从Hadoop框架讨论大数据
【Hadoop是什么?】
1)Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构.
2)主要解决,海量数据的存储和海量数据的分析计算问题。
3)广义上来说,HADOOP 通常是指一个更广泛的概念——HADOOP 生态圈。
【Hadoop三大发行版本】
Hadoop 三大发行版本:Apache、Cloudera、Hortonworks。
Apache 版本最原始(最基础)的版本,对于入门学习最好。
Cloudera 在大型互联网企业中用的较多。
Hortonworks 文档较好。
1)Apache Hadoop
官网地址:http://hadoop.apache.org/releases.html
下载地址:https://archive.apache.org/dist/hadoop/common/
2)Cloudera Hadoop
官网地址:https://www.cloudera.com/downloads/cdh/5-10-0.html
下载地址:http://archive-primary.cloudera.com/cdh5/cdh/5/
3)Hortonworks Hadoop
官网地址:https://hortonworks.com/products/data-center/hdp/
下载地址:https://hortonworks.com/downloads/#data-platform
【Hadoop的优势】
1)高可靠性:Hadoop 底层维护多个数据副本,所以即使 Hadoop 某个计算元素或存储出现故障,也不会导致数据的丢失。
2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
3)高效性:在 MapReduce 的思想下,Hadoop 是并行工作的,以加快任务处理速度。
4)高容错性:能够自动将失败的任务重新分配
【Hadoop的组成】
Hadoop 1.x的组成

1)Hadoop HDFS:一个高可靠、高吞吐量的分布式文件系统。
2)Hadoop MapReduce:一个分布式的资源调度和离线并行计算框架。
3)Hadoop Common:支持其他模块的工具模块(Configuration、RPC、序列化机制、日志操作)。
在 Hadoop2.x 时代,增加了 Yarn。Yarn 只负责资源的调度,MapReduce 只负责运算。
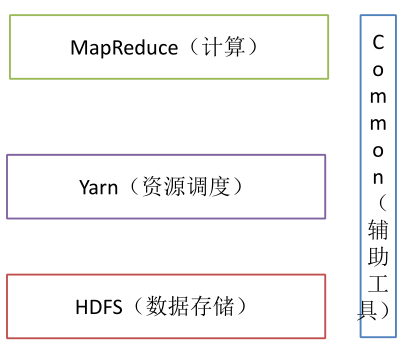
1)Hadoop HDFS:一个高可靠、高吞吐量的分布式文件系统。
2)Hadoop YARN:作业调度与集群资源管理的框架。
3)Hadoop MapReduce:一个分布式的离线并行计算框架。
4)Hadoop Common:支持其他模块的工具模块(Configuration、RPC、序列化机制、日志操作)。
【HDFS 架构概述】
1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
3)Secondary NameNode(2nn):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
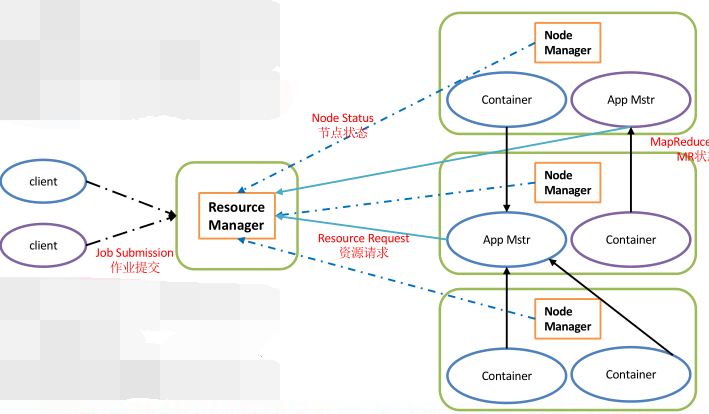
【YARN 架构概述】
1)ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;
2)NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令;
3)ApplicationMaster:数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。
4)Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
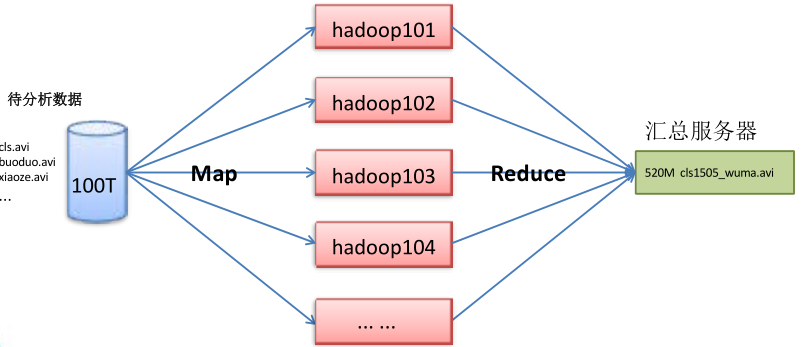
【MapReduce 架构概述】
MapReduce 将计算过程分为两个阶段:Map 和 Reduce
1)Map 阶段并行处理输入数据
2)Reduce 阶段对 Map 结果进行汇总
【大数据技术生态体系】
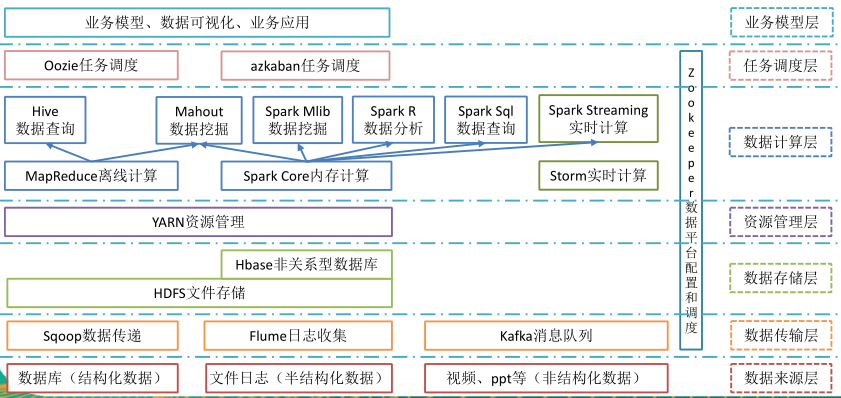
