python视频学习笔记5(高级变量的类型)
知识点回顾:
Python 中数据类型可以分为 **数字型** 和 **非数字型**
* 数字型
* 整型 (`int`)
* 浮点型(`float`)
* 布尔型(`bool`)
* 真 `True` `非 0 数` —— **非零即真**
* 假 `False` `0`
* 复数型 (`complex`)
* 主要用于科学计算,例如:平面场问题、波动问题、电感电容等问题
* 非数字型
* 字符串
* 列表
* 元组
* 字典
* 在 `Python` 中,所有 **非数字型变量** 都支持以下特点:
1. 都是一个 **序列** `sequence`,也可以理解为 **容器**
2. **取值** `[]`
3. **遍历** `for in`
4. **计算长度**、**最大/最小值**、**比较**、**删除**
5. **链接** `+` 和 **重复** `*`
6. **切片**
一。列表
1.列表的定义
* 列表用 `[]` 定义,**数据** 之间使用 `,` 分隔
* 列表的 **索引** 从 `0` 开始
注意:从列表中取值时,如果 **超出索引范围**,程序会报错
name_list = ["zhangsan", "lisi", "wangwu"]
2.列表的常用操作
* 输入 `name_list.` 按下 `TAB` 键,`ipython` 会提示 **列表** 能够使用的 **方法** 如下:
```
In [1]: name_list.
name_list.append name_list.count name_list.insert name_list.reverse
name_list.clear name_list.extend name_list.pop name_list.sort
name_list.copy name_list.index name_list.remove
```
| 序号 | 分类 | 关键字 / 函数 / 方法 | 说明 |
| --- | --- | --- | --- |
| 1 | 增加 | 列表.insert(索引, 数据) | 在指定位置插入数据 |
| | | 列表.append(数据) | 在末尾追加数据
| | | 列表.extend(列表2) | 将列表2 的数据追加到列表 |
| 2 | 修改 | 列表[索引] = 数据 | 修改指定索引的数据 |
| 3 | 删除 | del 列表[索引] | 删除指定索引的数据 |
| | | 列表.remove[数据] | 删除第一个出现的指定数据 |
| | | 列表.pop | 删除末尾数据 |
| | | 列表.pop(索引) | 删除指定索引数据 |
| | | 列表.clear | 清空列表 |
| 4 | 统计 | len(列表) | 列表长度 |
| | | 列表.count(数据) | 数据在列表中出现的次数 |
| 5 | 排序 | 列表.sort() | 升序排序 |
| | | 列表.sort(reverse=True) | 降序排序 |
| | | 列表.reverse() | 逆序、反转 |
注意:del不是方法是,关键字,和remove区别在于
* `del` 关键字本质上是用来 **将一个变量从内存中删除的**
* 如果使用 `del` 关键字将变量从内存中删除,后续的代码就不能再使用这个变量了
3.del操作

4.关键字、函数和方法的区别是什么?
