Buffer cache hit ratio性能计数器真的可以作为SQL Server 内存瓶颈的判断指标吗?
SQL Server中对于Buffer cache hit ratio的理解:
Buffer cache hit ratio官方是这么解释的:“指示在缓冲区高速缓存中找到而不需要从磁盘中读取的页的百分比。”
Buffer cache hit ratio被很多人当做判断内存的性能指标之一(当然没说仅仅只看这个计数器的值,实际上现在都不怎么看这个值了),
也有不少给给出了具体的参数,诸如(OLTP)要大于95%,或者是大于98%之类的,我不知道给出具体参考值的人是不是真是地区测试过这个参数的值,是作为经验总结还是复制粘贴?
当我去服务器上观察这个值的时候,似乎发现一个规律,
不管服务器的负载如何,即便是存在较重的业务负载的时候,这个值一直是接近所谓的“理想值”(99%),难道这个值真的可以去作为衡量内存瓶颈的指标吗,
实际上被这个问题困惑了好多天,
我在测试的时候,尽管不断地去压缩SqlServer的最大内存限制,
然后做压力测试,
尽管Page life expectancy可以底到十几二十几毫秒,也就是内存已经存在很严重的瓶颈了,却发现Buffer cache hit ratio这个计数器的值是99%左右,
于是开始怀疑这个计数器的算法,如果说缓冲命中率达到99%左右,能否说明没有内存瓶颈呢?
其实如果做过实际测试,应该不难发现这个问题,对于这个值,早就有人怀疑过了,明明是存在内存的瓶颈,缓存命中率却显示为99%
只是没发现有人提供满意的答案,具体问题可以参考这个 http://bbs.csdn.net/topics/330018239
下面演示一下测试步骤,测试过程可能比较粗粗略,说明其中原理即可
1,首先限制SqlServer的最大内存为1G,然后依次读取容量大于1G空间的不同的表,看看性能计数器给出的结果
 ,
,
2,创建一张测试表,往里面写入将近1G的数据量

然后再创建跟这个表一样大小的表,目前,这两个表的数据都接近于1G的空间
select * into DBTEST2.dbo.TestBufferCacheHitRatio_BAK from TestBufferCacheHitRatio
3,我们知道SqlServer读取数据的时候,粗略地讲,(如果数据不在缓存中)是现将数据读取到内存,然后再将数据返回给客户端,
