PCB 加投率计算实现基本原理--K最近邻算法(KNN)
PCB行业中,客户订购5000pcs,在投料时不会直接投5000pcs,因为实际在生产过程不可避免的造成PCB报废,
所以在生产前需计划多投一定比例的板板,
例:订单 量是5000pcs,加投3%,那就是总共投料要投料5000*1.03=5150pcs。
而这个多投的订单标准,每家工厂都可能不一样的,因为加投比例,需要结合订单数量,层数,铜厚,线宽,线距,
表面工艺,HDI阶数,孔径比,特殊工艺,验收标准等等 ,所以工艺难度越大,加投量也是越多。
在这里以K最近邻算法(KNN)进行加投率的模似
K最近邻 (k-Nearest Neighbors,KNN) 算法是一种分类算法,也是最简单易懂的机器学习算法,没有之一。1968年由 Cover 和 Hart 提出,应用场景有字符识别、文本分类、图像识别等领域。该算法的思想是:一个样本与数据集中的k个样本最相似,如果这k个样本中的大多数属于某一个类别,则该样本也属于这个类别。当然实际情况不可能这么简单,这里只是为了说明该算法的用法。
这里举例是对单个蚀刻工序加投率模拟,而对整个订单 的加投模拟要复杂得多
先准备下面数据集中序号A1-A12为生产型号,为已知的蚀刻工序关键对报废影响的关键参数,分为表面铜厚、线宽公差、最小线宽、最小线距4个类,
(此数据是参数对此工序的影响权重值,并非真实的值, 为了简化:报废多少量就是因该要加投多少量)
表格中最下的A13的生产型号,对应的关键参数(表面铜厚、线宽公差、最小线宽、最小线距)已有了,
但如何预测A13这款板的加投率呢。
原理:通过A13这款板的产品信息与历史生产过的产品信息,用欧式距离是一个非常简单又最常用的距离计算方法。
值越小,就是匹配度就越高, 而为了保证预测的结果准确,通过会将前几个匹配度最高的值中取出现频率最高的.

一.建立数据结构类
public class ModTechData
{
/// <summary>
/// 生产型号
/// </summary>
public string pdctno { get; set; }
/// <summary>
/// 表面铜厚
/// </summary>
public int CuThickness { get; set; }
/// <summary>
/// 线宽公差
/// </summary>
public int Tolerance { get; set; }
/// <summary>
/// 最小线宽
/// </summary>
public int Width { get; set; }
/// <summary>
/// 最小线距
/// </summary>
public int Space { get; set; }
/// <summary>
/// 报废率
/// </summary>
public double Scrap { get; set; }
/// <summary>
/// KNN距离
/// </summary>
public double KNN { get; set; }
}
二.构建数据;
List<ModTechData> TechDataList = new List<ModTechData>() {
new ModTechData(){ pdctno = "A1", CuThickness = , Tolerance = , Width = , Space = , Scrap = 0.03}
,new ModTechData(){ pdctno = "A2", CuThickness = , Tolerance = , Width = , Space = , Scrap = 0.03}
,new ModTechData(){ pdctno = "A3", CuThickness = , Tolerance = , Width = , Space = , Scrap = 0.03}
,new ModTechData(){ pdctno = "A4", CuThickness = , Tolerance = , Width = , Space = , Scrap = 0.03}
,new ModTechData(){ pdctno = "A5", CuThickness = , Tolerance = , Width = , Space = , Scrap = 0.02}
,new ModTechData(){ pdctno = "A6", CuThickness = , Tolerance = , Width = , Space = , Scrap = 0.02}
,new ModTechData(){ pdctno = "A7", CuThickness = , Tolerance = , Width = , Space = , Scrap = 0.02}
,new ModTechData(){ pdctno = "A8", CuThickness = , Tolerance = , Width = , Space = , Scrap = 0.02}
