Tensorflow多线程输入数据处理框架(一)——队列与多线程
参考书
《TensorFlow:实战Google深度学习框架》(第2版)
对于队列,修改队列状态的操作主要有Enqueue、EnqueueMany和Dequeue。以下程序展示了如何使用这些函数来操作一个队列。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8 """
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: queue_operate.py
@time: 2019/1/31 21:32
@desc: 操作一个队列
""" import tensorflow as tf # 创建一个先进先出的队列,指定队列中最多可以保存两个元素,并指定类型为整数
q = tf.FIFOQueue(2, "int32")
# 使用enqueue_many函数来初始化队列中的元素。和变量初始化类似,在使用队列之前需要明确的调用这个初始化过程。
init = q.enqueue_many(([0, 10],))
# 使用Dequeue函数将队列中的第一个元素出队列。这个元素的值将被存在变量x中
x = q.dequeue()
# 将得到的值+1
y = x + 1
# 将+1后的值再重新加入队列。
q_inc = q.enqueue([y]) with tf.Session() as sess:
# 运行初始化队列的操作
init.run()
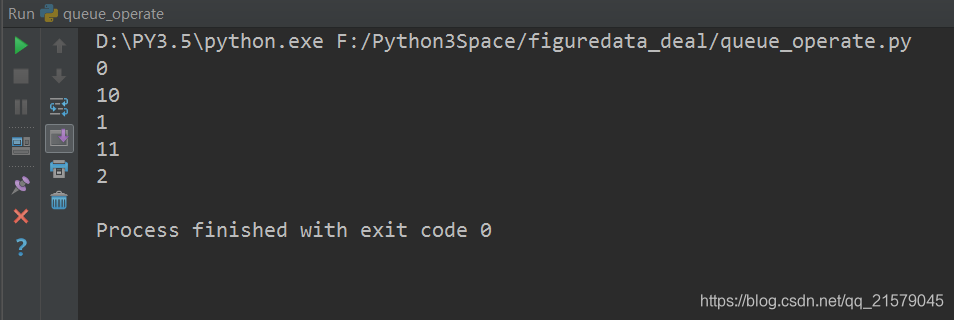
for _ in range(5):
# 运行q_inc将执行数据出队列、出队的元素+1、重新加入队列的整个过程。
v, _ = sess.run([x, q_inc])
# 打印出队元素的取值
print(v)
运行结果:

tf.Coordinator主要用于协同多个线程一起停止,以下程序展示了如何使用tf.Coordinator。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8 """
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: coordinator_test1.py
@time: 2019/2/2 21:35
@desc: tf.Coordinator主要用于协同多个线程一起停止,以下程序展示了如何使用tf.Coordinator
""" import tensorflow as tf
import numpy as np
import threading
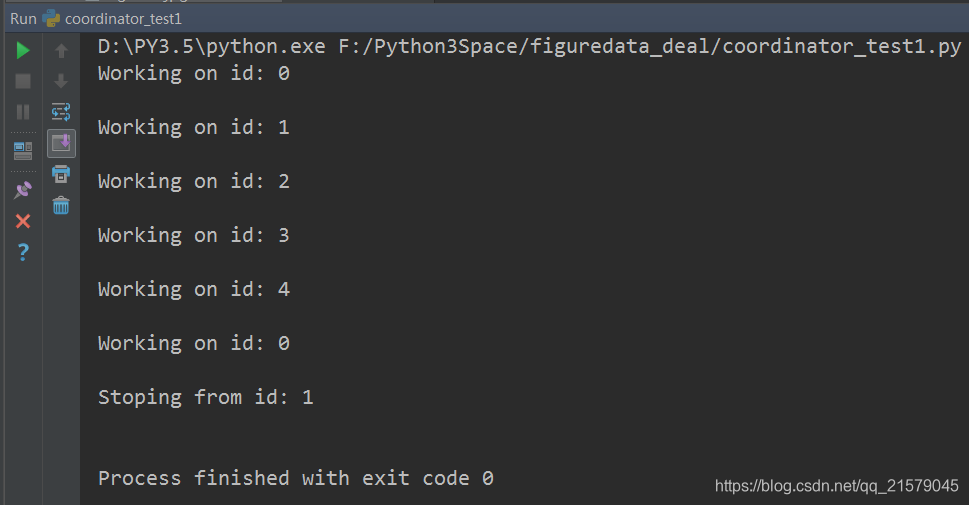
import time # 线程中运行的程序,这个程序每隔1秒判断是否需要停止并打印自己的ID。
def MyLoop(coord, worker_id):
# 使用tf.Coordinator类提供的协同工具判断当前线程是否需要停止
while not coord.should_stop():
# 随机停止所有的线程。
if np.random.rand() < 0.1:
print("Stoping from id: %d\n" % worker_id)
# 调用coord.request_stop()函数来通知其他线程停止。
coord.request_stop()
else:
# 打印当前线程的Id。
print("Working on id: %d\n" % worker_id)
# 暂停1秒
time.sleep(1) # 声明一个tf.train.Coordinator类来协同多个线程。
coord = tf.train.Coordinator()
# 声明创建5个线程。
threads = [threading.Thread(target=MyLoop, args=(coord, i, )) for i in range(5)]
