spark on yarn模式下内存资源管理(笔记1)
问题:
1. spark中yarn集群资源管理器,container资源容器与集群各节点node,spark应用(application),spark作业(job),阶段(stage),任务(task)之间的关系。
2. 在yarn集群资源管理器下,提交一个spark应用之后,经过怎样的资源分配,最后为每个节点每个task分配具体内存资源,让其执行具体计算任务。需要详细分析其中的过程。
1)资源管理器怎么合理分配分布式集群内存资源,各个节点又是如何具体为task分配内存。***
2)当集群各节点内存资源存在差异时,又是如何处理的?
3. 在分析集群到各节点,怎么具体为task分配内存后,再去梳理分区数与task可用内存,对task运行效率的影响。
1) 可以确定的是,一个task执行一个分区内存的数据的计算任务;而一个executor中所有tasks共享一个内存池的资源。
2) 那么,这个内存池是否是一个节点的可用内存总和,与Container资源容器是否是一一对应的。
针对这些问题,通过阅读论文做的笔记。
一、 yarn集群资源管理器
1. 分析spark资源管理器与工作节点,job,stage,task之间的关系
Spark运行架构包括集群资源管理器(Cluster Manager)、运行作业任务的工作节点(Worker Node)、每个应用的任务控制节点(Driver)和每个工作节点上负责具体任务的执行进程(Executor)。其中,集群资源管理器可以是Spark自带的资源管理器,也可以是YARN或Mesos等资源管理框架。因为师姐实验中都是在选择yarn,所以只关心yarn资源管理器的工作原理。
可以看出,一个工作节点可以启动一个或者多个进程(Executor),但是实际上只提交一个spark应用程序,应该是只启动了一个进程。(待确定)
同时,一个executor进程可以运行多个task任务,那么一个task可以看成是一个线程,一个节点可以同时运行的task数目应该是对应CPU core数目。
2. 一个Spark应用提交,经过集群资源管理器,到task任务执行的过程
一个应用(Application)由一个任务控制节点(Driver)和若干个作业(Job)构成,一个作业(job)由多个阶段(Stage)构成,一个阶段由多个任务(Task)组成。当执行一个应用时,任务控制节点会向集群管理器(Cluster Manager)申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行任务(task),运行结束后,执行结果会返回给任务控制节点,或者写到HDFS或者其他数据库中。
任务(task)的封装和分配,具体是由DAGScheduler将job划分为stage,stage基于taskscheduler划分为一批tasks。
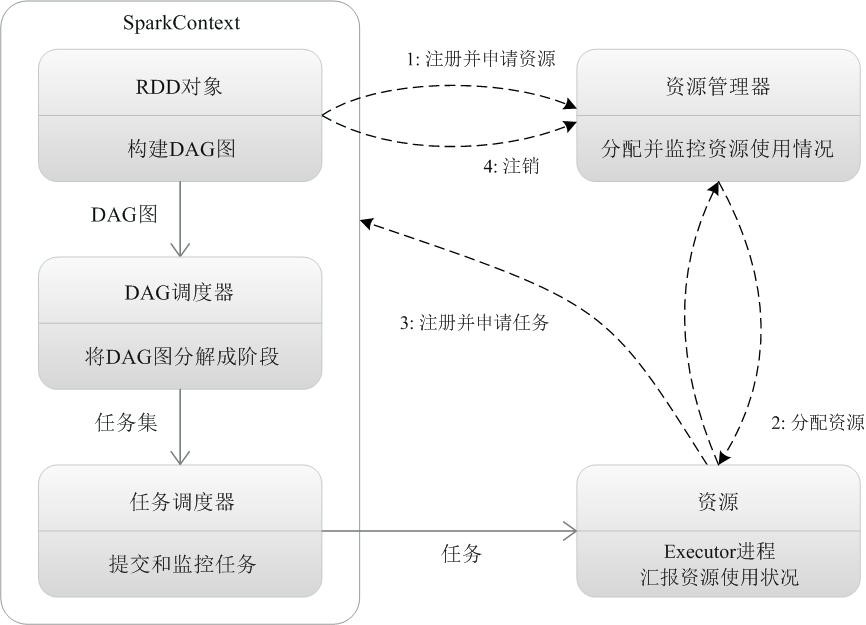
由原理图和spark基本运行机制可以确定的是,集群资源管理器是基于Executor进程这个整体来进行资源分配的。
那么,yarn资源管理器在spark应用提交后,具体做了怎样的集群资源管理分配?
