第十七节:Scrapy爬虫框架之item.py文件以及spider中使用item
Scrapy原理图:

item位于原理图的最左边
item.py文件是报存爬取数据的容器,他使用的方法和字典很相似,但是相比字典item多了额外的保护机制,可以避免拼写错误或者定义错误。
1、创建item
在创建item时需要继承scrapy.Item类,并且定义scrapy.Field字段。由于我们在上一节Scrapy爬虫框架之项目创建spider文件数据爬取当中提取了id、url、title、thumb四个字段。所以我们在item.py文件当中需要创建者四个字段。
# -*- coding: utf-8 -*-
# item.py import scrapy class Bole_mode(scrapy.Item):
id = scrapy.Field() # id
url = scrapy.Field() # 图片链接
title = scrapy.Field() # 标题
thumb = scrapy.Field() # 缩略图
2、spider使用item
之前说过item文件是报存爬取数据的容器,所以我们在上一节当中爬取下来的数据需要使用item进行暂存。
在进行使用之前需要对这个item进行实例化 item = Bole_mode()。
代码如下
# BLZXSPider.py import scrapy
import json
import sys sys.path.append(r'D:\spider\bole\item.py')
from bole.items import Bole_mode class BoleSpider(scrapy.Spider):
name = 'boleSpider' def start_requests(self):
url = "https://image.so.com/zj?ch=photography&sn={}&listtype=new&temp=1"
page = self.settings.get("MAX_PAGE")
for i in range(int(page)+1):
yield scrapy.Request(url=url.format(i*30)) def parse(self,response):
photo_list = json.loads(response.text)
item = Bole_mode()
for image in photo_list.get("list"):
item["id"] = image["id"]
item["url"] = image["qhimg_url"]
item["title"] = image["group_title"]
item["thumb"] = image["qhimg_thumb_url"]
yield item
运行结果如下,可以看到每个url都已经请求成功。
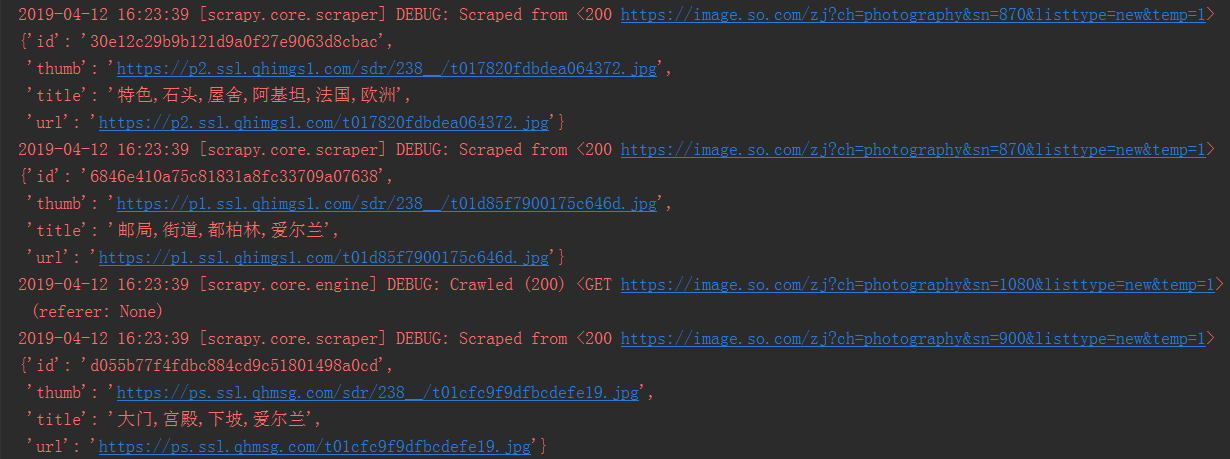
第十七节:Scrapy爬虫框架之item.py文件以及spider中使用item的更多相关文章
- 第十六节:Scrapy爬虫框架之项目创建spider文件数据爬取
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取所设计的, 也可以应用在获取API所返回的数据或 ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- Scrapy爬虫框架中的两个流程
下面对比了Scrapy爬虫框架中的两个流程—— ① Scrapy框架的基本运作流程:② Spider或其子类的几个方法的执行流程. 这两个流程是互相联系的,可对比学习. 1 ● Scrapy框架的基本 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Python-S9-Day126——Scrapy爬虫框架
01 今日内容概要 02 内容回顾和补充:scrapy 03 内容回顾和补充:网络和并发编程 04 Scrapy爬虫框架:pipeline做持久化(一) 05 Scrapy爬虫框架:pipeline做 ...
- Scrapy爬虫框架学习
一.Scrapy框架简介 1. 下载页面 2. 解析 3. 并发 4. 深度 二.安装 linux下安装 pip3 install scrapy windows下安装 a.pip3 install w ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影
前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大家讲解一个完整爬虫的流程. 工具和环境 语言:python 2 ...
随机推荐
- VMware 12安装Mac OS X 10.11&解决上网的问题
近日想在Win10上安装Mac OS 玩玩,于是上网搜了相关资源,查看了相关经验分享,开始着手安装.系统很快成功安装,但最大问题是虚拟机中的Mac OS无法上网.费了很长时间,最终看到Ping通结果, ...
- 面试杂谈:面试程序员时都应该考察些什么?<转>
一般来说,一线成熟企业技术岗位的典型招聘流程分为以下几个步骤: 初筛:一般由直接领导的技术经理或HR进行,重点考察教育和工作经历 一面:一般由可能直接与之共事的工程师进行,重点考察基础和工作能力 二面 ...
- Qt事件系统之五:事件过滤器和事件的发送
Qt提供了事件过滤器来实现在一个部件中监控其他多个部件的事件.事件过滤器与其他部件不同,它不是一个类,只是由两个函数组成的一种操作,用来完成一个部件对其他部件的事件的监视.这两个函数分别是 insta ...
- 贪心+枚举/哈希表 HDOJ Trouble
题目传送门 题意:5个集合,每个集合最多200个数字,问是否每个集合挑一个数加起来和为0. 分析:显然n^5的程序果断超时,甚至n^3logn的二分也过不了.想n^3的方法,既然判断有没有,那么可以将 ...
- ACM_逆序数(归并排序)
帮挂科 Time Limit: 2000/1000ms (Java/Others) 64bit IO Format: %lld & %llu Problem Description: 冬瓜发现 ...
- 018 [工具软件]截图贴图注释 Snipaste
Snipaste 是一个截图贴图工具,绿色免费.官方主页:https://zh.snipaste.com/. 三大功能: 1.截图,可以自动识别窗口的各元素,可以精准到像素调整截图区域大小. 2.贴图 ...
- echart动态加载数据
<!DOCTYPE html> <head> <meta charset="utf-8"> <title>EChar ...
- web api 解决Ajax请求跨域问题
前端ajax请求接口时,经常出现跨域问题,当然了解决方法有很多种,比如: http://www.jb51.net/article/68424.htm 我本人恰好前后端都会一点,所以直接在接口端处理. ...
- Spring注解驱动开发之web
前言:现今SpringBoot.SpringCloud技术非常火热,作为Spring之上的框架,他们大量使用到了Spring的一些底层注解.原理,比如@Conditional.@Import.@Ena ...
- Android 轻松实现语音朗读
语音朗读,这是一个很好的功能,可以实现一些客户的特殊要求.在Android 实现主意功能只需要几段简单的代码即可完成. 在Android 中使用语音朗读功能 只需要使用此类 TextToSpeech ...