scrapy中selenium的应用
引入
- 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值。但是通过观察我们会发现,通过浏览器进行url请求发送则会加载出对应的动态加载出的数据。那么如果我们想要在scrapy也获取动态加载出的数据,则必须使用selenium创建浏览器对象,然后通过该浏览器对象进行请求发送,获取动态加载的数据值。
今日详情
1.案例分析:
- 需求:爬取网易新闻的国内板块下的新闻数据
- 需求分析:当点击国内超链进入国内对应的页面时,会发现当前页面展示的新闻数据是被动态加载出来的,如果直接通过程序对url进行请求,是获取不到动态加载出的新闻数据的。则就需要我们使用selenium实例化一个浏览器对象,在该对象中进行url的请求,获取动态加载的新闻数据。
2.selenium在scrapy中使用的原理分析:
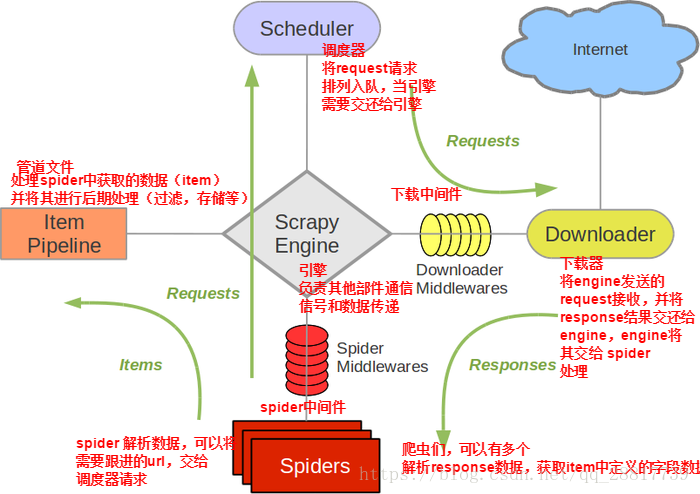
当引擎将国内板块url对应的请求提交给下载器后,下载器进行网页数据的下载,然后将下载到的页面数据,封装到response中,提交给引擎,引擎将response在转交给Spiders。Spiders接受到的response对象中存储的页面数据里是没有动态加载的新闻数据的。要想获取动态加载的新闻数据,则需要在下载中间件中对下载器提交给引擎的response响应对象进行拦截,切对其内部存储的页面数据进行篡改,修改成携带了动态加载出的新闻数据,然后将被篡改的response对象最终交给Spiders进行解析操作。
3.selenium在scrapy中的使用流程:
- 重写爬虫文件的构造方法,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次)
- 重写爬虫文件的closed(self,spider)方法,在其内部关闭浏览器对象。该方法是在爬虫结束时被调用
- 重写下载中间件的process_response方法,让该方法对响应对象进行拦截,并篡改response中存储的页面数据
- 在配置文件中开启下载中间件
4.代码展示:
- 爬虫文件:
class WangyiSpider(RedisSpider):
name = 'wangyi'
#allowed_domains = ['www.xxxx.com']
start_urls = ['https://news.163.com']
def __init__(self):
#实例化一个浏览器对象(实例化一次)
self.bro = webdriver.Chrome(executable_path='/Users/bobo/Desktop/chromedriver')
#必须在整个爬虫结束后,关闭浏览器
def closed(self,spider):
print('爬虫结束')
self.bro.quit()
- 中间件文件:
from scrapy.http import HtmlResponse
#参数介绍:
#拦截到响应对象(下载器传递给Spider的响应对象)
#request:响应对象对应的请求对象
#response:拦截到的响应对象
#spider:爬虫文件中对应的爬虫类的实例
def process_response(self, request, response, spider):
#响应对象中存储页面数据的篡改
if request.url in['http://news.163.com/domestic/','http://news.163.com/world/','http://news.163.com/air/','http://war.163.com/']:
spider.bro.get(url=request.url)
js = 'window.scrollTo(0,document.body.scrollHeight)'
spider.bro.execute_script(js)
time.sleep(2) #一定要给与浏览器一定的缓冲加载数据的时间
#页面数据就是包含了动态加载出来的新闻数据对应的页面数据
page_text = spider.bro.page_source
#篡改响应对象
return HtmlResponse(url=spider.bro.current_url,body=page_text,encoding='utf-8',request=request)
else:
return response
- 配置文件:
DOWNLOADER_MIDDLEWARES = {
'wangyiPro.middlewares.WangyiproDownloaderMiddleware': 543,
}
scrapy中selenium的应用的更多相关文章
- 15.scrapy中selenium的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现 ...