图中涉及的技术名词解释如下:
1)Sqoop:sqoop 是一款开源的工具,主要用于在 Hadoop(Hive)与传统的数据库(mysql)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle 等)中的数据导进到Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到关系型数据库中。
2)Flume:Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume 支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
3)Kafka:Kafka 是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
(1)通过 O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以 TB 的消息存储也能够保持长时间的稳定性能。
(2)高吞吐量:即使是非常普通的硬件 Kafka 也可以支持每秒数百万的消息。
(3)支持通过 Kafka 服务器和消费机集群来分区消息。
(4)支持 Hadoop 并行数据加载。
4)Storm:Storm 为分布式实时计算提供了一组通用原语,可被用于“流处理”之中,实时处理消息并更新数据库。这是管理队列及工作者集群的另一种方式。 Storm也可被用于“连续计算”(continuous computation),对数据流做连续查询,在计算时就将结果以流的形式输出给用户。
5)Spark:Spark 是当前最流行的开源大数据内存计算框架。可以基于 Hadoop 上存储的大数据进行计算。
6)Oozie:Oozie 是一个管理 Hdoop 作业(job)的工作流程调度管理系统。Oozie 协调作业就是通过时间(频率)和有效数据触发当前的 Oozie 工作流程。
7)Hbase:HBase 是一个分布式的、面向列的开源数据库。HBase 不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
8)Hive:hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的 sql 查询功能,可以将 sql 语句转换为 MapReduce 任务进行运行。其优点是学习成本低,可以通过类 SQL 语句快速实现简单的 MapReduce 统计,不必开发专门的 MapReduce 应用,十分适合数据仓库的统计分析。
10)R 语言:R 是用于统计分析、绘图的语言和操作环境。R 是属于 GNU 系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
11)Mahout:
Apache Mahout 是个可扩展的机器学习和数据挖掘库,当前 Mahout 支持主要的 4 个用例:
推荐挖掘:搜集用户动作并以此给用户推荐可能喜欢的事物。
聚集:收集文件并进行相关文件分组。
分类:从现有的分类文档中学习,寻找文档中的相似特征,并为无标签的文档进行正确的归类。
频繁项集挖掘:将一组项分组,并识别哪些个别项会经常一起出现。
12)ZooKeeper:Zookeeper 是 Google 的 Chubby 一个开源的实现。它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、 分布式同步、组服务等。ZooKeeper 的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
从Hadoop框架讨论大数据的更多相关文章
- Hadoop基础(二):从Hadoop框架讨论大数据生态
1 Hadoop是什么 2 Hadoop三大发行版本 Hadoop三大发行版本:Apache.Cloudera.Hortonworks. Apache版本最原始(最基础)的版本,对于入门学习最好. C ...
- Hadoop系列002-从Hadoop框架讨论大数据生态
本人微信公众号,欢迎扫码关注! 从Hadoop框架讨论大数据生态 1.Hadoop是什么 1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构 2)主要解决,海量数据的存储和海量数据的 ...
