[3]java1.8线程池—ThreadPoolExecutor
Wiki 上是这样解释的:Thread Pool

作用:利用线程池可以大大减少在创建和销毁线程上所花的时间以及系统资源的开销!
下面主要讲下线程池中最重要的一个类 ThreadPoolExecutor 。
看到池这关键字,第一反应会是线程能缓存起来。请原谅我这个Java入门汉蹩脚的想象。
我会这么想,实例化出线程A、线程B,然后把A、B线程放入容器,再写个循环while,每次执行时从容器中取出线程的引用,然后传递任务Runnable给线程执行。
但认真的研究了一边Java线程的调用和生命周期之后,上面的想象是无从实现的。
1.线程的任务Runnable需在线程创建之前传递,线程在存活期就已经捆绑了Runnable,不能再次传递Runnale去执行。
2.线程获取的CPU分派后,执行完Runnable的Run方法,线程就已经死亡了。不可能再次发起执行(Java线程生命周期)。
所以,线程池中的线程是缓存起来的,可取出调用,执行完毕后可重新放入的逻辑是不对的。
那么线程池是什么概念呢?
个人理解是保持了多个线程是存活(running,没有执行完毕)的一种状态,然后有个变量对它们线程的引用进行了存储,而这就是线程池的容器。
池中的线程被设计成外部不可取出调用的,因为在调用了线程池ThreadPoolExecutor的execute方法后,线程已经被创建并执行,并没有线程的引用暴露出来。
一个原因是为了封装保护,二是因为线程已经是running状态了,线程的执行能力已经在使用中,执行能力已经无法释放了!
其中Worker对象中的内部线程,通过本身Worker中的Run方法中的一个阻塞循环体来实现线程长期存活的。
线程池是指已经或者将要 有指定个数的线程执行while循环,不停的阻塞消费BlockingQueue队列中提交的外部Runnable,同时内部的线程不会被销毁(因为while会被阻塞)的一种表现或能力。
下面来讲讲线程池ThreadPoolExecutor类:
创建线程池pool
public static void main(String[] args) {
//核心线程数量为 2,最大线程数量 4,空闲线程存活的时间 60s,有界队列长度为 3
ThreadPoolExecutor pool = new ThreadPoolExecutor(2, 4, 60, TimeUnit.SECONDS,
new ArrayBlockingQueue<Runnable>(3));
for (int i = 1; i <= 10; i++) {
//创建 10 个任务
//运行
pool.execute(new Runnable() {
@Override
public void run() {
System.out.println("任务已执行");
}
});
System.out.println("活跃的线程数:"+pool.getActiveCount() + ",核心线程数:" + pool.getCorePoolSize() + ",线程池大小:" + pool.getPoolSize() + ",队列的大小" + pool.getQueue().size());
}
//关闭线程池
pool.shutdown();
}
通过for循环提交了十个Runnable任务给了线程池pool,调用了ThreadPoolExecutor实例中的execute方法。
然后我们查看一下ThreadPoolExecutor实例中execute方法,发现做了worker数量的判断和创建方法addWorker()的调用。
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
// 1、如果当前的线程数小于核心线程池的大小,根据现有的线程作为第一个 Worker 运行的线程,新建一个 Worker,
// addWorker 自动的检查当前线程池的状态和 Worker 的数量,防止线程池在不能添加线程的状态下添加线程
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//2、如果线程入队成功,然后还是要进行 double-check 的,因为线程在入队之后状态是可能会发生变化的
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// recheck 防止线程池状态的突变,如果突变,那么将 reject 线程,防止 workQueue 中增加新线程
if (! isRunning(recheck) && remove(command))
reject(command);
//上下两个操作都有 addWorker 的操作,但是如果在workQueue.offer 的时候 Worker 变为 0,那么将没有 Worker 执行新的 task,所以增加一个Worker.
