflow中 ...
- Centos6.8 下 从零开始 部署 Java Web 应用
一.硬件信息 CPU: [root@localhost ~]# grep 'physical id' /proc/cpuinfo | sort -u | wc -l 2 [root@localhost ...
- 解决ubuntu开机进入grub界面的问题
开机显示GRUB界面显示如下字样,几秒后自动进入登录界面 *Ubuntu Advanced options for Ubuntu .... 解决方案: 1.编辑grub文件 sudo vim /etc ...
- iOS - 跳转到系统设置
一.跳转到自己应用设置(iOS8以上系统推荐使用) //跳转到自己应用干的设置配置页(如 定位.相机.相册 这些隐私配置) [[UIApplication sharedApplication] ope ...