测试是我在本机完成的,本机数据库服务器没有任何负载,测试的两个库也是新建的空数据库
造完测试数据之后,
测试之前我先清除所有缓存,dbcc dropcleanbuffers,
然而,由于限制了SqlServer的最大内存限制而1G,忽略SqlServer非数据缓存占用的内存空间,可以粗略地认为,
当对第一个表读取完后,这个表基本上占据满了SqlServer可用内存空间,
如果继续读取另外一张类似表的数据的时候,就要从磁盘上读取了
(实际上已经清除缓存了,主要是为了说明,第一次查询占满了内存,第二次查询必然要从磁盘读取到内存,内存中没有第二次查询的数据的缓存,即便是不清除缓存,也是一个效果),
此时观察Buffer cache hit ratio计数器的值,
理论上说,此时第二张表的数据是直接从磁盘上读取的,也就不存在所谓的缓存,缓存命中率应该是一个非常低的值,甚至是0,
如果实际来观察所谓的“缓存命中率”的值,看看是什么结果
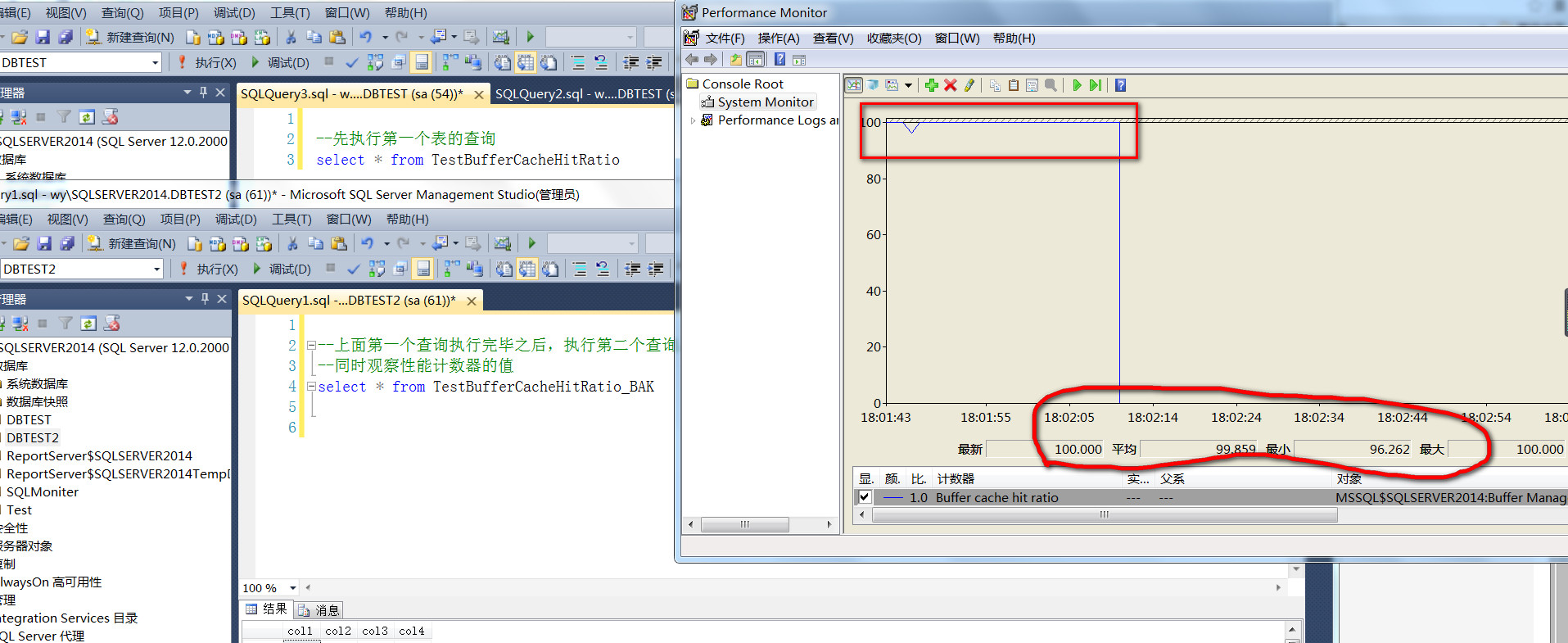
截图是第一个查询执行完成之后,执行第二个查询的时候,Buffer cache hit ratio性能计数器的情况,
第二个查询执行完成之后,我暂停了计数器监控,
这个结果应该是不受外界因素影响的(再次说明,我本机数据库没有任何负载,纯粹本机做测试的一个实例,也不用反复测试,我反复测试了N次了,下面会说明原因所在)
从截图可以看到,在第一个查询执行完成之后,
第二个查询执行的过程中,缓存命中率竟然没有明显的下降,最小值也是96%,平均值高达99%,第二个表的数据命名是从磁盘读取的,当然通过IO也可以观察出来,纯粹的预读
这不扯淡吗,测试之前清空过缓存,并且,现有内存已经被第一个查询占据满了,
明明第二张表的数据纯粹第是从硬盘空间读取的,为什么缓存命中率Buffer cache hit ratio竟然高达99%,
难怪之前我观察任何一台服务器的缓存命中率(Buffer cache hit ratio),即便是业务高峰期,都是在99%以上,原因在哪里?
何为Buffer cache hit ratio?
原来是Buffer cache hit ratio这个计数器在计算缓存命中率的时候,
把read ahead read,也即预读读取出来的数据,也算是“缓存”了,只有物理读也即physical read算作非缓存,难怪Buffer cache hit ratio总是有这个高的值
那么就来说说预读,实际上预读是什么?