3. yarn资源分配机制
由spark运行架构可知,集群控制节点负责与工作节点通信和分配计算任务,工作节点负责执行具体计算任务,而集群资源管理器专用于为每个节点的executor进程分配CPU和内存资源。
1)而实际上,Container(容器)是yarn资源分配的基本单位,并且只对CPU和内存这两种资源进行管理。
2)yarn是基于粗粒度的,一旦作业提交,为该作业分配了相应的容器资源(CPU和内存),在作业生命周期内,容器资源大小不再改变,即多了也不会释放,少了也不会再增加。
3)yarn的实现主要有3部分:ResourceManager(RM),NodeManager(NM),ApplicationMaster(AM)。RM是全局的资源管理器,负责整个系统的资源管理和分配,它是yarn框架的核心模块,主要由调度器和应用管理器组成;NM是每个节点上的资源和任务管理器,一方面它会定时向RM汇报本节点的资源使用情况和各个Container的运行状态,另一方面,它会接收并处理来自AM的任务启动/停止等各种请求。用户提交的每一个应用程序均包含一个AM,作用是:与RM调度器协商以获取资源、与NM通信以启动/停止任务、监控所有任务的运行状态,并在任务运行失败时重新申请资源以重启任务。

4. spark executor/task与yarn container的关系
1)每个节点(机器)可以分配几个Container?
计算每台机子最多可以拥有多少个container,可以使用下面的公式:
containers = min (2*CORES, 1.8*DISKS, (Total available RAM) / MIN_CONTAINER_SIZE)
说明:
• CORES为机器CPU核数
• DISKS为机器上挂载的磁盘个数
• Total available RAM为机器总内存
• MIN_CONTAINER_SIZE是指container最小的容量大小,这需要根据具体情况去设置,可以参考下面的表格
2)每个Container可分配多少内存?节点之间内存资源存在差异怎么办?
而实际spark应用程序运行时,Container容器的准确内存大小是3个因素决定:
运行参数Executor.memory;
堆外内存memoryOverhead;
调度时一个container能够申请的最小资源。
• spark.yarn.executor.memoryOverhead:堆外内存,值为executorMemory * 0.07, with minimum of 384
• yarn.scheduler.minimum-allocation-mb:调度时一个container能够申请的最小资源
• container内存大小计算规则是:
每一个Container的大小必须为yarn.scheduler.minimum-allocation-mb值的整数倍,当executor-memory=3g时,executorMemory + memoryOverhead为3G+384M=3456M,需要申请的Container大小为yarn.scheduler.minimum-allocation-mb * 2 =4096m=4G,其他依此类推。
可以得到一些重要的结论:即使集群节点资源存在差异,yarn分配资源的方式是根据用户设置的运行参数和机器基本资源大小进行分配的,不会根据运行中任务变化而变化。即:一旦spark作业提交,容器资源分配后,直到作业运行结束都不会再改变容器的总体内存大小。所以如果要在yarn模式下进行资源的动态调整,只有2种方法:
1) 在作业提交之前,容器资源还未申请的时候,进行容器资源调度的注入;
2) 在作业提交后,就只能在容器内存大小的上下限范围内,对task的内存进行动态调整。
3)每个Container可以包含多少executor?