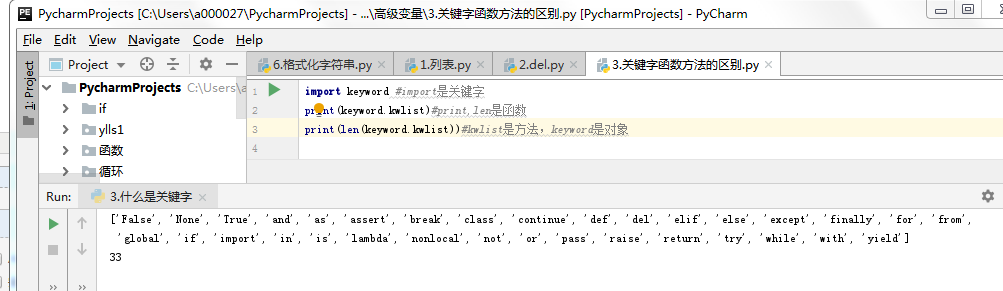
关键字:
比如 if for,while等,是 Python 内置的、具有特殊意义的标识符。
关键字后面不需要使用括号
函数:
函数** 封装了独立功能,可以直接调用
格式:函数名(参数)
方法:
*方法** 需要通过 **对象** 来调用,表示针对这个 **对象** 要做的操作
对象.方法名(参数)
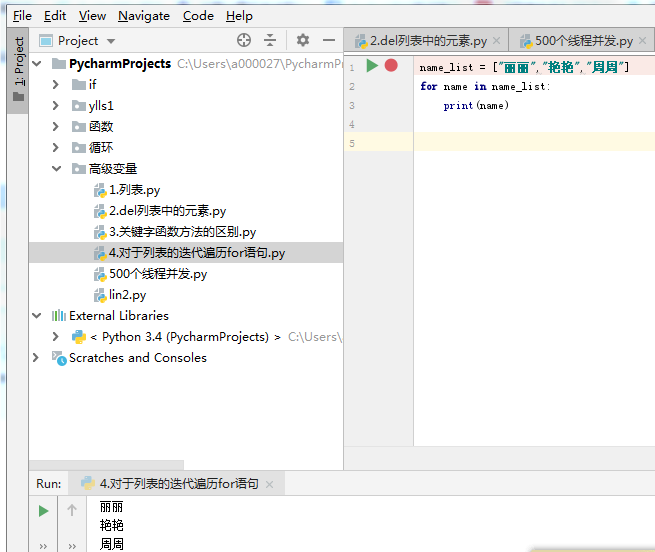
5.循环遍历
**遍历** 就是 **从头到尾** **依次** 从 **列表** 中获取数据
* 在 **循环体内部** 针对 **每一个元素**,执行相同的操作
使用 `for` 就能够实现迭代遍历
语法:
# for 循环内部使用的变量 in 列表
for name in name_list:
循环内部针对列表元素进行操作
print(name)
二。元组
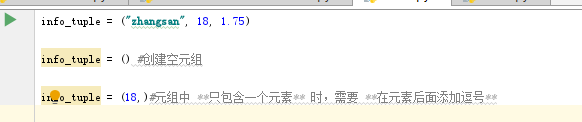
1.元组的定义
Tuple`(元组)与列表类似,不同之处在于元组的 **元素不能修改**
元组的 **索引** 从 `0` 开始
* **索引** 就是数据在 **元组** 中的位置编号
2.能够使用的函数:
```python
info.count info.index
```
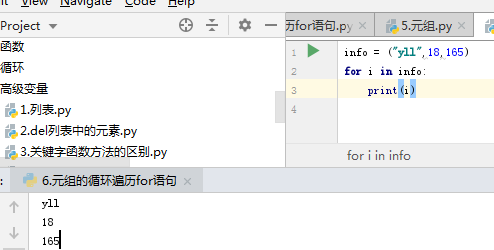
3.循环遍历
> * 在 `Python` 中,可以使用 `for` 循环遍历所有非数字型类型的变量:**列表**、**元组**、**字典** 以及 **字符串**
格式化字符串和数组的配合使用
* **让列表不可以被修改**,以保护数据安全

4.元组和列表之间的转换
* 使用 `list` 函数可以把元组转换成列表
```python
list(元组)
```
* 使用 `tuple` 函数可以把列表转换成元组
```python
tuple(列表)
三。字典
1.字典的定义
通常用于存储 **描述一个 `物体` 的相关信息**
* 和列表的区别
* **列表** 是 **有序** 的对象集合
* **字典** 是 **无序** 的对象集合
yinlili = {"name":"yll",
"age":18,
"gender":True,
"height":1.65}
2.字典常用操作
In [1]: xiaoming.