- 啃掉Hadoop系列笔记(01)-Hadoop框架的大数据生态
一.Hadoop是什么 1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构 2)主要解决,海量数据的存储和海量数据的分析计算问题. 3)广义上来说,HADOOP通常是指一个更广泛的概 ...
- hadoop job解决大数据量关联时数据倾斜的一种办法
转自:http://www.cnblogs.com/xuxm2007/archive/2011/09/01/2161929.html http://www.geminikwok.com/2011/04 ...
- 后Hadoop时代的大数据架构(转)
原文:http://zhuanlan.zhihu.com/donglaoshi/19962491 作者: 董飞 提到大数据分析平台,不得不说Hadoop系统,Hadoop到现在也超过10年 ...
- 从 RAID 到 Hadoop Hdfs 『大数据存储的进化史』
我们都知道现在大数据存储用的基本都是 Hadoop Hdfs ,但在 Hadoop 诞生之前,我们都是如何存储大量数据的呢?这次我们不聊技术架构什么的,而是从技术演化的角度来看看 Hadoop Hdf ...
- 后Hadoop时代的大数据技术思考:数据即服务
1. Hadoop 的神话正在破灭 IBM leads BigInsights for Hadoop out behind barn. Shots heard IBM has announced th ...
- 后Hadoop时代的大数据架构
提到大数据分析平台,不得不说Hadoop系统,Hadoop到现在也超过10年的历史了,很多东西发生了变化,版本也从0.x进化到目前的2.6版本.我把2012年后定义成后Hadoop平台时代,这不是说不 ...
- 搭建Hadoop+Python的大数据开发环境
实验环境 CentOS镜像为CentOS-7-x86_64-Everything-1804.iso 虚机配置 节点名称 IP地址 子网掩码 CPU/内存 磁盘 安装方式 master 192.168. ...
随机推荐
- 题解报告:hdu 1261 字串数
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1261 Problem Description 一个A和两个B一共可以组成三种字符串:"ABB ...
- 1268 和为K的组合 Meet in mid二分思路
http://www.51nod.com/onlineJudge/questionCode.html#!problemId=1268&judgeId=193772 给出n = 20个数,问其是 ...
- Apache Tomcat 之路(三 部署多个应用)
想要在一台服务器上部署多个web应用的时候有两种部署方式:1.拷贝多个tomcat 服务器,每个服务器启动不同的web应用;2.一个tomcat容器部署多个web应用 两种方式的优缺点:多个tomca ...
- spring.net应用
经过一段时间的调试,终于把spring.net中关于aop的方面给做个了一个比较完整的Demo.包含异常日志和性能日志.spring.net和log4net配置. http://files.cnblo ...
- Node.js——网站访问一般流程
- CSS3 四边形 凹角写法
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 几个net命令
A.显示当前工作组服务器列表 net view,当不带选项使用本命令时,它就会显示当前域或网络上的计算机上的列表. 比如:查看这个IP上的共享资源,就可以 C:\\>net view 192 ...
- python的logging的简单使用
用Python写代码的时候,在想看的地方写个print xx 就能在控制台上显示打印信息,这样子就能知道它是什么了,但是当我需要看大量的地方或者在一个文件中查看的时候,这时候print就不大方便了,所 ...
- spark版本不支持(降版本打包)
在做项目的时候代码已经更新为hadoop 2.7 spark 2.1 scala 2.11.8版本,但是服务器版本使用的是hadoop2.6 spark1.6 以及scala2.10.6版本,,主程 ...
- Domain Adaptation论文笔记
领域自适应问题一般有两个域,一个是源域,一个是目标域,领域自适应可利用来自源域的带标签的数据(源域中有大量带标签的数据)来帮助学习目标域中的网络参数(目标域中很少甚至没有带标签的数据).领域自适应如今 ...