Hadoop架构设计、执行原理具体解释
1、Map-Reduce的逻辑过程
如果我们须要处理一批有关天气的数据。其格式例如以下:
- 依照ASCII码存储。每行一条记录
- 每一行字符从0開始计数,第15个到第18个字符为年
- 第25个到第29个字符为温度。当中第25位是符号+/-
|
0067011990999991950051507+0000+ 0043011990999991950051512+0022+ 0043011990999991950051518-0011+ 0043012650999991949032412+0111+ 0043012650999991949032418+0078+ 0067011990999991937051507+0001+ 0043011990999991937051512-0002+ 0043011990999991945051518+0001+ 0043012650999991945032412+0002+ 0043012650999991945032418+0078+ |
如今须要统计出每年的最高温度。
Map-Reduce主要包含两个步骤:Map和Reduce
每一步都有key-value对作为输入和输出:
- map阶段的key-value对的格式是由输入的格式所决定的。假设是默认的TextInputFormat。则每行作为一个记录进程处理。当中key为此行的开头相对于文件的起始位置。value就是此行的字符文本
- map阶段的输出的key-value对的格式必须同reduce阶段的输入key-value对的格式相相应
对于上面的样例,在map过程,输入的key-value对例如以下:
|
(0,0067011990999991950051507+0000+) (33,0043011990999991950051512+0022+) (66,0043011990999991950051518-0011+) (99,0043012650999991949032412+0111+) (132,0043012650999991949032418+0078+) (165,0067011990999991937051507+0001+) (198,0043011990999991937051512-0002+) (231,0043011990999991945051518+0001+) (264,0043012650999991945032412+0002+) (297,0043012650999991945032418+0078+) |
在map过程中。通过对每一行字符串的解析,得到年-温度的key-value对作为输出:
|
(1950, 0) (1950, 22) (1950, -11) (1949, 111) (1949, 78) (1937, 1) (1937, -2) (1945, 1) (1945, 2) (1945, 78) |
在reduce过程。将map过程中的输出。依照同样的key将value放到同一个列表中作为reduce的输入
|
(1950, [0, 22, –11]) (1949, [111, 78]) (1937, [1, -2]) (1945, [1, 2, 78]) |
在reduce过程中,在列表中选择出最大的温度,将年-最大温度的key-value作为输出:
|
(1950, 22) (1949, 111) (1937, 1) (1945, 78) |
其逻辑过程可用例如以下图表示:
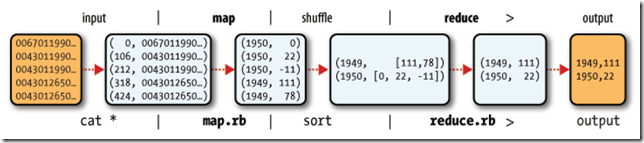
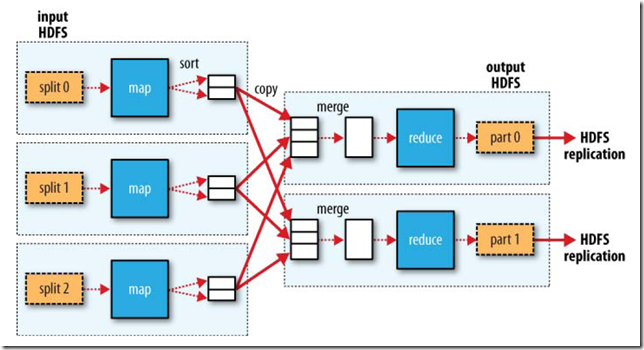
下图大概描写叙述了Map-Reduce的Job执行的基本原理:
以下我们讨论JobConf。其有非常多的项能够进行配置:
- setInputFormat:设置map的输入格式。默觉得TextInputFormat,key为LongWritable,value为Text
- setNumMapTasks:设置map任务的个数。此设置通常不起作用,map任务的个数取决于输入的数据所能分成的inputsplit的个数
- setMapperClass:设置Mapper。默觉得IdentityMapper
- setMapRunnerClass:设置MapRunner, maptask是由MapRunner执行的。默觉得MapRunnable,其功能为读取inputsplit的一个个record,依次调用Mapper的map函数
- setMapOutputKeyClass和setMapOutputValueClass:设置Mapper的输出的key-value对的格式
- setOutputKeyClass和setOutputValueClass:设置Reducer的输出的key-value对的格式
- setPartitionerClass和setNumReduceTasks:设置Partitioner。默觉得HashPartitioner,其依据key的hash值来决定进入哪个partition,每一个partition被一个reduce task处理,所以partition的个数等于reducetask的个数
- setReducerClass:设置Reducer,默觉得IdentityReducer
- setOutputFormat:设置任务的输出格式,默觉得TextOutputFormat
- FileInputFormat.addInputPath:设置输入文件的路径,能够使一个文件,一个路径,一个通配符。能够被调用多次加入多个路径
- FileOutputFormat.setOutputPath:设置输出文件的路径,在job执行前此路径不应该存在
当然不用全部的都设置。由上面的样例。能够编写Map-Reduce程序例如以下:
|
public class MaxTemperature { publicstatic void main(String[] args) throws IOException { if (args.length != 2) { System.err.println("Usage: MaxTemperature <inputpath> <outputpath>"); System.exit(-1); } JobConf conf = new JobConf(MaxTemperature.class); conf.setJobName("Max temperature"); FileInputFormat.addInputPath(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1])); conf.setMapperClass(MaxTemperatureMapper.class); conf.setReducerClass(MaxTemperatureReducer.class); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); JobClient.runJob(conf); } } |
