05Hadoop-左外连接
场景:有两张表,一张用户表(user),交易表(transactions)。两张表的字段如下:

两份表数据做个左连接,查询出(商品名,地址)这种格式。
这样就是相当于交易表是左表,不管怎么样数据都要保留,然后从右边里面查出来弥补左表。
效果如下:

思路:写两个map,把两个表的数据都读进来,在reduce端进行连接,然后按照格式要求写出去。
(1)map1:读取transaction文件,封装为:
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, PairOfStrings, PairOfStrings>.Context context)
throws IOException, InterruptedException {
String lines=value.toString();
String[] args=lines.split(" ");
String productID=args[1];
String userID=args[2];
//把outPutKey加了一个2,这么做的目的是,后续在reduce端,聚合时,这个数据能够晚点到达。
outPutKey.set(userID, "2");
outPutValue.set("P", productID);
context.write(outPutKey, outPutValue);
}
(2)map2:读取user文件,封装为:
static class map2 extends Mapper<LongWritable, Text,PairOfStrings,PairOfStrings>
{
PairOfStrings outPutKey=new PairOfStrings();
PairOfStrings outPutvalue=new PairOfStrings();
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, PairOfStrings, PairOfStrings>.Context context)
throws IOException, InterruptedException {
String line=value.toString();
String[] args=line.split(" ");
String userID=args[0];
String locationID=args[1];
//把outPutKey加了一个1,这么做的目的是,后续在reduce端,聚合时,这个数据能够早于transaction文件里面的数据到达。
outPutKey.set(userID, "1");
outPutvalue.set("L", locationID);
context.write(outPutKey, outPutvalue);
}
(3)reduce:把map端的数据要根据用户ID分区,相同的用户ID写入到同一个分区,进而写入到同一个Reduce分区,然后在Reduce中根据PairOfStrings这个类的自己的排序规则对数据排序。因为前面对key做了处理(加了1,2),所以是用户的地址这些信息先到达reduce。,然后根据不同的分组,把数据写出来。
总的代码结构:

LeftCmain:
package com.guigu.left; import java.io.IOException;
import java.util.Iterator; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.MultipleInputs;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat; import edu.umd.cloud9.io.pair.PairOfStrings; public class LeftCmain { //读取transaction文件
static class map1 extends Mapper<LongWritable, Text, PairOfStrings,PairOfStrings>
{
PairOfStrings outPutKey=new PairOfStrings();
PairOfStrings outPutValue=new PairOfStrings(); @Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, PairOfStrings, PairOfStrings>.Context context)
throws IOException, InterruptedException {
String lines=value.toString();
String[] args=lines.split(" ");
String productID=args[1];
String userID=args[2];
outPutKey.set(userID, "2");
outPutValue.set("P", productID);
