1.Storm概述简介
主要目标:
1. 离线计算是什么?
2. 流式计算是什么?
3. 流式计算与离线计算的区别?
4. Storm是什么?
5. Storm与Hadoop的区别?
6. Storm的应用场景及行业案例
7. Storm的核心组件(重点)
8. Storm的编程模型(重点)
9. 流式计算的一般架构图(重点)
1.流式计算与Storm概述(背景):
根据业务需求,数据的处理可以分为离线处理和实时(流式)处理,在离线处理方面Hadoop提供了很好的解决方案,Hadoop不仅可以用
来存储海量数据,还以用来计算海量数据。因为其高吞吐、高可靠等特点,很多互联网公司都已经使用Hadoop来构建数据仓库,高频使用
并促进了Hadoop生态圈的各项技术的发展.但是针对海量数据的实时处理却一直没有比较好的解决方案,Storm横空出世,与生俱来的分布式
、高可靠、高吞吐的特性,横扫市面上的一些流式计算框架,渐渐的成为了流式计算的首选框架;
3.离线计算是什么?
离线计算:批量获取数据、批量传输数据、周期性批量计算数据、数据展示
代表技术:Sqoop批量导入数据、HDFS批量存储数据、MapReduce批量计算数据、Hive批量计算数据、批量计算任务调度
相关岗位日常业务:
1,hivesql
2、调度平台
3、Hadoop集群运维
4、数据清洗(脚本语言)
5、元数据管理
6、数据稽查
7、数据仓库模型架构
4.流式计算是什么?
流式计算:数据实时产生、数据实时传输、数据实时计算、实时展示
代表技术:Flume实时获取数据、Kafka/metaq实时数据存储、Storm/JStorm实时数据计算、Redis实时结果缓存、持久化存储(mysql)。
一句话总结:将源源不断产生的数据实时收集并实时计算,尽可能快(依赖外部系统)的得到计算结果
所以:离线计算和实时计算的最大区别在于:实时计算是:实时收集、实时计算、实时展示的
5.Storm是什么?
Flume实时采集,低延迟
Kafka消息队列,低延迟
Storm实时计算,低延迟
Redis实时存储,低延迟
Storm用来实时处理数据,特点:低延迟、高可用、分布式、可扩展、数据不丢失。提供简单容易理解的接口,便于开发。
6.Storm的应用场景及其行业案例:
Storm用来实时计算源源不断产生的数据,如同流水线生产
6.1:应用场景:
案列2:实时分析系统监控携程网的网站性能
案列3:游戏实时运营
案列4:实时计算在腾讯的运用
案列5:阿里妈妈--用户画像,实时计算用户的兴趣数据
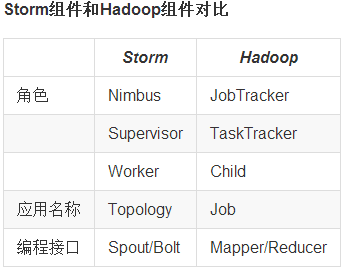
7.Storm和Hadoop的区别:
Storm用于实时计算,Hadoop是面向基于内存流转的离线计算。
Storm处理的数据保存在内存中,源源不断;Hadoop处理的数据保存在文件系统中,一批一批(数据存储的介质不同)
Storm的数据通过网络传输进来;Hadoop的数据保存在磁盘中。(Hadoop是磁盘级计算,进行计算时,数据在磁盘上,需要读写
磁盘;Storm是内存级计算,数据直接通过网络导入内存。读写内存比读写磁盘速度快n个数量级)
Storm与Hadoop的架构一样,编程模型相似
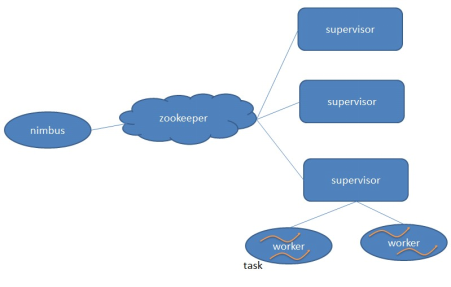
8.Storm的核心组件(重点):
9.Storm的编程模型(重点):

各个组件说明:
1.DataSource:外部数据源
2.Topology:Storm中运行的一个实时应用程序的名称,因为各个组件间的消息流动形成逻辑上的一个拓扑结构
3.Spout:在一个Topology中获取源数据流的组件,通常情况下spout会从外部数据源中读取数据,然后转换为Storm内部的源数据。
以Tuple为基本的传输单元下发给Bolt,Spout是一个主动的角色,其接口中有个nextTuple()函数,storm框架会不停地调用此函数,用户
只要在其中生成源数据即可
4.Bolt:在一个Topology中接收数据然后执行处理的组件,Bolt可以执行过滤、函数操作、合并、写数据库等任何操作。Bolt是一个
被动的角色,其接口中有个execute(Tuple input)函数,在接受到消息后会调用此函数,用户可以在其中执行自己想要的操作。
5.Tuple:一次消息传递的基本单元。本来应该是一个key-value的map,但是由于各个组件间传递的tuple的字段名称已经事先定义好,
所以tuple中只要按序填入各个value就行了,所以就是一个value list.
