Hadoop集群datanode磁盘不均衡的解决方案【转】
一、引言:

<property>
<name>dfs.datanode.du.reserved</name>
<value>107374182400</value>
</property>
上面这个参数的意思:
Reserved space in bytes per volume. Always leave this much space free for non dfs use.
再查看datanode日志,希望能找到可靠的线索:

这种错误无法通过namenode来避免,因为它不会再failed的时候去尝试往别的节点写数, 最初的办法是将该节点的datanode关闭掉,就能顺利地跑完这个mapreduce。
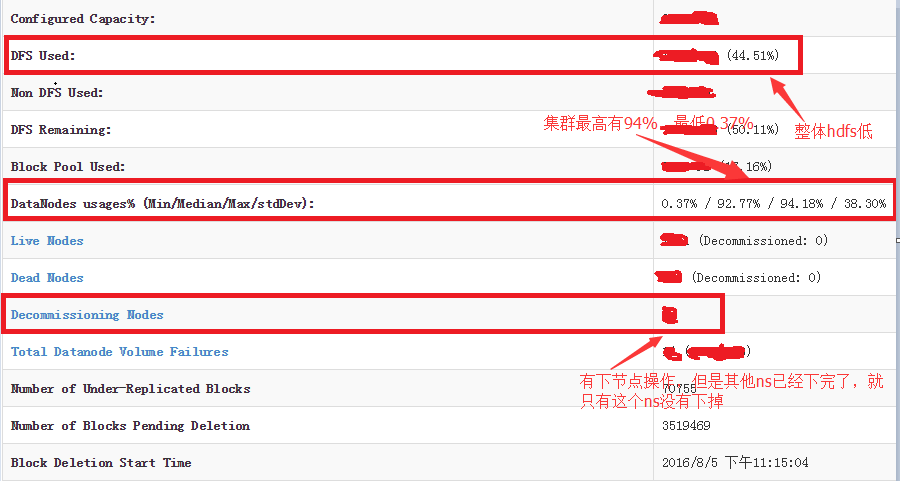
再者查看namenode的页面,看到有好多datanode的节点的Remaining快要趋于0B了,这个时候就很容易出现上面的报错。

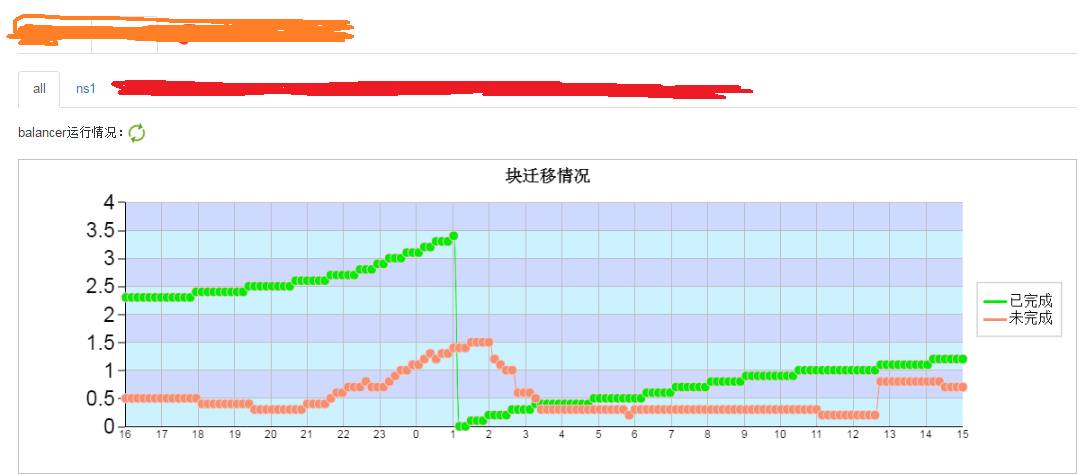
The balancer is a tool that balances disk space usage on an HDFS cluster when some datanodes become full or when new empty nodes join the cluster.
The tool is deployed as an application program that can be run by the cluster administrator on a live HDFS cluster while applications adding and deleting files.
下面的图片是官网中balancer命令得详解:

start-balancer.sh -threshold 20 -policy blockpool -include -f /tmp/ip.txt
<property>
<name>dfs.datanode.balance.bandwidthPerSec</name>
<value>10485760</value>
</property>
但是这个需要重启,hadoop提供了一个动态调整的命令:
hdfs dfsadmin -fs hdfs://ns1:8020 -setBalancerBandwidth 104857600
hdfs dfsadmin -fs hdfs://ns2:8020 -setBalancerBandwidth 104857600
hdfs dfsadmin -fs hdfs://ns3:8020 -setBalancerBandwidth 104857600
hdfs dfsadmin -fs hdfs://ns4:8020 -setBalancerBandwidth 104857600
hdfs dfsadmin -fs hdfs://ns5:8020 -setBalancerBandwidth 104857600
hdfs dfs -get hdfs://ns1/test/dt=2016-07-24/000816_0.lzo hdfs dfs -put -f 000816_0.lzo hdfs://ns1/test/dt=2016-07-24/000816_0.lzo hdfs dfs -chown dd_edw:dd_edw hdfs://ns1/test/dt=2016-07-24/000816_0.lzo
前提条件需要将这个节点的datanode重新启动。
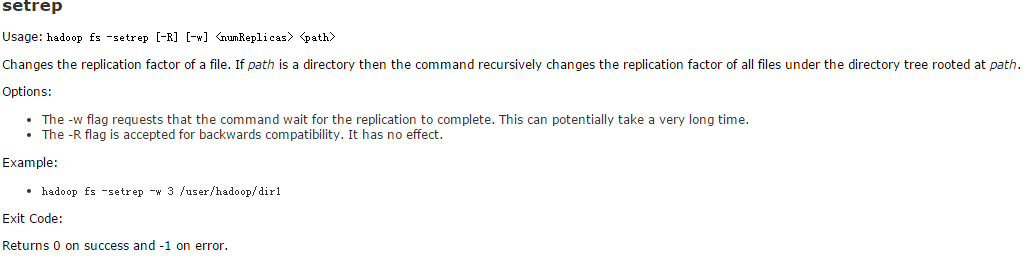
hdfs dfs -setrep -R -w 2 hdfs://ns1/tmp/test.db
升副本的命令如下:
hdfs dfs -setrep -R -w 3 hdfs://ns1/tmp/test.db
上面的命令是将ns1下的/tmp/test.db副本数降至2个,然后又将它升至3哥副本。具体的hdfs dfs -setrep命令如下图:
这样动态的升降副本可以解决。
另外在升降副本的遇到一个BUG:

推测可能是namenode的replications模块有夯住情况,所以出现该情况执行kill掉进行,跳过该块再跑!
总结:之所以选择使用升降副本是因为它不受带宽的控制,另外在升降副本的时候hadoop是需要重新写数的,这个时候它会优先往磁盘低写数据,这样就能将磁盘高的数据迁移至磁盘低的。
4、distcp
DistCp (distributed copy) is a tool used for large inter/intra-cluster copying. It uses MapReduce to effect its distribution, error handling and recovery, and reporting. It expands a list of files and directories into input to map tasks, each of which will copy a partition of the files specified in the source list. Its MapReduce pedigree has endowed it with some quirks in both its semantics and execution. The purpose of this document is to offer guidance for common tasks and to elucidate its model.
在这里举一个例子:

通过distcp将/tmp/output12上的数据调用mapreduce迁移至/tmp/zhulh目录下,原先/tmp/output12上的数据还是有存在的,但是它的块就发生了变化。
这个时候有人可能会说怎么不使用cp命令呢?
两者的区别如下:
CP的模式是不走mapreduce的;DISTCP的模式是走mapreduce的,所以它优先写有nodemanager的机器;
CP是单线程的,类似scp的模式,在执行速度上比DISTCP要慢很多。
5、提高dfs.datanode.du.reserved值
官网是这么说的:Reserved space in bytes per volume. Always leave this much space free for non dfs use.
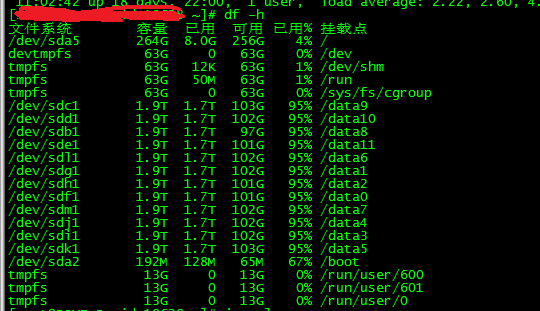
在上面的提到dfs.datanode.du.reserved的值是设成100G,因为namenode认为该节点还有剩余的空间,所以给分配到这里,假如这个块是128K,但是实际剩余空间只有100K,所以就会报上面的错误,假如把dfs.datanode.du.reserved成300G,让namenode知道该节点已经没有剩余空间,所以就不会往这里写数据了。
6、关闭nodemanger进程
在现有计算资源多余的情况下,可以考虑关闭高磁盘节点的nodemanager,避免在该节点起YarnChild,因为如果在该节点上进行计算的话,数据存储首先会往本地写一份,这样更加加重了本地节点的负担。
7、删除旧数据
该方案是在迫不得已的情况下进行的,因为删掉的数据可能以后还得补回来,这样的话又是得要浪费一定的时间。
另外在删除数据时候就得需要跳过回收站才能算是真正删除,可以使用的命令如下:

本篇文章主要介绍了对hadoop数据出现不均衡情况下可以使用的方案,并以实例来解决问题!
对此有兴趣的同学欢迎一起交流 。
Hadoop集群datanode磁盘不均衡的解决方案【转】的更多相关文章
- Hadoop集群datanode磁盘不均衡的解决方案
一.引言: Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,比如集群中添加新的数据节点,节点与节点之间磁盘大小不一样等等.当hdfs出现不平衡状况的时候,将引发很多问题,比 ...
- Hadoop集群datanode死掉或者secondarynamenode进程消失处理办法
当Hadoop集群的某单个节点出现问题时,一般不必重启整个系统,只须重启这个节点,它会自动连入整个集群. 在坏死的节点上输入如下命令即可: hadoop-daemon.sh start datanod ...
- eclipse连接远程hadoop集群开发时权限不足问题解决方案
转自:http://blog.csdn.net/shan9liang/article/details/9734693 eclipse连接远程hadoop集群开发时报错 Exception in t ...
- 【转】Hadoop集群添加磁盘步骤
转自:http://blog.csdn.net/huyuxiang999/article/details/17691405 一.实验环境 : 1.硬件:3台DELL服务器,CPU:2.27GHz*16 ...
- 阿里云Hadoop集群DataNode连接不上NameNode
在logs日志中可以看见DataNode多次去连NameNode,但是都失败了. 经过长时间的研究百度,终于知道了原因. 原因就是安全组限制了端口的开放,所以我们只要把相应的端口打开即可.
- hadoop集群namenode同时挂datanode
背景:(测试环境)只有两台机器一台namenode一台namenode,但集群只有一个结点感觉不出来效果,在namenode上挂一个datanode就有两个节点,弊端见最后 操作非常简单(添加独立节点 ...
- Hadoop集群启动之后,datanode节点未正常启动的问题
Hadoop集群启动之后,用JPS命令查看进程发现datanode节点上,只有TaskTracker进程.如下图所示 master的进程: 两个slave的节点进程 发现salve节点上竟然没有dat ...
- 关于hadoop集群下Datanode和Namenode无法访问的解决方案
HDFS架构 HDFS也是按照Master和Slave的结构,分namenode,secondarynamenode,datanode这几个角色. Namenode:是maseter节点,是大领导.管 ...
- hadoop 集群 master datanode 没有启动
2018-02-07 02:47:50,377 WARN org.apache.hadoop.hdfs.server.common.Storage: java.io.IOException: Inco ...
随机推荐
- 谷歌浏览器把网页打印成pdf
一.认识markdown mweb for mac2.2.7 激活版 二.pdf和word pdf的可移植性比较好,在不同的操作系统中都能打开,而且安全,但是可编辑性不好,所以通常用markdown编 ...
- RCNN系列超详细解析
一.基于Region Proposal(候选区域)的深度学习目标检测算法 Region Proposal(候选区域),就是预先找出图中目标可能出现的位置,通过利用图像中的纹理.边缘.颜色等信息,保证在 ...
- Java笔记(十七) 异步任务执行服务
异步任务执行服务 一.基本原理和概念 一)基本接口 1)Runnable和Callable:表示要执行的异步任务. 2)Executor和ExecutorService:表示执行服务. 3)Futur ...
- 你真的了解META-INF吗?
你真的了解META-INF吗? 做过JAVA EE开发的工程师应该都知道在JAVA build出来的JAR或者WAR的顶层目录下有个META-INF文件夹吧,可是有多少人能够清楚说出这个文件夹到底是做 ...
- Java转型
集合转型 通过中间类型List List<String> strs=new ArrayList<>(); List list=(List)strs; List<Objec ...
- BZOJ4437 : [Cerc2015]Looping Labyrinth
从$(0,0)$开始BFS$2\times10^6$步,那么迷宫的形状有三种: 1.走不完$2\times10^6$步,直接判定即可. 2.可以走到$(n,0)$以及$(0,m)$,那么直接把询问点平 ...
- HTML(三)
html图像.绝对路径和相对路径 html图像 <img>标签可以在网页上插入一张图片,它是独立使用的标签,通过“src”属性定义图片的地址,通过“alt”属性定义图片加载失败时显示的文字 ...
- 子串 [NOIP2015]
Description 有两个仅包含小写英文字母的字符串 A 和 B.现在要从字符串 A 中取出 k 个互不重叠的非空子串,然后把这 k 个子串按照其在字符串 A 中出现的顺序依次连接起来得到一 个新 ...
- Sklearn线性回归
Sklearn线性回归 原理 线性回归是最为简单而经典的回归模型,用了最小二乘法的思想,用一个n-1维的超平面拟合n维数据 数学形式 \[y(w,x)=w_0+w_1x_1+w_2x_2+-+w_nx ...
- Python类的几点笔记
1. class A: def __init__(self, a, b): self.a = a self.b = b print(a, b) class B(A): def __init__(sel ...