3、Map-Reduce数据流(data flow)
Map-Reduce的处理过程主要涉及下面四个部分:
- clientClient:用于提交Map-reduce任务job
- JobTracker:协调整个job的执行。其为一个Java进程,其main class为JobTracker
- TaskTracker:执行此job的task,处理input split,其为一个Java进程,其mainclass为TaskTracker
- HDFS:hadoop分布式文件系统,用于在各个进程间共享Job相关的文件

3.1、任务提交
JobClient.runJob()创建一个新的JobClient实例,调用其submitJob()函数。
- 向JobTracker请求一个新的job ID
- 检測此job的output配置
- 计算此job的input splits
- 将Job执行所需的资源复制到JobTracker的文件系统中的目录中,包含jobjar文件。job.xml配置文件,input splits
- 通知JobTracker此Job已经能够执行了
提交任务后,runJob每隔一秒钟轮询一次job的进度,将进度返回到命令行,直到任务执行完成。
3.2、任务初始化
当JobTracker收到submitJob调用的时候,将此任务放到一个队列中,job调度器将从队列中获取任务并初始化任务。
初始化首先创建一个对象来封装job执行的tasks, status以及progress。
在创建task之前,job调度器首先从共享文件系统中获得JobClient计算出的input splits。
其为每一个input split创建一个map task。
每一个task被分配一个ID。
3.3、任务分配
TaskTracker周期性的向JobTracker发送heartbeat。
在heartbeat中。TaskTracker告知JobTracker其已经准备执行一个新的task。JobTracker将分配给其一个task。
在JobTracker为TaskTracker选择一个task之前。JobTracker必须首先依照优先级选择一个Job,在最高优先级的Job中选择一个task。
TaskTracker有固定数量的位置来执行map task或者reduce task。
默认的调度器对待map task优先于reduce task
当选择reduce task的时候。JobTracker并不在多个task之间进行选择,而是直接取下一个,由于reducetask没有数据本地化的概念。
3.4、任务运行
TaskTracker被分配了一个task,以下便要执行此task。
首先。TaskTracker将此job的jar从共享文件系统中复制到TaskTracker的文件系统中。
TaskTracker从distributed cache中将job执行所须要的文件复制到本地磁盘。
其次,其为每一个task创建一个本地的工作文件夹。将jar解压缩到文件文件夹中。
其三,其创建一个TaskRunner来执行task。
TaskRunner创建一个新的JVM来执行task。
被创建的child JVM和TaskTracker通信来报告执行进度。
3.4.1、Map的过程
MapRunnable从inputsplit中读取一个个的record,然后依次调用Mapper的map函数,将结果输出。
map的输出并非直接写入硬盘,而是将其写入缓存memory buffer。
当buffer中数据的到达一定的大小。一个背景线程将数据開始写入硬盘。
在写入硬盘之前,内存中的数据通过partitioner分成多个partition。
在同一个partition中,背景线程会将数据依照key在内存中排序。
每次从内存向硬盘flush数据。都生成一个新的spill文件。
当此task结束之前。全部的spill文件被合并为一个整的被partition的并且排好序的文件。
reducer能够通过http协议请求map的输出文件,tracker.http.threads能够设置http服务线程数。
3.4.2、Reduce的过程
当map task结束后。其通知TaskTracker。TaskTracker通知JobTracker。
对于一个job,JobTracker知道TaskTracer和map输出的相应关系。
reducer中一个线程周期性的向JobTracker请求map输出的位置,直到其取得了全部的map输出。
reduce task须要其相应的partition的全部的map输出。
reduce task中的copy过程即当每一个map task结束的时候就開始拷贝输出。由于不同的maptask完毕时间不同。
reduce task中有多个copy线程,能够并行拷贝map输出。
当非常多map输出复制到reduce task后。一个背景线程将其合并为一个大的排好序的文件。
当全部的map输出都复制到reduce task后,进入sort过程,将全部的map输出合并为大的排好序的文件。
最后进入reduce过程,调用reducer的reduce函数,处理排好序的输出的每一个key。最后的结果写入HDFS。

3.5、任务结束
当JobTracker获得最后一个task的执行成功的报告后,将job得状态改为成功。
当JobClient从JobTracker轮询的时候。发现此job已经成功结束,则向用户打印消息,从runJob函数中返回。
如有不懂,欢迎拨打10010或10086。转何哲江。
Hadoop架构设计、执行原理具体解释的更多相关文章
- dubbo源码解析五 --- 集群容错架构设计与原理分析
欢迎来我的 Star Followers 后期后继续更新Dubbo别的文章 Dubbo 源码分析系列之一环境搭建 博客园 Dubbo 入门之二 --- 项目结构解析 博客园 Dubbo 源码分析系列之 ...
