2 基于梯度的攻击——PGD
PGD攻击原论文地址——https://arxiv.org/pdf/1706.06083.pdf
1.PGD攻击的原理
PGD(Project Gradient Descent)攻击是一种迭代攻击,可以看作是FGSM的翻版——K-FGSM (K表示迭代的次数),大概的思路就是,FGSM是仅仅做一次迭代,走一大步,而PGD是做多次迭代,每次走一小步,每次迭代都会将扰动clip到规定范围内。
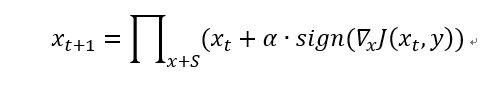
一般来说,PGD的攻击效果比FGSM要好。首先,如果目标模型是一个线性模型,那么用FGSM就可以了,因为此时loss对输入的导数是固定的,换言之,使得loss下降的方向是明确的,即使你多次迭代,扰动的方向也不会改变。而对于一个非线性模型,仅仅做一次迭代,方向是不一定完全正确的,这也是为什么FGSM的效果一般的原因了。

上图中,黑圈是输入样本,假设样本只有两维,那么样本可以改变的就有八个方向,坐标系中显示了loss等高线,以及可以扰动的最大范围(因为是无穷范数,所以限制范围是一个方形,负半轴的范围没有画出来),黑圈每一次改变,都是以最优的方向改变,最后一次由于扰动超出了限制,所以直接截断,如果此时迭代次数没有用完,那么就在截断处继续迭代,直到迭代次数用完。
2.PGD的代码实现
class PGD(nn.Module):
def __init__(self,model):
super().__init__()
self.model=model#必须是pytorch的model
self.device=torch.device("cuda" if (torch.cuda.is_available()) else "cpu")
def generate(self,x,**params):
self.parse_params(**params)
labels=self.y adv_x=self.attack(x,labels)
return adv_x
def parse_params(self,eps=0.3,iter_eps=0.01,nb_iter=40,clip_min=0.0,clip_max=1.0,C=0.0,
y=None,ord=np.inf,rand_init=True,flag_target=False):
self.eps=eps
self.iter_eps=iter_eps
self.nb_iter=nb_iter
self.clip_min=clip_min
self.clip_max=clip_max
self.y=y
self.ord=ord
self.rand_init=rand_init
self.model.to(self.device)
self.flag_target=flag_target
self.C=C def sigle_step_attack(self,x,pertubation,labels):
adv_x=x+pertubation
# get the gradient of x
adv_x=Variable(adv_x)
adv_x.requires_grad = True
loss_func=nn.CrossEntropyLoss()
preds=self.model(adv_x)
if self.flag_target:
loss =-loss_func(preds,labels)
else:
loss=loss_func(preds,labels)
# label_mask=torch_one_hot(labels)
#
# correct_logit=torch.mean(torch.sum(label_mask * preds,dim=1))
# wrong_logit = torch.mean(torch.max((1 - label_mask) * preds, dim=1)[0])
# loss=-F.relu(correct_logit-wrong_logit+self.C) self.model.zero_grad()
loss.backward()
grad=adv_x.grad.data
#get the pertubation of an iter_eps
pertubation=self.iter_eps*np.sign(grad)
adv_x=adv_x.cpu().detach().numpy()+pertubation.cpu().numpy()
x=x.cpu().detach().numpy() pertubation=np.clip(adv_x,self.clip_min,self.clip_max)-x
pertubation=clip_pertubation(pertubation,self.ord,self.eps) return pertubation
def attack(self,x,labels):
labels = labels.to(self.device)
print(self.rand_init)
if self.rand_init:
x_tmp=x+torch.Tensor(np.random.uniform(-self.eps, self.eps, x.shape)).type_as(x).cuda()
else:
x_tmp=x
pertubation=torch.zeros(x.shape).type_as(x).to(self.device)
for i in range(self.nb_iter):
pertubation=self.sigle_step_attack(x_tmp,pertubation=pertubation,labels=labels)
pertubation=torch.Tensor(pertubation).type_as(x).to(self.device)
adv_x=x+pertubation
adv_x=adv_x.cpu().detach().numpy() adv_x=np.clip(adv_x,self.clip_min,self.clip_max) return adv_x
PGD攻击的参数并不多,比较重要的就是下面这几个:
eps: maximum distortion of adversarial example compared to original input
eps_iter: step size for each attack iteration
nb_iter: Number of attack iterations.
上面代码中注释的这行代码是CW攻击的PGD形式,这个在防御论文https://arxiv.org/pdf/1706.06083.pdf中有体现,以后说到CW攻击再细说。
1 # label_mask=torch_one_hot(labels)
2 #
3 # correct_logit=torch.mean(torch.sum(label_mask * preds,dim=1))
4 # wrong_logit = torch.mean(torch.max((1 - label_mask) * preds, dim=1)[0])
5 # loss=-F.relu(correct_logit-wrong_logit+self.C)
最后再提一点就是,在上面那篇防御论文中也提到了,PGD攻击是最强的一阶攻击,如果防御方法对这个攻击能够有很好的防御效果,那么其他攻击也不在话下了。
2 基于梯度的攻击——PGD的更多相关文章
- 3.基于梯度的攻击——PGD
PGD攻击原论文地址——https://arxiv.org/pdf/1706.06083.pdf 1.PGD攻击的原理 PGD(Project Gradient Descent)攻击是一种迭代攻击,可 ...