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//3、如果 task 不能入队(队列满了),这时候尝试增加一个新线程,如果增加失败那么当前的线程池状态变化了或者线程池已经满了然后拒绝task
else if (!addWorker(command, false))
reject(command);
}
我们看到,最终是通过调用addWorker()方法来创建线程的。我们再看看addWorker()方法,该方法判断了线程的数量,同时实例化一个Worker类并执行了其内部捆绑的线程。
// firstTask: 新增一个线程并执行这个任务,可空,增加的线程从队列获取任务;core:是否使用 corePoolSize 作为上限,否则使用 maxmunPoolSize
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
/**
* rs!=Shutdown || fistTask!=null || workQueue.isEmpty
* 如果当前的线程池的状态 > SHUTDOWN 那么拒绝 Worker 的 add 如果 =SHUTDOWN
* 那么此时不能新加入不为 null 的 Task,如果在 workQueue 为 empty 的时候不能加入任何类型的 Worker,
* 如果不为 empty 可以加入 task 为 null 的 Worker, 增加消费的 Worker
*/
if (rs >= SHUTDOWN && ! (rs == SHUTDOWN && firstTask == null &&! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
//如果当前的数量超过了 CAPACITY,或者超过了 corePoolSize 和 maximumPoolSize(试 core 而定)
if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize))
return false;
//CAS 尝试增加线程数,如果失败,证明有竞争,那么重新到 retry。
if (compareAndIncrementWorkerCount(c))// AtomicInteger 的 CAS 操作;
break retry;
c = ctl.get(); // Re-read ctl
//判断当前线程池的运行状态,状态发生改变,重试 retry;
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
// Worker 为内部类,封装了线程和任务,通过 ThreadFactory 创建线程,可能失败抛异常或者返回 null
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
// SHUTDOWN 以后的状态和 SHUTDOWN 状态下 firstTask 为 null,不可新增线程
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;//记录最大线程数
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
//执行worker中捆绑的线程
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
//失败回退,从 wokers 移除 w, 线程数减一,尝试结束线程池(调用tryTerminate 方法)
addWorkerFailed(w);
}
return workerStarted;
}
上面标红的代码,就是启动了Worker类中内部的一个线程。然后该线程以Worker本身实例为Runnable参数,线程启动之后将会常驻内存中执行。我们再看一下Worker这个内部类
/**
* Worker本身就是一个任务,把自己当做任务传递给Thread类,来实例化出一个线程能力。
*/
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
//捆绑的线程,也就是线程池中的真正线程,是该线程在处理不断提交的外部任务Runnable
final Thread thread; //捆绑的外部任务Runnable实例
Runnable firstTask;
/** Per-thread task counter */
volatile long completedTasks; /**
* 构造器
* @param firstTask
*/
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
//通过外部传递的线程构造工厂实例 或 默认的内部线程工厂类来创建线程
this.thread = getThreadFactory().newThread(this);
} /**
* 执行当前worker,也就是调用外部类ThreadPoolExecutor的runWorker
*/
public void run() {
runWorker(this);
} // Lock methods
//
// The value 0 represents the unlocked state.
// The value 1 represents the locked state.
protected boolean isHeldExclusively() {
return getState() != 0;
} protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
} protected boolean tryRelease(int unused) {
setExclusiveOwnerThread(null);
setState(0);
return true;
} public void lock() { acquire(1); }
public boolean tryLock() { return tryAcquire(1); }
public void unlock() { release(1); }
public boolean isLocked() { return isHeldExclusively(); } void interruptIfStarted() {
Thread t;
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}
}
Worker类本身实现了Runnable接口,具备被线程执行的能力。所以addWorker()方法实例化一个Worker类后,启动了它捆绑的内部线程,并执行之。
然后就会执行Worker的run方法,也就是调用下面的ThreadPoolExecutor类的runWorker方法。
/**
* 执行Worker中捆绑的Runnable
* @param w
*/
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
//循环获取队列中的外部提交过来的Runnable任务
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
//执行我们通过调用execute方法提交给线程池的Runnable任务
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
然后通过循环调用getTask()方法,从BlockingQueue阻塞队列中,取出的外部提交至线程池的Ruannable任务实例。
并执行外部任务Runnable的run方法。从而执行到了我们外部的业务代码。
我们看一下getTask()方法,该方法是阻塞取的。队列中一旦没有新的任务提交过来,那么getTask方法将会阻塞执行,直到有新的外部任务Runnable实例提交进来。
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// Are workers subject to culling?