context.write(outPutKey, outPutValue);
} } //读取user文件
static class map2 extends Mapper<LongWritable, Text,PairOfStrings,PairOfStrings>
{
PairOfStrings outPutKey=new PairOfStrings();
PairOfStrings outPutvalue=new PairOfStrings();
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, PairOfStrings, PairOfStrings>.Context context)
throws IOException, InterruptedException {
String line=value.toString();
String[] args=line.split(" ");
String userID=args[0];
String locationID=args[1];
outPutKey.set(userID, "1");
outPutvalue.set("L", locationID);
context.write(outPutKey, outPutvalue);
} } /**
* 这个的关键点在于,取出的数据:要求先取出地址的数据。
* @author Sxq
*
*/
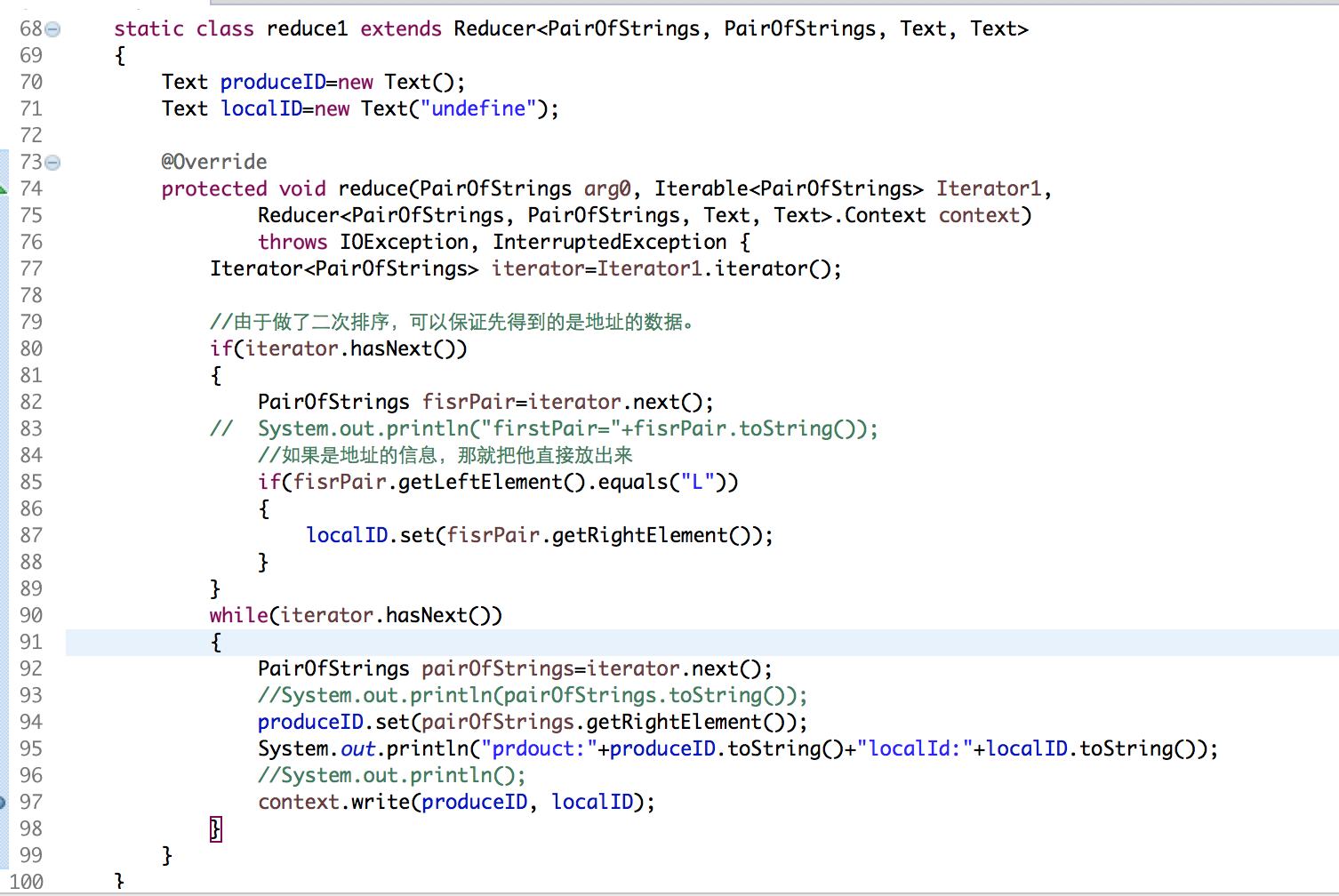
static class reduce1 extends Reducer<PairOfStrings, PairOfStrings, Text, Text>
{
Text produceID=new Text();
Text localID=new Text("undefine"); @Override
protected void reduce(PairOfStrings arg0, Iterable<PairOfStrings> Iterator1,
Reducer<PairOfStrings, PairOfStrings, Text, Text>.Context context)
throws IOException, InterruptedException {
Iterator<PairOfStrings> iterator=Iterator1.iterator(); //由于做了二次排序,可以保证先得到的是地址的数据。
if(iterator.hasNext())
{
PairOfStrings fisrPair=iterator.next();
// System.out.println("firstPair="+fisrPair.toString());
//如果是地址的信息,那就把他直接放出来
if(fisrPair.getLeftElement().equals("L"))
{
localID.set(fisrPair.getRightElement());
}
}
while(iterator.hasNext())
{
PairOfStrings pairOfStrings=iterator.next();
//System.out.println(pairOfStrings.toString());
produceID.set(pairOfStrings.getRightElement());
System.out.println("prdouct:"+produceID.toString()+"localId:"+localID.toString());
//System.out.println();
context.write(produceID, localID);
}
}
} public static void main(String[] args) throws Exception { Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(LeftCmain.class); job.setMapperClass(map1.class);
job.setReducerClass(reduce1.class); job.setMapOutputKeyClass(PairOfStrings.class);
job.setMapOutputValueClass(PairOfStrings.class);
job.setOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setSortComparatorClass(PairOfStrings.Comparator.class); // 在Reduce端设置分组,使得同一个用户在同一个组,然后做拼接。
job.setGroupingComparatorClass(SecondarySortGroupComparator.class);
// 设置分区
job.setPartitionerClass(SecondarySortParitioner.class);