- 2.基于梯度的攻击——FGSM
FGSM原论文地址:https://arxiv.org/abs/1412.6572 1.FGSM的原理 FGSM的全称是Fast Gradient Sign Method(快速梯度下降法),在白盒环境 ...
- 1 基于梯度的攻击——FGSM
FGSM原论文地址:https://arxiv.org/abs/1412.6572 1.FGSM的原理 FGSM的全称是Fast Gradient Sign Method(快速梯度下降法),在白盒环境 ...
- 4.基于梯度的攻击——MIM
MIM攻击原论文地址——https://arxiv.org/pdf/1710.06081.pdf 1.MIM攻击的原理 MIM攻击全称是 Momentum Iterative Method,其实这也是 ...
- 3 基于梯度的攻击——MIM
MIM攻击原论文地址——https://arxiv.org/pdf/1710.06081.pdf 1.MIM攻击的原理 MIM攻击全称是 Momentum Iterative Method,其实这也是 ...
- 5.基于优化的攻击——CW
CW攻击原论文地址——https://arxiv.org/pdf/1608.04644.pdf 1.CW攻击的原理 CW攻击是一种基于优化的攻击,攻击的名称是两个作者的首字母.首先还是贴出攻击算法的公 ...
- 4 基于优化的攻击——CW
CW攻击原论文地址——https://arxiv.org/pdf/1608.04644.pdf 1.CW攻击的原理 CW攻击是一种基于优化的攻击,攻击的名称是两个作者的首字母.首先还是贴出攻击算法的公 ...
- 基于梯度场和Hessian特征值分别获得图像的方向场
一.我们想要求的方向场的定义为: 对于任意一点(x,y),该点的方向可以定义为其所在脊线(或谷线)位置的切线方向与水平轴之间的夹角: 将一条直线顺时针或逆时针旋转 180°,直线的方向保持不变. 因 ...
- C / C ++ 基于梯度下降法的线性回归法(适用于机器学习)
写在前面的话: 在第一学期做项目的时候用到过相应的知识,觉得挺有趣的,就记录整理了下来,基于C/C++语言 原贴地址:https://helloacm.com/cc-linear-regression ...
随机推荐
- js中for..of..和迭代器
for..of是ES6中引入的新特性,它主要的作用是:循环一个可迭代的对象. 它可以循环遍历,数组.字符串.Set对象等等 示例一: let str = 'hello' for (item of st ...
- CodeFroces 758C - Unfair Poll
题意: 老师点名,顺序是1 -- n -- 1 排为一个循环,每列为1 -- m的顺序, 问点到最多次数和最少次数的人的次数以及(x,y)被点的次数. 分析: 由于点名有循环,故可先判断出每一个循环每 ...
- 第一次 CSP-S 的游记
菜得很啊菜得很! --PinkRabbit 第一次 CSP-S ,真的是 第一次. 作为一名初三学生,虽然是 第一次 参加 和NOIP没有任何关系 的 CSP-S ,总是要有点目标呀. 第一试 因为是 ...
- jmeter 5.0,http请求登录返回的cookie在头部处理方法
http登录之后返回的cookie在响应的头部,再次请求虽然加了cookie管理器,但是下一个请求调用响应是登陆失效,这里讲一下我的解决方法 1:在登录之后添加正则表达式,提取cookie 2:提取之 ...
- bzoj4321
queue2 HYSBZ - 4321 n 个沙茶,被编号 1~n.排完队之后,每个沙茶希望,自己的相邻的两 人只要无一个人的编号和自己的编号相差为 1(+1 或-1)就行: 现在想知道,存在多少方 ...
- Java集合框架之接口Collection源码分析
本文我们主要学习Java集合框架的根接口Collection,通过本文我们可以进一步了解Collection的属性及提供的方法.在介绍Collection接口之前我们不得不先学习一下Iterable, ...
- Linux网络编程二、tcp连接API
一.服务端 1.创建套接字: int socket(int domain, int type, int protocol); domain:指定协议族,通常选用AF_INET. type:指定sock ...
- Android_activity实现一个简单的新建联系表
项目展示: 第一个Activity用于显示联系人信息 第二个Activity输入联系人信息 要求: 运行“新建联系人”程序,结果如下图所示: 点击“新建联系人”按钮,打开输入信息界面并输入姓名.公司. ...
- mongodb远程链接命令
mongo 172.17.0.170:27017/spider_data -u admin -p 然后输入密码 切换数据库 use spider_data 查看所有表 show tables
- (十三)C语言之break、continue