- scrapy中 selenium(中间件) + 语言处理 +mysql
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现,通过 ...
- 15,scrapy中selenium的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生如果直接用scrapy对其url发请求,是获取不到那部分动态加载出来的数据值,但是通过观察会发现,通过浏览器 ...
- 14 Scrapy中selenium的应用
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现,通过 ...
- selenium在scrapy中的使用、UA池、IP池的构建
selenium在scrapy中的使用流程 重写爬虫文件的构造方法__init__,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次). 重写爬虫文件的closed ...
- Scrapy中集成selenium
面对众多动态网站比如说淘宝等,一般情况下用selenium最好 那么如何集成selenium到scrapy中呢? 因为每一次request的请求都要经过中间件,所以写在中间件中最为合适 from se ...
- 在Scrapy中使用selenium
在scrapy中使用selenium 在scrapy中需要获取动态加载的数据的时候,可以在下载中间件中使用selenium 编码步骤: 在爬虫文件中导入webdrvier类 在爬虫文件的爬虫类的构造方 ...
- selenium在scrapy中的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现 ...
- 第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中
第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中 1.爬虫文件 dispatcher.connect()信号分发器,第一个参数信 ...
随机推荐
- Python events
Events不同线程之间同步对象 参数说明: # 实例化event对象 event = threading.Event() # 等待检测标志位被设定,标志位设置后就不阻塞了 # 客户机线程可以等待设置 ...
- centos7救援模式--rescue模式
前序 经典问题:系统无法进入,如grub损坏或某个配置文件改错 操作 1 按方向键到Boot,选到Hard Driver,按减号,使其下移,最终让CD-ROM Drive到第一行,并按F10保存 2 ...
- NPOI解决由于excel删除数据导致空行读取问题
1.解决问题思路一:申明判断是否空行变量用于判断是否空行,声明变量数组用于临时非空行数据,最后存于datatable中. /// <summary>读取excel, /// 默认第一行为表 ...
- JS和Jquery获取和修改label的值
获取值: label标签在JS和Jquery中使用不能像其他标签一样用value获取它的值: var label=document.getElementById("id");var ...
- 浅谈HTTP中GET、POST用法以及它们的区别
浅谈HTTP中GET.POST用法以及它们的区别 HTTP定义了与服务器交互的不同方法,最基本的方法有4种,分别是GET,POST,PUT,DELETE.URL全称是资源描述符.我们可以这样认为: 一 ...
- DDD之BoundedContext
原文 BoundedContext Bounded Context is a central pattern in Domain-Driven Design. It is the focus of D ...
- .NET Core 配置GC工作模式与内存的影响
.NET Core 配置GC工作模式与内存的影响 .NET Core GC 原文:https://blog.markvincze.com/troubleshooting-high-memory-usa ...
- [数据结构]P1.1 链表结构
* 注: 本文/本系列谢绝转载,如有转载,本人有权利追究相应责任. 2019年4月8日 Stan Zhang 2019年4月8日 格物致知,经世致用. [面试题]1.为什么要用链表? 数组具有的缺陷 ...
- SR-IOV虚拟机的MTU与物理网卡的MTU
在进行SR-IOV虚拟机MTU方面的测试时,出现如下情况: 1)物理网卡PF的MTU值是4000: root@compute-1:~# ip l|more1: lo: <LOOPBACK,UP, ...
- CentOS6上ftp服务器搭建实战
1.安装程序包 [root@node1 ~]$ yum install -y vsftpd[root@node1 ~]$ yum install -y lftp # 安装测试软件 2.启动vsftpd ...