// job.setOutputFormatClass(SequenceFileOutputFormat.class);
Path transactions=new Path("/Users/mac/Desktop/transactions.txt");
MultipleInputs.addInputPath(job,transactions,TextInputFormat.class,map1.class);
MultipleInputs.addInputPath(job,new Path("/Users/mac/Desktop/user.txt"), TextInputFormat.class,map2.class);
FileOutputFormat.setOutputPath(job, new Path("/Users/mac/Desktop/flowresort"));
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1); } }
SecondarySortGroupComparator:
package com.guigu.left;
import org.apache.hadoop.io.DataInputBuffer;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator; import com.book.test1.CompositeKey; import edu.umd.cloud9.io.pair.PairOfStrings; /**
* 不同分区的组聚合时,可以按照我们要的顺序来排列
* @author Sxq
*WritableComparator
*/
public class SecondarySortGroupComparator extends WritableComparator { public SecondarySortGroupComparator() {
super(PairOfStrings.class,true);
} @Override
public int compare(WritableComparable a, WritableComparable b) { PairOfStrings v1=(PairOfStrings)a;
PairOfStrings v2=(PairOfStrings)b;
return v1.getLeftElement().compareTo(v2.getLeftElement());
} }
SecondarySortParitioner:
package com.guigu.left; import org.apache.hadoop.mapreduce.Partitioner; import edu.umd.cloud9.io.pair.PairOfStrings;
/**
*
* @author Sxq
*
*/
public class SecondarySortParitioner extends Partitioner<PairOfStrings, Object>{ @Override
public int getPartition(PairOfStrings key, Object value, int numPartitions) {
return (key.getLeftElement().hashCode()&Integer.MAX_VALUE)%numPartitions;
} }
运行结果:

05Hadoop-左外连接的更多相关文章
- 深入理解SQL的四种连接-左外连接、右外连接、内连接、全连接(转)
1.内联接(典型的联接运算,使用像 = 或 <> 之类的比较运算符).包括相等联接和自然联接. 内联接使用比较运算符根据每个表共有的列的值匹配两个表中的行.例如,检索 stude ...
- 【转】深入理解SQL的四种连接-左外连接、右外连接、内连接、全连接
[原文]:http://www.jb51.net/article/39432.htm 1.内联接(典型的联接运算,使用像 = 或 <> 之类的比较运算符).包括相等联接和自然联接. ...
- [原创]java WEB学习笔记91:Hibernate学习之路-- -HQL 迫切左外连接,左外连接,迫切内连接,内连接,关联级别运行时的检索策略 比较。理论,在于理解
本博客的目的:①总结自己的学习过程,相当于学习笔记 ②将自己的经验分享给大家,相互学习,互相交流,不可商用 内容难免出现问题,欢迎指正,交流,探讨,可以留言,也可以通过以下方式联系. 本人互联网技术爱 ...
- [原创]java WEB学习笔记88:Hibernate学习之路-- -Hibernate检索策略(立即检索,延迟检索,迫切左外连接检索)
本博客的目的:①总结自己的学习过程,相当于学习笔记 ②将自己的经验分享给大家,相互学习,互相交流,不可商用 内容难免出现问题,欢迎指正,交流,探讨,可以留言,也可以通过以下方式联系. 本人互联网技术爱 ...