预读是指在在查询执行之前,预估查询可能要用到的数据,在查询执行之前将数据读取到内存中,
所以,也不难理解,为什么没有把预读产生的数据作为缓存数据来处理。
真正在查询的时候,发现数据不在缓存中,再次去磁盘上读取数据,此时为物理读,而真正没有在“缓存”中命中的数据,就是这部分物理读,
所以缓存命中率中所谓“命中”的缓存的部分,是包含了已缓存的数据和预读的数据。
但是预读所读取出来的数据,虽然是从磁盘上读取出来的,但是在计算缓存的时候,是把这部分数据当做了缓存的
那么怎么证明呢?
可以通过652这个TRACE禁用预读(read ahead read),再同样的测试,看看现在的缓存命中率
执行DBCC TRACEON(652, -1)之后的测试截图
可以看到,本次同样的测试,第一个查询完成之后,第二查询开始,缓存命中率有一个断崖式的下跌,大多数时间是0 ,
平均值也不过是3%的样子(至于为什么存在瞬时缓存命中率的非0的高点,个人猜测是SqlServer缓存的一些进程读取到的元数据缓存)
如果观察IO的话,发现现在的第二个查询没有了预读(read ahead read),全部是物理读(physical read)
这也说明,对于Buffer cache hit ratio这个性能计数器的算法,是把预读读取出来的数据也算作是“缓存”了,如果拿这个值去判断内存瓶颈,是没有参考意义的,当然对于内存瓶颈的判断,可以用其他计数器

问题自己理解起来容易,但是是一边测试一边截图,要做到恰到好处,把问题说明清楚,表达出来真不容易。以后多写些东西锻炼,
总结:
在进行内存瓶颈判断的时候,
Buffer cache hit ratio这计数器的值,是不具备参考意义的,即便是观察到Buffer cache hit ratio命中率很高,也不一定代表服务器上没有内存瓶颈,
如果Buffer cache hit ratio命中率很低,极有可能说明存在内存瓶颈,此时还要借助于其他计数器来判断是否存在内存瓶颈,单纯一个Buffer cache hit ratio无法判断内存瓶颈。
后记,对于自己写的东西,经常是诚惶诚恐,生怕误导了别人,同时发现网上有非常多的文章,提到Buffer cache hit ratio,说的似乎是言之凿凿,具体的参考值都给到了,不知道到底有没有去手动验证一下?
最后补上用SQL查询查询缓存命中率的脚本
SELECT
CAST(CAST((a.cntr_value * 1.0 / b.cntr_value)*100 as int) AS VARCHAR(20)) as BufferCacheHitRatio
FROM (
SELECT * FROM sys.dm_os_performance_counters
WHERE counter_name = 'Buffer cache hit ratio'
AND object_name = CASE WHEN @@SERVICENAME = 'MSSQLSERVER'
THEN 'SQLServer:Buffer Manager'
ELSE 'MSSQL$' + rtrim(@@SERVICENAME) +
':Buffer Manager' END
) a
CROSS JOIN
(
SELECT * from sys.dm_os_performance_counters
WHERE counter_name = 'Buffer cache hit ratio base'
and object_name = CASE WHEN @@SERVICENAME = 'MSSQLSERVER'
THEN 'SQLServer:Buffer Manager'
ELSE 'MSSQL$' + rtrim(@@SERVICENAME) +
':Buffer Manager' END
) b
Buffer cache hit ratio性能计数器真的可以作为SQL Server 内存瓶颈的判断指标吗?的更多相关文章
- Buffer cache hit ratio性能计数器真的可以作为内存瓶颈的判断指标吗?
Buffer cache hit ratio官方是这么解释的:“指示在缓冲区高速缓存中找到而不需要从磁盘中读取的页的百分比.” Buffer cache hit ratio被很多人当做判断内存的性能指 ...
- 你真的会使用SQL Server的备份还原功能吗?之二:主要备份类型
假设在下面几个时间段中,一个数据库积累插入了如下数据: 1.完整数据库备份 故名思意,完整数据库备份包括完整的数据库信息.它包括数据库的数据文件和备份结尾的部份活动事务日志. 完整备份基本语法如下: ...