# 启动所有的线程
for t in threads:
t.start()
# 等待所有线程退出
coord.join(threads)
运行结果:
如何使用tf.QueueRunner和tf.Coordinator来管理多线程队列操作。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8 """
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: queuerunner_test1.py
@time: 2019/2/3 12:31
@desc: 如何使用tf.QueueRunner和tf.Coordinator来管理多线程队列操作。
""" import tensorflow as tf # 声明一个先进先出的队列,队列中最多100个元素,类型为实数
queue = tf.FIFOQueue(100, "float")
# 定义队列的入队操作
enqueue_op = queue.enqueue([tf.random_normal([1])]) # 使用tf.train.QueueRunner来创建多个线程运行队列的入队操作。
# tf.train.QueueRunner的第一个参数给出了被操作的队列,[enqueue_op] * 5
# 表示了需要启动5个线程,每个线程中运行的是enqueue_op操作
qr = tf.train.QueueRunner(queue, [enqueue_op] * 5) # 将定义过的QueueRunner加入Tensorflow计算图上指定的集合。
# tf.train.add_queue_runner函数没有指定集合
# 则加入默认集合tf.GraphKeys.QUEUE_RUNNERS。下面的函数就是将刚刚定义的
# qr加入默认的tf.GraphKeys.QUEUE_RUNNER集合。
tf.train.add_queue_runner(qr)
# 定义出队操作
out_tensor = queue.dequeue() with tf.Session() as sess:
# 使用tf.train.Coordinator来协同启动的线程。
coord = tf.train.Coordinator()
# 使用tf.train.QueueRunner时,需要明确调用tf.train.start_queue_runners
# 来启动所有线程。否则因为没有线程运行入队操作,当调用出队操作的时候,程序会一直
# 等待入队操作被运行。tf.train.start_queue_runners函数会默认启动
# tf.GraphKeys.QUEUE_RUNNERS集合中所有的QueueRunner。因为这个函数值支持启动
# 指定集合中的QueueRunner,所以一般来说tf.train.add_queue_runner函数和
# tf.trian.start_queue_runners函数会指定同一个集合。
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
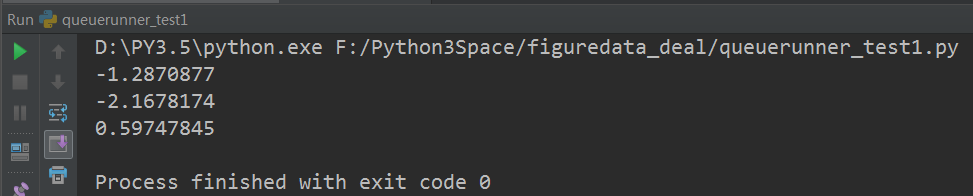
# 获取队列中的取值。
for _ in range(3):
print(sess.run(out_tensor)[0]) # 使用tf.train.Coordinator来停止所有的线程
coord.request_stop()
coord.join(threads)
运行结果:
Tensorflow多线程输入数据处理框架(一)——队列与多线程的更多相关文章
- tensorflow学习笔记——多线程输入数据处理框架
之前我们学习使用TensorFlow对图像数据进行预处理的方法.虽然使用这些图像数据预处理的方法可以减少无关因素对图像识别模型效果的影响,但这些复杂的预处理过程也会减慢整个训练过程.为了避免图像预处理 ...