,new ModTechData(){ pdctno = "A9", CuThickness = , Tolerance = , Width = , Space = , Scrap = 0.01}
,new ModTechData(){ pdctno = "A10", CuThickness = , Tolerance = , Width = , Space = , Scrap = 0.01}
,new ModTechData(){ pdctno = "A11", CuThickness = , Tolerance = , Width = , Space = , Scrap = 0.01}
,new ModTechData(){ pdctno = "A12", CuThickness = , Tolerance = , Width = , Space = , Scrap = 0.01}
};
三.计算A13数据与数据集中所有数据的距离。
ModTechData TechData = new ModTechData() { pdctno = "A13", CuThickness = , Tolerance = , Width = , Space = };
foreach (var item in TechDataList)
{
var CuThicknessDiff = Math.Pow(TechData.CuThickness - item.CuThickness, );
var ToleranceDiff = Math.Pow(TechData.Tolerance - item.Tolerance, );
var WidthDiff = Math.Pow(TechData.Width - item.Width, );
var SpaceeDiff = Math.Pow(TechData.Space - item.Space, );
item.KNN = Math.Sqrt(CuThicknessDiff + ToleranceDiff + WidthDiff + SpaceeDiff);
}
四.按照距离大小进行递增排序,选取距离最小的k个样本
由于样本数量只有12个,取前5个匹配度最高的,如果实际应有样本量越多可以调整K值
var TechDataSortList = TechDataList.OrderBy(tt => tt.KNN).Take().ToList();

五.确定前k个样本所在类别出现的频率,取出现频率最高的类别
通过此算法,得到了A13这款板加投率匹配后频率最高加投率是0.03(3%)
var TechDataGroupList =TechDataSortList.GroupBy(tt => tt.Scrap).Select(tt => new { key = tt.Key, count = tt.Count() }).ToList();

六.真实预测加率的挑战
我们通常正常理解:比如一个产品有20个工序,将每一道工序加投率值计算出来,最终相加并得出此产品最终的加投率不就OK了吗。
但实际并不是这么简单,
1.影响工序的特征值不仅限于单工序计算加投,需综合计考虑,局部加投与综合加投,结合分析得到最终加投率
2.不仅限于当前工序的参数影响值计算加投,需考虑前工序设备参数会对后工序的影响,对历史生产的订单机器设备参数采集,覆盖越全预测才准
3.此算法是基于历史数据预测结果,样本量越大,样板特征覆盖率越全,准确率高。为了保证样本数据量在递增,每次加投或补投都需更新样板库。
4.若想预测结果准确一定要确保样本参数与结果是OK的,不然会影响加投预测的偏差。
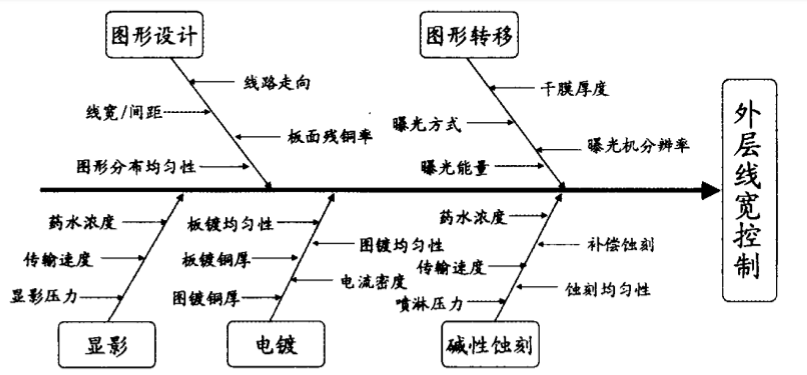
下图是外层线宽控制鱼骨图,影响线宽参数如此广泛,而想要精准预测加投率也是同样需将影响加投的因素分析出来的。
七.KNN有几个特点:
(1)KNN属于惰性学习(lazy-learning)
这是与急切学习(eager learning)相对应的,因为KNN没有显式的学习过程!也就是说没有训练阶段,从上面的例子就可以看出,数据集事先已有了分类和特征值,待收到新样本后直接进行处理。
(2)KNN的计算复杂度较高
我们从上面的例子可以看到,新样本需要与数据集中每个数据进行距离计算,计算复杂度和数据集中的数据数目n成正比,也就是说,KNN的时间复杂度为O(n),因此KNN一般适用于样本数较少的数据集。
(3)k取不同值时,分类结果可能会有显著不同。
一般k的取值不超过20,上限是n的开方
PCB 加投率计算实现基本原理--K最近邻算法(KNN)的更多相关文章
- PCB 机器学习(ML.NET)初体验实现PCB加投率预测
使用ML.NET建立PCB加投率模型对单一蚀刻工序进行加投率预测, 此实例为最简单预测,要想实现全流程加投率预测挑战难度还是挺大的,可以查看另一种关于大数据在PCB行业应用---加投率计算基本原理:P ...
- 转载: scikit-learn学习之K最近邻算法(KNN)
版权声明:<—— 本文为作者呕心沥血打造,若要转载,请注明出处@http://blog.csdn.net/gamer_gyt <—— 目录(?)[+] ================== ...