- 你真的会使用SQL Server的备份还原功能吗?之一:恢复模型
在SQL Server中,除了系统数据库外,你创建的每一个数据库都有三种可供选择的恢复模型: Simple(简单), full(完整), bulk-logged(批量日志). 下面这条语句可以显示出所 ...
- Oracle优化 -- 关于Database Buffer Cache相关参数DB_CACHE_SIZE的优化设置
select size_for_estimate, buffers_for_estimate ,ESTD_PHYSICAL_READ_factor,ESTD_PHYSICAL_READS from v ...
- Buffer cache 的调整与优化
Buffer cache 的调整与优化 -============================== -- Buffer cache 的调整与优化(一) --==================== ...
- [转载]Buffer cache的调整与优化
Buffer Cache是SGA的重要组成部分,主要用于缓存数据块,其大小也直接影响系统的性能.当Buffer Cache过小的时候,将会造成更多的free buffer waits事件.下面将具体描 ...
- buffer cache 深度解析
本文首先详细介绍了oracle中buffer cache的概念以及所包含的内存结构.然后结合各个后台进程(包括DBWRn.CKPT.LGWR等)深入介绍了oracle对于buffer cache的管理 ...
- ORACLE性能优化- Buffer cache 的调整与优化
Buffer Cache是SGA的重要组成部分,主要用于缓存数据块,其大小也直接影响系统的性能.当Buffer Cache过小的时候,将会造成更多的 free buffer waits事件. 下面将具 ...
- SQL Server性能计数器部署(批量)
一.计数器部署项目介绍 SQL Server每个服务器,日常需要监控的计数器指标高达上百,若一个个手动添加非常麻烦.此项目通过命令行工具针对指定计数器集成部署,提高部署效率.此包括开发数据库互联(OD ...
随机推荐
- Windows操作系统的版本
Windows操作系统的版本号一览 操作系统 PlatformID 主版本号 副版本号 Windows95 1 4 0 Windows98 1 4 10 WindowsMe 1 4 90 Window ...
- py库: flask笔记
http://flask.pocoo.org/ http://flask.pocoo.org/docs/0.12/api/#api API http://docs.pythontab.com/flas ...
- windows的cmd批处理命令及powershell (二)
1.变量设置 for /l %%i in (1,1,100) do @echo %%i set /a i=500set /a i=%i%+200echo %i%pause ++++++++++++++ ...
- 浅谈MyBatisGenerator的使用
目录 1.概述 2.依赖 3.Maven插件配置 4.配置文件说明 5.运行 6.总结 1.概述 日常中使用MyBatis最为麻烦的就是编写Mapper文件了, 如果数据库增加一张表, 这时通常会复制 ...
- JS 正则表达式基本语法(精粹)
1.正则表达式基本语法 两个特殊的符号'^'和'$'.他们的作用是分别指出一个字符串的开始和结束. 例子如下: "^The":表示所有以"The"开始的字符串( ...
- e1000
http://blog.csdn.net/sdulibh/article/details/41826221 http://blog.csdn.net/evenness/article/details/ ...
- 移动端过禁止输入emoji表情实现方案
最近手头上的项目有一个需求就是输入框不能输入表情,然后就各种在网上找资料,网上好多人给的方案是: str = str.replace(/\uD83C[\uDF00-\uDFFF]|\uD83D[\uD ...
- 解决Windows 10 1803 April 2018 Updatete不能网络共享的问题
Windows 10升级到1803后便不能网络共享了,现在我用的是Widnows 10 1809 Oct 2018 Update依然存在这个问题. 为了能够共享文件和文件夹需要去windows ser ...
- db2 SQL6036N解决办法
问题背景: 数据库在进行大量的运算和数据处理的过程中,IO.CPU等资源消耗非常高的时候,强制停止数据库.db2stop force 结果数据库命令迟迟没有响应.这个时候对数据库进行其他操作均无响应, ...
- [剑指Offer]36-二叉搜索树与双向链表
链接 https://www.nowcoder.com/practice/947f6eb80d944a84850b0538bf0ec3a5?tpId=13&tqId=11179&tPa ...