由前面的分析可知,每个节点可以有多个Container,每个容器的平均内存大小也可大致计算出来。图中说明Yarn中的Container与spark的executor是一对一的关系。(但也有博客指出一个容器可以存在多个executor)
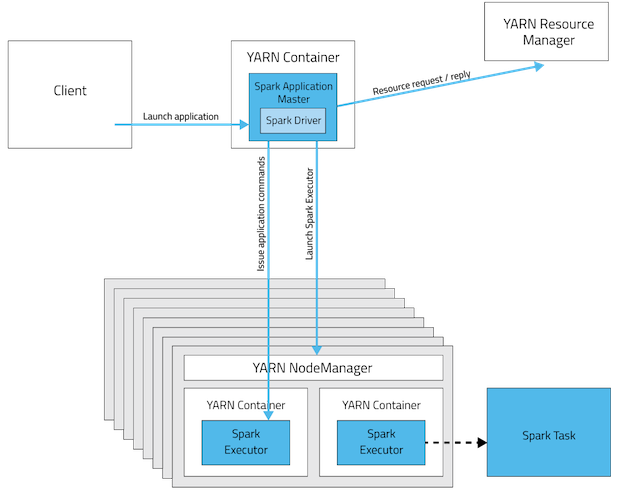
4)每个Container中的task又是如何分配内存的?
如果说,容器与executor的对应关系可以是一对多的,executor也可以有一个或者多个task,那么可以确定的是,同一个executor进程中的tasks是并行的,且共享一个内存池中的资源。根据前面的学习,executor对应的内存池是基于公平原则为每个task分配内存。
二、 分区数与内存对task运行效率的影响
在spark中,一个spark应用提交后,由action触发作业提交,生成DAG图,作业(job)划分为子阶段(stage),而每个stage又划分为一批任务(task),同一个stage内的tasks是并行的。当根据宽依赖划分stage时,都会对RDD进行重新分区(partiton),每个task对应计算一个partition的数据。
而stage之间是串行的,所以job执行总时间=作业启动时间+(stage1+stage2…)运行时间+作业结束时间(释放资源)。
1)分区数、内存对task运行效率的影响分析
如果同一个stage中的分区数配置合适,同一数据集在每一分区内存数据更均匀(降低了数据倾斜程度),就可以提高任务的并行度,减少一个stage占用的时间,从而减少总体运行时间。
更要说明的是:通常task过多也会导致内存不足,因为相同内存资源大小下,task过多就会将内存资源均分的过小,那么一个任务申请不到计算所需的内存就会执行失败。
由前面分析可知,在spark作业运行阶段,每个Container内存大小是固定不变的,而运行在Container中的所有task共享内存池资源,通过分区数的动态调整可以降低数据的倾斜度;但降低倾斜度不代表所有分区数据将会是均匀的,所以公平内存分配就存在一定的不合理,而如果能根据具体的task负载大小,为每个task申请最佳的内存大小,那么就从另一个角度提高task运行效率。
补充:以上说明了合适的分区数、合适的内存确实可以提高task的效率,但是未考虑到:为task计算出合适的内存大小这个过程所需的时间和空间,在此花费的与提高的性能相比是否值得。
三、 实验部分
问题:什么样的指标数据是好的?收集哪些指标?