6.Stream grouping:即消息的partition方法。Storm中提供若干种实用的grouping方式,包括shuffle, fields hash, all, global,
none, direct和localOrShuffle等,Stream Grouping定义了一个流在Bolt任务间该如何被切分。
7.Stream:源源不断传递的tuple就组成了stream。
1. 随机分组(Shuffle grouping):随机分发tuple到Bolt的任务,保证每个任务获得相等数量的tuple。
2. 字段分组(Fields grouping):根据指定字段分割数据流,并分组。例如,根据“user-id”字段,相同“user-id”的元组总是分发到同一个任务,不同“user-id”的元组可能分发到不同的任务。
3. 全部分组(All grouping):tuple被复制到bolt的所有任务。这种类型需要谨慎使用。
4. 全局分组(Global grouping):全部流都分配到bolt的同一个任务。明确地说,是分配给ID最小的那个task。
5. 无分组(None grouping):你不需要关心流是如何分组。目前,无分组等效于随机分组。但最终,Storm将把无分组的Bolts放到Bolts或Spouts订阅它们的同一线程去执行(如果可能)。
6. 直接分组(Direct grouping):这是一个特别的分组类型。元组生产者决定tuple由哪个元组处理者任务接收。
10.Storm流向整体结构图(重点):

1.Storm概述简介的更多相关文章
- storm 原理简介及单机版安装指南——详细版【转】
storm 原理简介及单机版安装指南 本文翻译自: https://github.com/nathanmarz/storm/wiki/Tutorial 原文链接自:http://www.open-op ...
- HealthKit开发快速入门教程之HealthKit开发概述简介
HealthKit开发快速入门教程之HealthKit开发概述简介 2014年6月2日召开的年度开发者大会上,苹果发布了一款新的移动应用平台,可以收集和分析用户的健康数据.该移动应用平台被命名为“He ...
- Storm具体解释一、Storm 概述
一.Storm概述 Storm是一个分布式的.可靠的.零失误的流式数据处理系统. 它的工作就是委派各种组件分别独立的处理一些简单任务.在Storm集群中处理输入流的是Spout组件,而Spo ...
- Storm(一)Storm的简介与相关概念
一.Storm的简介 官网地址:http://storm.apache.org/ Storm是一个免费开源.分布式.高容错的实时计算系统.Storm令持续不断的流计算变得容易,弥补了Hadoop批处理 ...
- Python运维开发基础-概述-简介
Python基础知识分为以下几块 1.Python概述 2.基础语法 3.数据结构 4.Python进阶 5.实训案例 一.Python概述 1.Python简介 2.Hello World 3.搭建 ...
- STP概述简介及生成树算法
目录: STP概述 STP简介 生成树算法 选择根网桥 选择根端口 选择指定端口 BPDU(桥协议数据单元) STP利用BPDU选择根网桥 STP的收敛 VLAN与STP关系 MSTP多生成树协议华为 ...
- Storm入门(十二)Twitter Storm: DRPC简介
作者: xumingming | 可以转载, 但必须以超链接形式标明文章原始出处和作者信息及版权声明网址: http://xumingming.sinaapp.com/756/twitter-stor ...
- Storm Windowing storm滑动窗口简介
Storm Windowing 简介 Storm可同时处理窗口内的所有tuple.窗口可以从时间或数量上来划分,由如下两个因素决定: 窗口的长度,可以是时间间隔或Tuple数量: 滑动间隔(slidi ...
- Storm简介
Storm特性 1. 低延迟和高性能 在一个小集群中,每个节点每秒可以处理数以百万计的消息. 2. 可扩展 在Storm集群中主要有三个实体:工作进程.线程和任务.Storm集群中每台机器上都可以运行 ...
随机推荐
- html设置多个div并排显示
我这里以4个div为例,html代码如下: <body> <div id="column1" style="background-color: blue ...
- git rev-parse介绍;获取commit id
git rev-parse master^{commit} 是什么意思 显示master提交的SHA1值 if you want to make sure that the output actual ...
- 生成count位随机数工具类
工具类 import java.util.Random; /** * 生成6位随机数字 */ public class GeneratorCode { /** * * @Title: getCode ...
- pip3 install pyinstaller 报错了的处理方法
http://www.pyinstaller.org/downloads.html 下载压缩包 解压到本地后,在目录处cmd 执行命令 python setup.py install 然后执行pip ...
- Andrew Ng机器学习课程14
Andrew Ng机器学习课程14 声明:引用请注明出处http://blog.csdn.net/lg1259156776/ 引言:主要介绍了当数据量不足,利用EM算法对混合高斯模型进行建模时数据量比 ...
- 在eNSP下使用Hybird接口
1.实验拓扑图 2.实验编址表 3.实验过程 按照拓扑图设置各个PC机的IP地址 双击PC1然后弹出对话框,依次设置主机名:PC1→IP地址:192.168.1.1→子网掩码:255.255.255. ...
- solr后台【web页面】增删改查
就是在下面这个页面操作 增加 {"id":"2", "name": "添加"} 查询 id:2 修改 {"id ...
- CNN-4: GoogLeNet 卷积神经网络模型
1.GoogLeNet 模型简介 GoogLeNet 是2014年Christian Szegedy提出的一种全新的深度学习结构,该模型获得了ImageNet挑战赛的冠军. 2.GoogLeNet 模 ...
- TypeScript 枚举
我们常常会有这样的场景,比如与后端开发约定订单的状态开始是0,未结账是1,运输中是2,运输完成是3,已收货是4.这样的纯数字会使得代码缺乏可读性.枚举就用于这样的场景.枚举可以让我们定义一些名字有意义 ...
- 新浪sae对storage的文档进行读写操作
有的人喜欢将一些数据写在服务器的文件里面,并不喜欢存在mysql里,但新浪sae却不支持对本地文件进行操作. 不过sae拓展了一个storage的服务,可以将一些静态文件放在上面.本文不介绍文件的上传 ...