- TensorFlow多线程输入数据处理框架(四)——输入数据处理框架
参考书 <TensorFlow:实战Google深度学习框架>(第2版) 输入数据处理的整个流程. #!/usr/bin/env python # -*- coding: UTF-8 -* ...
- Tensorflow多线程输入数据处理框架
Tensorflow提供了一系列的对图像进行预处理的方法,但是复杂的预处理过程会减慢整个训练过程,所以,为了避免图像的预处理成为训练神经网络效率的瓶颈,Tensorflow提供了多线程处理输入数据的框 ...
- TensorFlow多线程输入数据处理框架(二)——输入文件队列
参考书 <TensorFlow:实战Google深度学习框架>(第2版) 一个简单的程序来生成样例数据. #!/usr/bin/env python # -*- coding: UTF-8 ...
- TensorFlow多线程输入数据处理框架(三)——组合训练数据
参考书 <TensorFlow:实战Google深度学习框架>(第2版) 通过TensorFlow提供的tf.train.batch和tf.train.shuffle_batch函数来将单 ...
- 吴裕雄 python 神经网络——TensorFlow 输入数据处理框架
import tensorflow as tf files = tf.train.match_filenames_once("E:\\MNIST_data\\output.tfrecords ...
- 吴裕雄--天生自然 pythonTensorFlow图形数据处理:输入数据处理框架
import tensorflow as tf # 1. 创建文件列表,通过文件列表创建输入文件队列 files = tf.train.match_filenames_once("F:\\o ...
- TensorFlow+实战Google深度学习框架学习笔记(7)-----队列与多线程
一.创建一个队列: FIFOQueue:先进先出 RandomShuffleQueue:会将队列中的元素打乱,每次出列操作得到的是从当前队列所有元素中随机选择的一个. 二.操作一个队列的函数: enq ...
- 『TensorFlow』第十一弹_队列&多线程&TFRecod文件_我辈当高歌
TF数据读取队列机制详解 一.TFR文件多线程队列读写操作 TFRecod文件写入操作 import tensorflow as tf def _int64_feature(value): # val ...
随机推荐
- 一个TAB的jquery简单写法2
<style> .honver{ color:red;} </style><script src="jquery-1.9.0.min.js">& ...
- 【转载】究竟啥才是互联网架构“高可用”
一.什么是高可用 高可用HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间. 假设系统一直能够提供服务,我们说系统的可用 ...
- navicat-premium11.1.6 x64关键
Navicat Premium version patch 11.2.16.0 >navicat.exe0000000001CECCBC:80->C60000000001CECCBD: ...
- jquery事件手冊
方法 描写叙述 bind() 向匹配元素附加一个或很多其它事件处理器 blur() 触发.或将函数绑定到指定元素的 blur 事件 change() 触发.或将函数绑定到指定元素的 change 事件 ...
- eclipse debug configurations arguments指定文件路径参数
1 eclipse debug configurations arguments指定文件路径参数 使用绝对路径,但是这个文件必须要放在该project的源码路径的外面才行,否则eclipse不认这个文 ...
- Oracle Exception
Oracle存储过程的异常处理 1.为了提高存储过程的健壮性,避免运行错误,当建立存储过程时应包含异常处理部分.2.异常(EXCEPTION)是一种PL/SQL标识符,包括预定义异常.非预定义异常和自 ...
- acd - 1427 - Nice Sequence(线段树)
题意:一个由n个数组成的序列(序列元素的范围是[0, n]).求最长前缀 j .使得在这个前缀 j 中对于随意的数 i1 < i2.都满足随意的 m <= j.i1 在前 m 个数里出现的 ...
- 利用CoreTelephony获取用户当前网络状态(判断2G,3G,4G)
前言: 在项目开发当中,往往需要利用网络.而用户的网络环境也需要我们开发者去注意,根据不同的网络状态作相应的优化,以提升用户体验. 但通常我们只会判断用户是在WIFI还是移动数据,而实际上,移动数据也 ...
- Hive 特性及原理
特点:Hive是构建在hadoop之上的数据仓库.数据存储在hdfs上,数据计算用的mapreduce框架.用户无需掌握MR的编写,通过类SQL语句即可自动生成查询计划. 主要内容: 接入入口 ...
- NOSQL安全攻击
摘自:http://www.infoq.com/cn/articles/nosql-injections-analysis JSON查询以及数据格式 PHP编码数组为原生JSON.嗯,数组示例如下: ...