- MyBatis 内连接association 左外连接collection
前提条件: 学生表 (多 子表) 年级表(一 主表) 1,第一种情况:先查子表所有 student.sql.xml文件如何配 由于有多表连接,无法把查询结果直接封装成一个实体对象--------& ...
- SQL 四种连接:内连接、左外连接、右外连接、全连接--转载
原文:http://zwdsmileface.iteye.com/blog/2191730 个人理解 内连接(INNER JOIN)(典型的连接运算,使用像 = 或 <> ...
- sql的交叉连接,内连接,左外连接,右外连接,全外连接总结
实践是最好的检验,一直都对这几个连接查询出来的结果有什么不同不大理解,然后自己放一块查询比较了一下,用结果来说话~ 先建两张表如下: t1: id name age 1 张三 18 2 李四 25 t ...
- 在查询用户的权限的时候 使用左外连接 和 access数据库中左外连接
一般做视图最好是做成左外连接的.而其作用尤其在我们查询用户当前的权限时尤为明显,我们将 权限表即模块表放→角色权限表→角色表→用户角色表→用户表 就这样left outer join 连接起来,这样就 ...
- mysql的内连接,外连接(左外连接,右外连接)巩固
1:mysql的内连接: 内连接(inner join):显示左表以及右表符合连接条件的记录: select a.goods_id,a.goods_name,b.cate_name from tdb_ ...
- 内连接、左外连接、右外连接、全外连接、交叉连接(CROSS JOIN)-----小知识解决大数据攻略
早就听说了内连接与外连接,以前视图中使用过.这次自考也学习了,只是简单理解,现在深入探究学习(由于上篇博客的出现)与实践: 概念 关键字: 左右连接 数据表的连接有: 1.内连接(自然连接): 只有两 ...
随机推荐
- centos7下使用yum安装pip
centos7下使用yum安装pip 首先安装epel扩展源: yum -y install epel-release 更新完成之后,就可安装pip: yum -y install python-pi ...
- ES6基础语法
1. 什么是ECMAScript ECMAScript是一种由Ecma国际(前身为欧洲计算机制造商协会,英文名称是European Computer Manufacturers Association ...
- VirtWire 向客服发ticket
1 首先需要登录自己的账户 2 点击网页的Open Ticket 3 选择要发送何种类型的ticket 4 写自己的问题,包括一个合适的主题,选择你发ticket是针对哪个vps(一个账户下可以ord ...
- 潭州课堂25班:Ph201805201 爬虫高级 第十一课 Scrapy-redis分布 项目实战 (课堂笔
- mongodb副本集与分片结合
1.在三个不同服务器上,分别建立副本集: 202服务器: 192.8.123.202:27017 replSet = r202 192.8.123.202:27018 replSet = r202 1 ...
- [HNOI2010]平面图判定
Description: 若能将无向图 \(G=(V, E)\) 画在平面上使得任意两条无重合顶点的边不相交,则称 \(G\) 是平面图.判定一个图是否为平面图的问题是图论中的一个重要问题.现在假设你 ...
- Flask路由
@app.route() methods:当前url地址,允许访问的请求方式 @app.route("/info", methods=["GET", " ...
- jquery中遍历
1.jQuery--Dom遍历 1)jquery遍历---祖先元素 parents() 方法返回被选元素的所有祖先元素,它一路向上直到文档的根元素 (<html>).也可以使用可选参数来过 ...
- 前端可视化数据--echarts
很幸运能够给大家分享我对echarts的见解,在一些大型互联网公司面试时都会问到会使用echarts么? 今天在做项目时有这个需求,有幸学习echarts. 二.echarts.js的优势与不足 优 ...
- Kafka监控框架介绍
前段时间在想Kafka怎么监控.怎么知道生产的消息或消费的消费是否有丢失,目前有几个开源的Kafka监控框架这里整理了下,不过这几个框架都有各自的问题侧重点不一样: 1.Kafka Monitor 2 ...