xiaoming.clear xiaoming.items xiaoming.setdefault
xiaoming.copy xiaoming.keys xiaoming.update
xiaoming.fromkeys xiaoming.pop xiaoming.values
xiaoming.get xiaoming.popitem
3.循环遍历
遍历** 就是 **依次** 从 **字典** 中获取所有键值对
语法和列表元组不同:
print("%s: %s" % (k, xiaoming[k]))

4。实际场景下-----将 **多个字典** 放在 **一个列表** 中
```python
card_list = [{"name": "张三",
"qq": "12345",
"phone": "110"},
{"name": "李四",
"qq": "54321",
"phone": "10086"}
]
```
四。字符串
1.字符串的定义
在 Python 中可以使用 **一对双引号** `"` 或者 **一对单引号** `'` 定义一个字符串
* 虽然可以使用 `\"` 或者 `\'` 做字符串的转义,但是在实际开发中:
* 如果字符串内部需要使用 `"`,可以使用 `'` 定义字符串
* 如果字符串内部需要使用 `'`,可以使用 `"` 定义字符串
* 可以使用 **索引** 获取一个字符串中 **指定位置的字符**,索引计数从 **0** 开始
* 也可以使用 `for` **循环遍历** 字符串中每一个字符
2.字符串遍历
```python
string = "Hello Python"
for c in string:
print(c)
```
3.常用方法
In [1]: hello_str.
hello_str.capitalize hello_str.isidentifier hello_str.rindex
hello_str.casefold hello_str.islower hello_str.rjust
hello_str.center hello_str.isnumeric hello_str.rpartition
hello_str.count hello_str.isprintable hello_str.rsplit
hello_str.encode hello_str.isspace hello_str.rstrip
hello_str.endswith hello_str.istitle hello_str.split
hello_str.expandtabs hello_str.isupper hello_str.splitlines
hello_str.find hello_str.join hello_str.startswith
hello_str.format hello_str.ljust hello_str.strip
hello_str.format_map hello_str.lower hello_str.swapcase
hello_str.index hello_str.lstrip hello_str.title
hello_str.isalnum hello_str.maketrans hello_str.translate
hello_str.isalpha hello_str.partition hello_str.upper
hello_str.isdecimal hello_str.replace hello_str.zfill
hello_str.isdigit hello_str.rfind
#### 1) 判断类型 - 9
| 方法 | 说明 |
| --- | --- |
| string.isspace() | 如果 string 中只包含空格,则返回 True |
| string.isalnum() | 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True |
| string.isalpha() | 如果 string 至少有一个字符并且所有字符都是字母则返回 True |
| string.isdecimal() | 如果 string 只包含数字则返回 True,`全角数字` |
| string.isdigit() | 如果 string 只包含数字则返回 True,`全角数字`、`⑴`、`\u00b2` |
| string.isnumeric() | 如果 string 只包含数字则返回 True,`全角数字`,`汉字数字` |
| string.istitle() | 如果 string 是标题化的(每个单词的首字母大写)则返回 True |
| string.islower() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True |