在相同数据集,同一算子下,主要从资源利用率和算子运行时间两个方面考虑指标是不是最佳的。
1. 写了一个collect_parameter类
每次spark应用运行,从控制台输入配置参数,在运行spark应用运行的时候采集运行时的各项参数,并且运行完成就写入外部txt文件。
txt格式:每项参数,用“,”隔开。
(因为机器学习算法训练过程会自己学习各项参数的权重,数据集不需要自己标注每项参数的,所以我就先用最简单的格式采集性能数据 )这样每运行一次,就收集到该应用的一组运行参数。
参数包括:配置参数和运行时间(待完善)
1)选取的计算任务:词频统计wordcount
2)本来想实现,通过循环,多次运行同一个数据集下同一计算任务,每次循环自动调整参数,这样就可以不用手工输入就能进行多次实验了。
出现的问题:SparkException: Only one SparkContext may be running in this JVM
原因:每次运行都会在jvm中产生一个sparkContext对象,而jvm只能存在一个sparkContext对象。
解决办法:可以将spark.driver.allowMultipleContexts设置为true,但是实验数量通常很大,多次运行产生多个sparkContext对象肯定会导致内存溢出。所以综合考虑,还是需要手工输入参数运行。
参数:
spark.driver.memory :默认值512m
spark.executor.memory :默认值512m
spark.yarn.am.memory :默认值512m
spark.yarn.executor.memoryOverhead :值为 executorMemory * 0.07, with minimum of 384
spark.yarn.driver.memoryOverhead :值为 driverMemory * 0.07, with minimum of 384
spark.yarn.am.memoryOverhead :值为 AM memory * 0.07, with minimum of 384
yarn.app.mapreduce.am.resource.mb :AM能够申请的最大内存,默认值为1536MB
yarn.nodemanager.resource.memory-mb :nodemanager能够申请的最大内存,默认值为8192MB
yarn.scheduler.minimum-allocation-mb :调度时一个container能够申请的最小资源,默认值为1024MB
yarn.scheduler.maximum-allocation-mb :调度时一个container能够申请的最大资源,默认值为8192MB
spark.default.parallelism:(默认的分区数)= 2
2. 实验设计分析
首先要做好实验的设计,才能确保大量的对比实验,提取出的最佳性能指标是有效的。
性能指标的收集需要进行实验和验证:首先需要验证这些指标确实影响了spark性能,然后再通过大量对比实验收集完整的实验数据,进而再从中提取出各个数据集规模下的最佳指标集。这里通过学习论文:基于细粒度监控的spark优化研究,有了一些收获。
第一部分,影响spark性能指标的验证
从理论上,前面已经分析了几个方面:
运行参数和设备参数对task实际可用内存大小的影响。(预测task内存)
分区数,任务内存及其他运行参数对spark运行性能的影响。(优化task效率)
第二部分,大量对比实验
实验需要达到的目标:
1) 收集运行指标数据,作为机器学习的训练库
2) 同一算子,在各个数据集规模下,提取性能最佳的数据
3) 验证第一部分,说明这些参数确实影响了spark性能
实验设计
(参考论文中不同spark负载下的对比实验)
1) 算子选择:reduceByKey,GroupByKey
2) 数据集规模:1G-20G
3) 数据集来源:
可以自己写代码,按照不同比例生成倾斜度大的数据集(保证包含倾斜程度不同的数据);
随机的数据集可以从google+网站下载,然后自己写代码将其分割为大小规模不同的数据集。
4) 运行参数的选择:运行参数极多,只考虑与分区数、task内存有关的,其他的参数确保相对不变就可以。(相对不变:在一个数据集规模范围内保持不变)
5) 最佳指标的评判:主要从资源利用率和算子运行时间两个方面考虑。
spark on yarn模式下内存资源管理(笔记1)的更多相关文章
- spark on yarn模式下内存资源管理(笔记2)
1.spark 2.2内存占用计算公式 https://blog.csdn.net/lingbo229/article/details/80914283 2.spark on yarn内存分配** 本 ...
- spark on yarn模式下配置spark-sql访问hive元数据
spark on yarn模式下配置spark-sql访问hive元数据 目的:在spark on yarn模式下,执行spark-sql访问hive的元数据.并对比一下spark-sql 和hive ...
- spark 在yarn模式下提交作业
1.spark在yarn模式下提交作业需要启动hdfs集群和yarn,具体操作参照:hadoop 完全分布式集群搭建 2.spark需要配置yarn和hadoop的参数目录 将spark/conf/目 ...
- spark on yarn模式里需要有时手工释放linux内存
为什么要提出这个问题? spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED) 然后执行 [spark@master spark--bin- ...
- Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz + hadoop-2.6.0.tar.gz)(master、slave1和slave2)(博主推荐)
说白了 Spark on YARN模式的安装,它是非常的简单,只需要下载编译好Spark安装包,在一台带有Hadoop YARN客户端的的机器上运行即可. Spark on YARN简介与运行wor ...
- spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED)
不多说,直接上干货! 问题详情 电脑8G,目前搭建3节点的spark集群,采用YARN模式. master分配2G,slave1分配1G,slave2分配1G.(在安装虚拟机时) export SPA ...
- flink on yarn模式下两种提交job方式
yarn集群搭建,参见hadoop 完全分布式集群搭建 通过yarn进行资源管理,flink的任务直接提交到hadoop集群 1.hadoop集群启动,yarn需要运行起来.确保配置HADOOP_HO ...
- spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED)(转)
不多说,直接上干货! 问题详情 电脑8G,目前搭建3节点的spark集群,采用YARN模式. master分配2G,slave1分配1G,slave2分配1G.(在安装虚拟机时) export SPA ...
- Spark- Spark Yarn模式下跑yarn-client无法初始化SparkConext,Over usage of virtual memory
在spark yarn模式下跑yarn-client时出现无法初始化SparkContext错误. // :: INFO mapreduce.Job: Task Id : attempt_142829 ...
随机推荐
- 64位windows上访问64位oracle 12c
64位windows上访问64位oracle 12c,这会有啥问题? 没啥问题.问题是,我64位操作系统的机器上装了个oracle 10g.而oracle 10g好像是不区分啥32位.64位的,一律3 ...
- (续)linux SD卡初始化---mmc_sd_init_card函数
mmc_sd_init_card剩下的关于UHS-I的分支结构. uhs-I的初始化流程图如图: 红线标出的部分是已经做了的事,与上一篇那个流程图是一致的,之后就是if分支中做的事. if分支中的函数 ...
- 关于数论【polya计数法】
可以预见数论推公式是有多么蛋疼. 让我简明扼要的讲讲吧(多都说不出来,毕竟才做了两道题)其实呢,这个算法应该归入群论,有个有用的东西:置换群,它表示一个集合包括很多的置换.先讲讲置换吧:↓(这是个置换 ...
- jfreechart应用3--饼状图 学习(作者:百度 被风吹过的日子)
jfreechart应用3--饼状图 三. 饼图 在WebRoot目录下建立名为pie的子目录,用来存放本教程中饼图的实例jsp页面.下面让我们来看一个简单的三维饼图.首先在pie目录下建立一个名为s ...
- JS窗口
<SCRIPT LANGUAGE="javascript"> <!-- window.open ('page.html', 'newwindow', 'heigh ...
- 【Selenium】软件测试基础(软件测试分类和工具组)firebug、firepath的安装
白盒测试:需要了解内部结构和代码 黑盒测试:不关心内部结构和代码 灰盒测试:介于白盒黑盒之间 静态测试:测试时不执行被测试软件 动态测试:测试时执行被测试软件 单元测试:测试软件的单元模块 集成测试: ...
- android ndk环境搭建,如果是mac,请先装mac make编译器(可以使用Xcode进行安装)
Android SDK:android-sdk-mac_86Android NDK: android-ndk-r4b-darwin-x86EclipseADTCDTANT搭建Android SDK开发 ...
- AOP 基本术语及其在 Spring 中的实现
无论是 Spring 还是其他支持 AOP(Aspect Oriented Programming)的框架,尤其是 Spring 这种基于 Java(彻底的面向对象)的语言,在实现 AOP 时,首先为 ...
- Maven的-pl -am -amd参数学习
昨天maven的deploy任务需要只选择单个模块并且把它依赖的模块一起打包,第一时间便想到了-pl参数,然后就开始处理,但是因为之前只看了一下命令的介绍,竟然花了近半小时才完全跑通,故记录此文. 假 ...
- python3.6 + selenium2.53.1 查询数据库并将返回的内容中每一行的内容转换成class对象
环境: win10 python3.6 selenium2.53.1 准备工作:先安装pymysql python2.x链接数据库使用MySQLdb,而python3.x链接数据库使用pymysql ...