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
//从阻塞队列BlockingQueue中获取任务
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
内部的四个线程是共享阻塞队列BlockingQueue的,4个线程通过 runWorker() 方法中的 while 和 getTask() 这个阻塞方法,获得了不进入线程死亡状态(java线程生命周期的图示)的能力。
至此,线程池的执行流程就大概清晰了。线程池类就是帮助我们管理线程,同时执行我们外部提交的任务、并提供监控的一个包装类。
执行流程:
1、当有任务进入时,线程池创建线程(Worker类)去执行任务,直到核心线程数(Worker实例数)满为止。
2、核心线程数量满了之后,任务就会进入一个缓冲的阻塞任务队列中
- 当任务队列为无界队列时,任务就会一直放入缓冲的任务队列中,不会和最大线程数量进行比较
- 当任务队列为有界队列时,任务先放入缓冲的任务队列中,当任务队列满了之后,才会将任务放入线程池,此时会与线程池中最大的线程数量进行比较,如果超出了,则默认会抛出异常。然后线程池才会执行任务,当任务执行完,又会将缓冲队列中的任务放入线程池中,然后重复此操作。
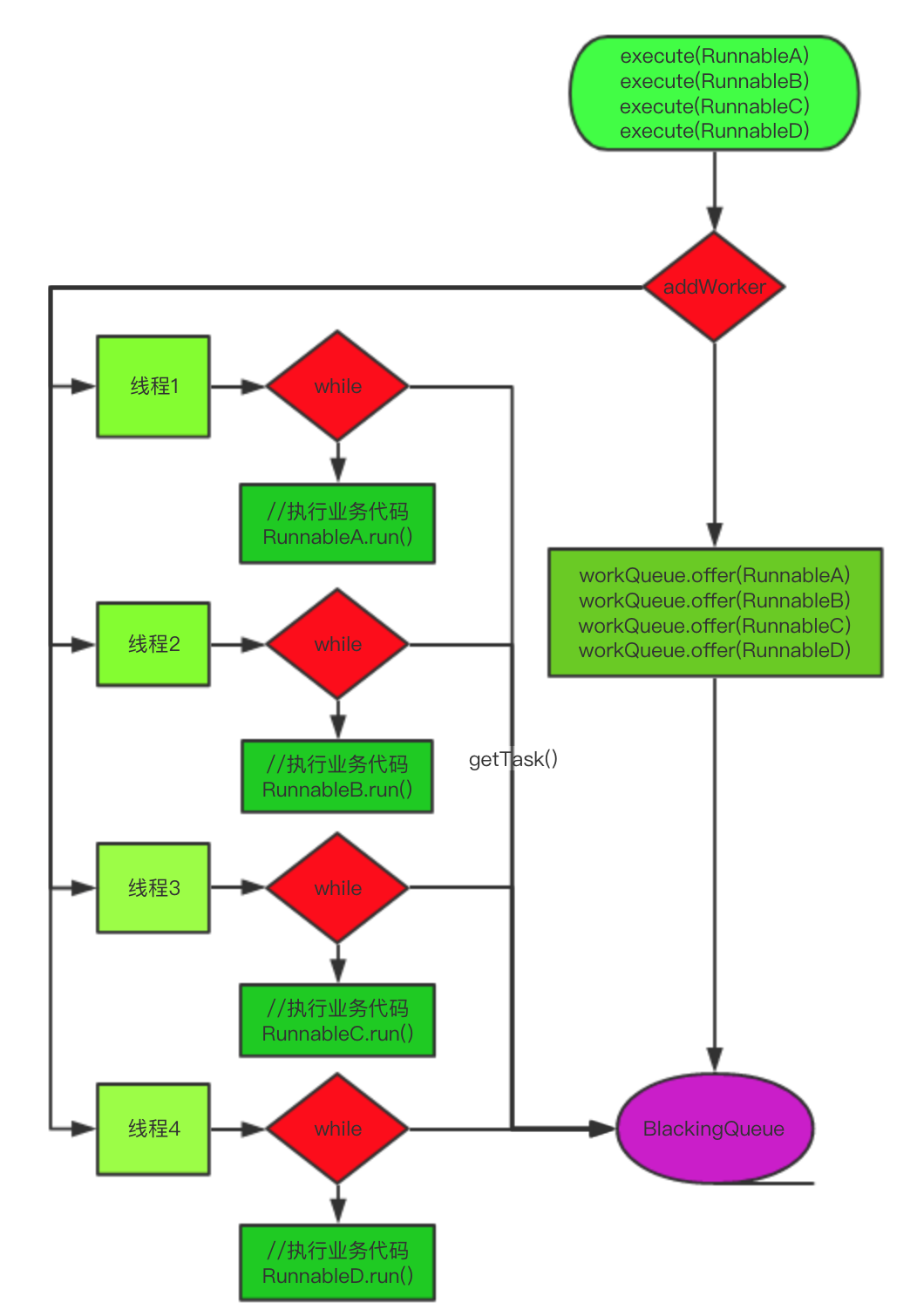
其中最核心的是 利用了 阻塞队列BlockingQueue 和 循环while,还有拒绝任务机制reject,同时巧妙的把任务 Runnable 和 Thread 捆绑在 一个 Worker 类上。
其实可以不需要Worker类的存在,可以先添加Runnable到阻塞队列中,再利用线程去循环取出消费也能实现。
我们自己也可以设计一个线程池类,不过官方已经提供了这么好的实现,就没必要重复造轮子了,我们明白其中的设计思想即可!
ps:
深入理解java线程池—ThreadPoolExecutor
[3]java1.8线程池—ThreadPoolExecutor的更多相关文章
- java线程池ThreadPoolExecutor使用简介
一.简介线程池类为 java.util.concurrent.ThreadPoolExecutor,常用构造方法为:ThreadPoolExecutor(int corePoolSize, int m ...