| string.isupper() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True |
#### 2) 查找和替换 - 7
| 方法 | 说明 |
| --- | --- |
| string.startswith(str) | 检查字符串是否是以 str 开头,是则返回 True |
| string.endswith(str) | 检查字符串是否是以 str 结束,是则返回 True |
| string.find(str, start=0, end=len(string)) | 检测 str 是否包含在 string 中,如果 start 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回 `-1` |
| string.rfind(str, start=0, end=len(string)) | 类似于 find(),不过是从右边开始查找 |
| string.index(str, start=0, end=len(string)) | 跟 find() 方法类似,不过如果 str 不在 string 会报错 |
| string.rindex(str, start=0, end=len(string)) | 类似于 index(),不过是从右边开始 |
| string.replace(old_str, new_str, num=string.count(old)) | 把 string 中的 old_str 替换成 new_str,如果 num 指定,则替换不超过 num 次 |
#### 3) 大小写转换 - 5
| 方法 | 说明 |
| --- | --- |
| string.capitalize() | 把字符串的第一个字符大写 |
| string.title() | 把字符串的每个单词首字母大写 |
| string.lower() | 转换 string 中所有大写字符为小写 |
| string.upper() | 转换 string 中的小写字母为大写 |
| string.swapcase() | 翻转 string 中的大小写 |
#### 4) 文本对齐 - 3
| 方法 | 说明 |
| --- | --- |
| string.ljust(width) | 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 |
| string.rjust(width) | 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 |
| string.center(width) | 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 |
#### 5) 去除空白字符 - 3
| 方法 | 说明 |
| --- | --- |
| string.lstrip() | 截掉 string 左边(开始)的空白字符 |
| string.rstrip() | 截掉 string 右边(末尾)的空白字符 |
| string.strip() | 截掉 string 左右两边的空白字符 |
#### 6) 拆分和连接 - 5
| 方法 | 说明 |
| --- | --- |
| string.partition(str) | 把字符串 string 分成一个 3 元素的元组 (str前面, str, str后面) |
| string.rpartition(str) | 类似于 partition() 方法,不过是从右边开始查找 |
| string.split(str="", num) | 以 str 为分隔符拆分 string,如果 num 有指定值,则仅分隔 num + 1 个子字符串,str 默认包含 '\r', '\t', '\n' 和空格 |
| string.splitlines() | 按照行('\r', '\n', '\r\n')分隔,返回一个包含各行作为元素的列表 |
| string.join(seq) | 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
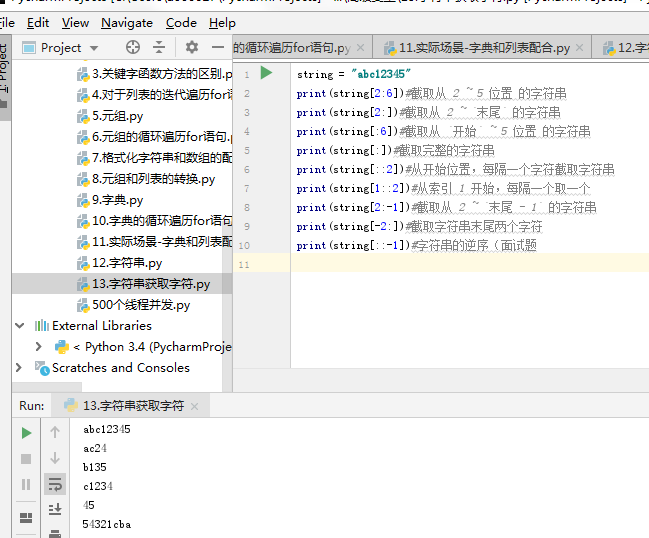
4.字符串切片
**切片** 方法适用于 **字符串**、**列表**、**元组**
* **切片** 使用 **索引值** 来限定范围,从一个大的 **字符串** 中 **切出** 小的 **字符串**
* **列表** 和 **元组** 都是 **有序** 的集合,都能够 **通过索引值** 获取到对应的数据
* **字典** 是一个 **无序** 的集合,是使用 **键值对** 保存数据
```
字符串[开始索引:结束索引:步长]
```
**注意**:
1. 指定的区间属于 **左闭右开** 型 `[开始索引, 结束索引)` => `开始索引 >= 范围 < 结束索引`