- 2、Hdfs架构设计与原理分析
文章目录 1.Hadoop架构 2.HDFS体系架构 2.1NameNode 2.1.1元数据信息 2.1.2NameNode文件操作 2.1.3NameNode副本 2.1.4NameNode心跳机 ...
- Dubbo架构设计及原理详解
Dubbo是Alibaba开源的分布式服务框架,它最大的特点是按照分层的方式来架构,使用这种方式可以使各个层之间解耦合(或者最大限度地松耦合).从服务模型的角度来看,Dubbo采用的是一种非常简单的模 ...
- Tomcat 架构原理解析到架构设计借鉴
Tomcat 发展这么多年,已经比较成熟稳定.在如今『追新求快』的时代,Tomcat 作为 Java Web 开发必备的工具似乎变成了『熟悉的陌生人』,难道说如今就没有必要深入学习它了么?学习它我们又 ...
- Web信息架构——设计大型网站(第3版)(久负盛名经典再现,信息架构设计领域基石之作!)
Web信息架构——设计大型网站(第3版)(久负盛名经典再现,信息架构设计领域基石之作!) [美]]Peter Morville(彼得·莫维尔) Louis Rosenfeld(路易斯·罗森菲尔德) ...
- 2本Hadoop技术内幕电子书百度网盘下载:深入理解MapReduce架构设计与实现原理、深入解析Hadoop Common和HDFS架构设计与实现原理
这是我收集的两本关于Hadoop的书,高清PDF版,在此和大家分享: 1.<Hadoop技术内幕:深入理解MapReduce架构设计与实现原理>董西成 著 机械工业出版社2013年5月出 ...
- Hadoop YARN架构设计要点
YARN是开源项目Hadoop的一个资源管理系统,最初设计是为了解决Hadoop中MapReduce计算框架中的资源管理问题,但是现在它已经是一个更加通用的资源管理系统,可以把MapReduce计算框 ...
- 从微信小程序开发者工具源码看实现原理(一)- - 小程序架构设计
使用微信小程序开发已经很长时间了,对小程序开发已经相当熟练了:但是作为一名对技术有追求的前端开发,仅仅熟练掌握小程序的开发感觉还是不够的,我们应该更进一步的去理解其背后实现的原理以及对应的考量,这可能 ...
- 架构设计:负载均衡层设计方案(4)——LVS原理
之前我们花了两篇文章的篇幅,详细讲解了Nginx的原理.安装和特性组件.请参看<负载均衡层设计方案(2)——Nginx安装>(http://blog.csdn.net/yinwenjie/ ...
随机推荐
- 微信小程序---协同工作和发布
(1)协同开发和发布 在中大型的公司里,人员的分工非常仔细,一般会有不同岗位角色的员工同时参与同一个小程序项目.为此,小程序平台设计了不同的权限管理使得项目管理者可以更加高效管理整个团队的协同工作. ...
- Android开发中JavaBean类和序列化知识的理解
原创文章,转载请注明出处:http://www.cnblogs.com/baipengzhan/p/6296121.html Android开发中,我们经常用到JavaBean类以及序列化的知识,但经 ...
- luogu P1042 乒乓球
题目背景 国际乒联现在主席沙拉拉自从上任以来就立志于推行一系列改革,以推动乒乓球运动在全球的普及.其中11分制改革引起了很大的争议,有一部分球员因为无法适应新规则只能选择退役.华华就是其中一位,他退役 ...
- POJ-1190 蛋糕问题
这道题目我们使用深搜加剪枝的方法来写,我们首先算出一个最小表面积和最小体积来,就是半径从一递增,高度也从一递增,这是题目要求. 然后我们计算出一个底层最大的半径和最大的高度,我们就从这个最大半径和最大 ...
- Windows环境下安装 mysql-8.0.11-winx64 遇到的问题解决办法
下载mysql安装包,我的是下载mysql-8.0.11-winx64,解压到你想安装的目录下,然后配置环境(window环境下,mac本还没试过), 1.首先,配置环境:右击此电脑->属性-& ...
- (5) openssl speed(测试算法性能)和openssl rand(生成随机数)
1.1 openssl speed 测试加密算法的性能 支持的算法有: openssl speed [md2] [mdc2] [md5] [hmac] [sha1] [rmd160] [idea-cb ...
- post processing in CFD
post post Table of Contents 1. Post-processing 1.1. Reverse flow 1.1.1. reasons 1.1.2. solutions 1.2 ...
- Activiti流程定义部署方式
1 bpmn png方式部署 ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine(); /**部署流程定义(从cl ...
- jQuery常用案例总结
模态对话框 <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF ...
- ES6(Iterator 和 for...of 循环)
Iterator 和 for...of 循环 1.什么是 Iterator 接口 Iterator 接口功能:用一种相同办法的接口让不同的数据结构得到统一的读取命令的方式 2.Iterator的基本用 ...