- k最近邻算法(kNN)
from numpy import * import operator from os import listdir def classify0(inX, dataSet, labels, k): d ...
- 机器学习【一】K最近邻算法
K最近邻算法 KNN 基本原理 离哪个类近,就属于该类 [例如:与下方新元素距离最近的三个点中,2个深色,所以新元素分类为深色] K的含义就是最近邻的个数.在sklearn中,KNN的K值是通过n ...
- 【算法】K最近邻算法(K-NEAREST NEIGHBOURS,KNN)
K最近邻算法(k-nearest neighbours,KNN) 算法 对一个元素进行分类 查看它k个最近的邻居 在这些邻居中,哪个种类多,这个元素有更大概率是这个种类 使用 使用KNN来做两项基本工 ...
- 图说十大数据挖掘算法(一)K最近邻算法
如果你之前没有学习过K最近邻算法,那今天几张图,让你明白什么是K最近邻算法. 先来一张图,请分辨它是什么水果 很多同学不假思索,直接回答:“菠萝”!!! 仔细看看同学们,这是菠萝么?那再看下边这这张图 ...
- 《算法图解》——第十章 K最近邻算法
第十章 K最近邻算法 1 K最近邻(k-nearest neighbours,KNN)——水果分类 2 创建推荐系统 利用相似的用户相距较近,但如何确定两位用户的相似程度呢? ①特征抽取 对水果 ...
- [笔记]《算法图解》第十章 K最近邻算法
K最近邻算法 简称KNN,计算与周边邻居的距离的算法,用于创建分类系统.机器学习等. 算法思路:首先特征化(量化) 然后在象限中选取目标点,然后通过目标点与其n个邻居的比较,得出目标的特征. 余弦相似 ...
- 机器学习-K最近邻算法
一.介绍 二.编程 练习一(K最近邻算法在单分类任务的应用): import numpy as np #导入科学计算包import matplotlib.pyplot as plt #导入画图工具fr ...
随机推荐
- Spring资源访问接口Resource
该接口拥有对不同资源类型的实现类 boolean exists() 资源是否存在 boolean isOpen() 资源是否打开 URL getURL() 如果底层资源可以表示成URL,则该方法返回对 ...
- jQuey中的return false作用是什么?
jQuey中的return false作用是什么?在众多的语句中都有return false的使用,当然对于熟悉它的开发者来说,当然是知根知底,知道此语句的作用,当然也就知道在什么时候使用此语句,不过 ...
- 洛谷——P3807 【模板】卢卡斯定理
P3807 [模板]卢卡斯定理 洛谷智推模板题,qwq,还是太弱啦,组合数基础模板题还没做过... 给定n,m,p($1\le n,m,p\le 10^5$) 求 $C_{n+m}^{m}\ mod\ ...
- Python学习笔记(3)动态类型
is运算符 ==是值相等而is必须是相同的引用才可以 l=[1,2,3] m=[1,2,3] print(l==m) # True print(l is m) # False sys模块 getref ...
- Mysql Error Code: 1175. You are using safe update mode and you tried to update a table without a WHERE that uses a KEY column To disable safe mode
今天用mysql workbench在更新数据的时候,出现了下面错误:15:52:39 update wp_posts set post_content = replace(post_conte ...
- foreach获取访问元素的下标
今天在用foreach循环的时候,要同时根据访问下标获取另一个list对象数据,之前想的方法是加一个变量i,然后每次i++,但是感觉这样不是很好!,后来发现这样也可以!举个简单的例子! foreach ...
- HDU 1059 多重背包问题
问题大意: 有价值1-6的六种物品,分别规定其数目,问是否存在一种方法能使这些物品不拆分就能平均分给两个人 #include <cstdio> #include <cstring&g ...
- HDU 1042 大数计算
这道题一开始就采用将一万个解的表打好的话,虽然时间效率比较高,但是内存占用太大,就MLE 这里写好大数后,每次输入一个n,然后再老老实实一个个求阶层就好 java代码: /** * @(#)Main. ...
- [luoguP1507] NASA的食物计划(DP)
传送门 二位费用背包 ——代码 #include <cstdio> #include <iostream> int n, maxv, maxw; ][]; inline int ...
- Codeforces Beta Round #91 (Div. 1 Only) E. Lucky Array
E. Lucky Array Petya loves lucky numbers. Everybody knows that lucky numbers are positive integers w ...