* 从 `起始` 位开始,到 **`结束`位的前一位** 结束(**不包含结束位本身**)
2. 从头开始,**开始索引** **数字可以省略,冒号不能省略**
3. 到末尾结束,**结束索引** **数字可以省略,冒号不能省略**
4. 步长默认为 `1`,如果连续切片,**数字和冒号都可以省略**
#### 索引的顺序和倒序
* 在 Python 中不仅支持 **顺序索引**,同时还支持 **倒序索引**
* 所谓倒序索引就是 **从右向左** 计算索引
* 最右边的索引值是 **-1**,依次递减
五。公共方法(针对字符串,列表,元组,字典都可以使用)
1.内置函数
Python 包含了以下内置函数:
| 函数 | 描述 | 备注 |
| --- | --- | --- |
| len(item) | 计算容器中元素个数 | |
| del(item) | 删除变量 | del 有两种方式 |
| max(item) | 返回容器中元素最大值 | 如果是字典,只针对 key 比较 |
| min(item) | 返回容器中元素最小值 | 如果是字典,只针对 key 比较 |
| cmp(item1, item2) | 比较两个值,-1 小于/0 相等/1 大于 | Python 3.x 取消了 cmp 函数 |
**注意**
* **字符串** 比较符合以下规则: "0" < "A" < "a"
2.切片
| 描述 | Python 表达式 | 结果 | 支持的数据类型 |
| :---: | --- | --- | --- | --- |
| 切片 | "0123456789"[::-2] | "97531" | 字符串、列表、元组 |
* **切片** 使用 **索引值** 来限定范围,从一个大的 **字符串** 中 **切出** 小的 **字符串**
* **列表** 和 **元组** 都是 **有序** 的集合,都能够 **通过索引值** 获取到对应的数据
* **字典** 是一个 **无序** 的集合,是使用 **键值对** 保存数据
3.运算符
| 运算符 | Python 表达式 | 结果 | 描述 | 支持的数据类型 |
| :---: | --- | --- | --- | --- |
| + | [1, 2] + [3, 4] | [1, 2, 3, 4] | 合并 | 字符串、列表、元组 |
| * | ["Hi!"] * 4 | ['Hi!', 'Hi!', 'Hi!', 'Hi!'] | 重复 | 字符串、列表、元组 |
| in | 3 in (1, 2, 3) | True | 元素是否存在 | 字符串、列表、元组、字典 |
| not in | 4 not in (1, 2, 3) | True | 元素是否不存在 | 字符串、列表、元组、字典 |
| > >= == < <= | (1, 2, 3) < (2, 2, 3) | True | 元素比较 | 字符串、列表、元组 |
**注意**
* `in` 在对 **字典** 操作时,判断的是 **字典的键**
* `in` 和 `not in` 被称为 **成员运算符**
#### 成员运算符
成员运算符用于 **测试** 序列中是否包含指定的 **成员**
| 运算符 | 描述 | 实例 |
| --- | --- | --- |
| in | 如果在指定的序列中找到值返回 True,否则返回 False | `3 in (1, 2, 3)` 返回 `True` |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False | `3 not in (1, 2, 3)` 返回 `False` |
注意:在对 **字典** 操作时,判断的是 **字典的键**
4.完整的for 循环语法
* 在 `Python` 中完整的 `for 循环` 的语法如下:
```python
for 变量 in 集合:
循环体代码
else:
没有通过 break 退出循环,循环结束后,会执行的代码
```
#### 应用场景
* 在 **迭代遍历** 嵌套的数据类型时,例如 **一个列表包含了多个字典**
* 需求:要判断 某一个字典中 是否存在 指定的 值
* 如果 **存在**,提示并且退出循环
* 如果 **不存在**,在 **循环整体结束** 后,希望 **得到一个统一的提示**

python视频学习笔记5(高级变量的类型)的更多相关文章
- python视频学习笔记3(循环)
一.程序的三大流程 二.while 初始条件设置 —— 通常是重复执行的 计数器 while 条件(判断 计数器 是否达到 目标次数): 条件满足时,做的事情1 条件满足时,做的事情2 条件满足时,做 ...
- python基础学习(三)变量和类型
变量的作用:变量就是用来存储数据的. 变量的定义 在python中,变量在使用之前需要进行赋值,变量只有赋值后才能使用,如果变量没有赋值就使用会出现什么情况呢?如下图,使用之前变量未定义,会报错,如下 ...