- 线程池ThreadPoolExecutor
线程池类为 java.util.concurrent.ThreadPoolExecutor,常用构造方法为: ThreadPoolExecutor(int corePoolSize, int maxi ...
- 关于线程池ThreadPoolExecutor使用总结
本文引用自: http://blog.chinaunix.net/uid-20577907-id-3519578.html 一.简介 线程池类为 java.util.concurrent.Thread ...
- [转] 引用 Java自带的线程池ThreadPoolExecutor详细介绍说明和实例应用
PS: Spring ThreadPoolTaskExecutor vs Java Executorservice cachedthreadpool 引用 [轰隆隆] 的 Java自带的线程池Thre ...
- android线程池ThreadPoolExecutor的理解
android线程池ThreadPoolExecutor的理解 线程池 我自己理解看来.线程池顾名思义就是一个容器的意思,容纳的就是ThreadorRunable, 注意:每一个线程都是需要CPU分配 ...
- 线程池ThreadPoolExecutor使用简介
一.简介 线程池类为 java.util.concurrent.ThreadPoolExecutor,常用构造方法为: ThreadPoolExecutor(int corePoolSize, int ...
- 线程池ThreadPoolExecutor使用简介(转)
一.简介 线程池类为 java.util.concurrent.ThreadPoolExecutor,常用构造方法为: ThreadPoolExecutor(int corePoolSize, int ...
- java线程API学习 线程池ThreadPoolExecutor(转)
线程池ThreadPoolExecutor继承自ExecutorService.是jdk1.5加入的新特性,将提交执行的任务在内部线程池中的可用线程中执行. 构造函数 ThreadPoolExecut ...
- Java线程池ThreadPoolExecutor使用和分析(三) - 终止线程池原理
相关文章目录: Java线程池ThreadPoolExecutor使用和分析(一) Java线程池ThreadPoolExecutor使用和分析(二) - execute()原理 Java线程池Thr ...
随机推荐
- 最短路:spfa算法
板子补完计划绝赞继续中( 这篇博客就来写一写spfa(这我居然板子都打错了一次,我太弱啦!) 先来看一下定义:(引自http://blog.csdn.net/juststeps/article/det ...
- js float运算精度问题
先放个前辈的文章:JavaScript数字精度丢失问题总结 今天遇到了19.99*100的问题,答案不等于1999,因为在javascript中浮点数的计算是以2进制计算的.自己写了一波解决方法(不能 ...
- python之函数第一篇
一.为什么用函数: 解决代码重用问题 统一维护 程序的组织结构清晰,可读性强二.定义函数 先定义后使用!! def funcname(arg1,arg2,...): """ ...
- Vue(十八)Element UI
Elment UI 1. 简介 Element UI是饿了么团队提供的一套基于Vue2.0的组件库,可以快速搭建网站,提高开发效率 ElementUI PC端 MintUI 移动端 [官网](http ...
- Ubuntu下实验安装
1.Ubuntu下安装sublime : http://www.linuxidc.com/Linux/2015-01/112137.htm 2.http://www.linuxidc.com/Linu ...
- C#多线程技术提高RabbitMQ消费吞吐率
一.课程介绍 本次分享课程属于<C#高级编程实战技能开发宝典课程系列>中的第二部分,阿笨后续会计划将实际项目中的一些比较实用的关于C#高级编程的技巧分享出来给大家进行学习,不断的收集.整理 ...
- html提交表单到Servlet
源码地址 https://github.com/YouXianMing/Java-Web-Study/tree/master/Servlet-Form 演示效果(注意post与get提交方式浏览器地址 ...
- Mac下不用重复输入ssh-key的密码
重装系统,复用以前的SSH key,发现每次调用这个Key都要输入Key的密码,很繁琐,以前不是这样的哦. 更新代码.SSH服务器总是提示: Enter passphrase for .../id_r ...
- t-SNE 层次聚类
https://zhuanlan.zhihu.com/p/28967965 https://haojunsui.github.io/2016/07/16/scipy-hac/
- 使用多个项目生成Xml文件来显示帮助文档
终于到这了,我们首先将Product单独作为一个项目 WebAPI2PostMan.WebModel 并引用他,查看文档如下. 你会发现,你的注释也就是属性的描述没有了.打开App_Data/XmlD ...