- python视频学习笔记2(if)
一.if语句1.比较运算符,if语句语法 # 1. 输入用户年龄# 2. 判断是否满 18 岁 (**>=**)# 3. 如果满 18 岁,允许进网吧嗨皮# 4. 如果未满 18 岁,提示回家写 ...
- python视频学习笔记4(函数)
函数中return和print的区别,没有return会默认返回None值 函数定义:所谓**函数**,就是把 **具有独立功能的代码块** 组织为一个小模块,在需要的时候 **调用** 1.函数的步 ...
- python视频学习笔记6(名片管理系统开发)
cards_main.py主函数 cards_tools.py -------------------------------------------------------------------- ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- Hadoop学习笔记(7) ——高级编程
Hadoop学习笔记(7) ——高级编程 从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤: 1.输入(input):将输入数据分成一个个split,并将split进一步拆成 ...
- Python Click 学习笔记(转)
原文链接:Python Click 学习笔记 Click 是 Flask 的团队 pallets 开发的优秀开源项目,它为命令行工具的开发封装了大量方法,使开发者只需要专注于功能实现.恰好我最近在开发 ...
- Python Flask学习笔记之模板
Python Flask学习笔记之模板 Jinja2模板引擎 默认情况下,Flask在程序文件夹中的templates子文件夹中寻找模板.Flask提供的render_template函数把Jinja ...
随机推荐
- Orcal nvl函数
NVL(E1, E2)的功能为:如果E1为NULL,则函数返回E2,否则返回E1本身.但此函数有一定局限,所以就有了NVL2函数. 拓展:NVL2函数:Oracle/PLSQL中的一个函数,Oracl ...
- Session案例-用户登录场景
package com.loaderman.demo; import java.io.IOException; import java.io.PrintWriter; import javax.ser ...
- tensorflow二进制文件读取与tfrecords文件读取
1.知识点 """ TFRecords介绍: TFRecords是Tensorflow设计的一种内置文件格式,是一种二进制文件,它能更好的利用内存, 更方便复制和移动,为 ...
- js控件实现修改预览的功能
http://nytimes.github.io/ice/demo/ https://johnresig.com/projects/javascript-diff-algorithm/
- python的I/O编程:文件打开、操作文件和目录、序列化操作
1 文件读写 1.1 打开文件: open(r'D:\text.txt') 1.2 文件模式 值 功能描述 'r' 读模式 'w' 写模式 'a' 追加模式 'b' 二进制模式 '+' 读写模式 1. ...
- django在进行模板render(渲染)时,对传过来的是字典中包含字典应用方法
网上自强学堂参考的 views.py def home(request): info_dict = {'site': u'自强学堂', 'content': u'各种IT技术教程'} return r ...
- JavaScript基础入门10
目录 JavaScript 基础入门10 正则表达式 为什么使用正则表达式? 正则表达式的应用场景 如何创建一个正则表达式 基础语法 具有特殊意义的转义字符 量词 字符类 贪婪模式 练习 邮箱验证 中 ...
- Java并发编程之程序运行堆栈分析
Java程序运行的堆栈分析 1.JVM运行时数据区 JVM通过加载class文件的数据来执行程序.JVM在运行时会划分不同的区域以存放数据.如下图所示: 线程共享部分:所有线程都能访问这块内存的数据, ...
- Django路由系统-URLconf配置、正则表达式简述
Django路由系统 1.11版本官方文档 URL配置就像是Django项目的目录,它的本质是URL与URL调用的函数之间的映射表,Django会根据URL配置,在遇到一个URL时,就去执行相应的 ...
- Django模板系统-内置和自定义Filters
django模板中最常用的两种特殊符号是 {{ }} 用来表示变量和 {% %} 用来表示逻辑相关的操作 变量 {{ 变量名 }} ,由字母数字下划线组成而.在模板语言中有特殊含义,用来获取对象相应的 ...