Selenium结合BeautifulSoup4编写简单爬虫
在学会了抓包,接口请求(如requests库)和Selenium的一些操作方法后,基本上就可以编写爬虫,爬取绝大多数网站的内容。
在爬虫领域,Selenium永远是最后一道防线。从本质上来说,访问网页实际上就是一个接口请求。请求url后,返回的是网页的源代码。
我们只需要解析html或者通过正则匹配提取出我们需要的数据即可。
有些网站我们可以使用requests.get(url),得到的响应文本中获取到所有的数据。而有些网页数据是通过JS动态加载到页面中的。使用requests获取不到或者只能获取到一部分数据。
此时我们就可以使用selenium打开页面来,使用driver.page_source来获取JS执行完后的完整源代码。
例如,我们要爬取,diro官网女包的名称,价格,url,图片等数据,可以使用requests先获取到网页源代码:
访问网页,打开开发者工具,我们可以看到所有的商品都在一个
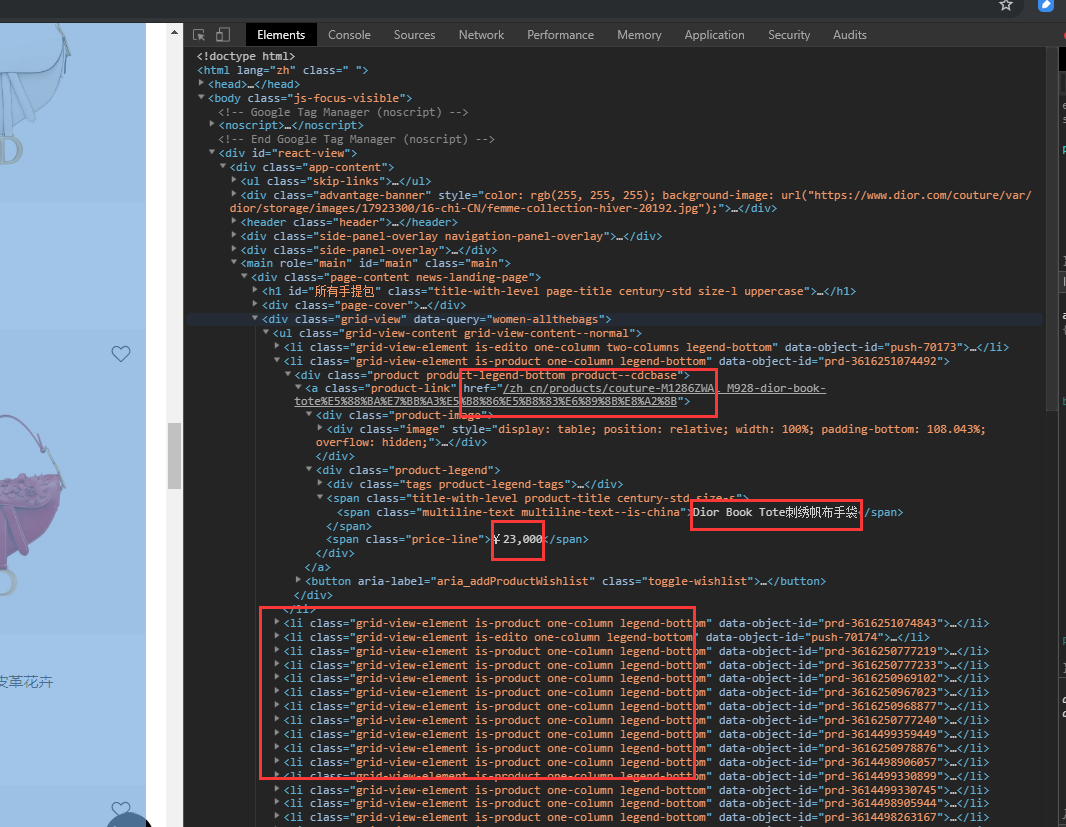
从html格式的源码中提取数据,有多种选择,可以使用xml.etree等等方式,bs4是一个比较方便易用的html解析库,配合lxml解析速度比较快。
bs4的使用方法为
from bs4 import BeautifulSoup
soup = BeautifulSoup(网页源代码字符串,'lxml')
soup.find(...).find(...)
soup.findall()
soup.select('css selector语法')
soup.find()可以通过节点属性进行查找,如,soup.find('div', id='节点id')或soup.find('li', class_='某个类名')或soup.find('标签名', 属性=属性值),当找到一个节点后,还可以使用这个节点继续在其子节点中查找。
soup.find_all()是查找多个,同样属性的节点,返回一个列表。
soup.select()是使用css selector语法查找,返回一个列表。
以下为示例代码:
from selenium import webdriver
from bs4 import BeautifulSoup
driver = webdriver.Chrome()
driver.get('https://www.dior.cn/zh_cn/女士精品/皮具系列/所有手提包')
soup = BeautifulSoup(driver.page_source, 'lxml')
products = soup.select('li.is-product')
for product in products:
name = product.find('span', class_='product-title').text.strip()
price = product.find('span', class_='price-line').text.replace('¥', '').replace(',','')
url = 'https://www.dior.cn' + product.find('a', class_='product-link').attrs['href']
img = product.find('img').attrs['src']
sku = img.split('/')[-1]
print(name, sku, price)
driver.quit()
运行结果,如下图:
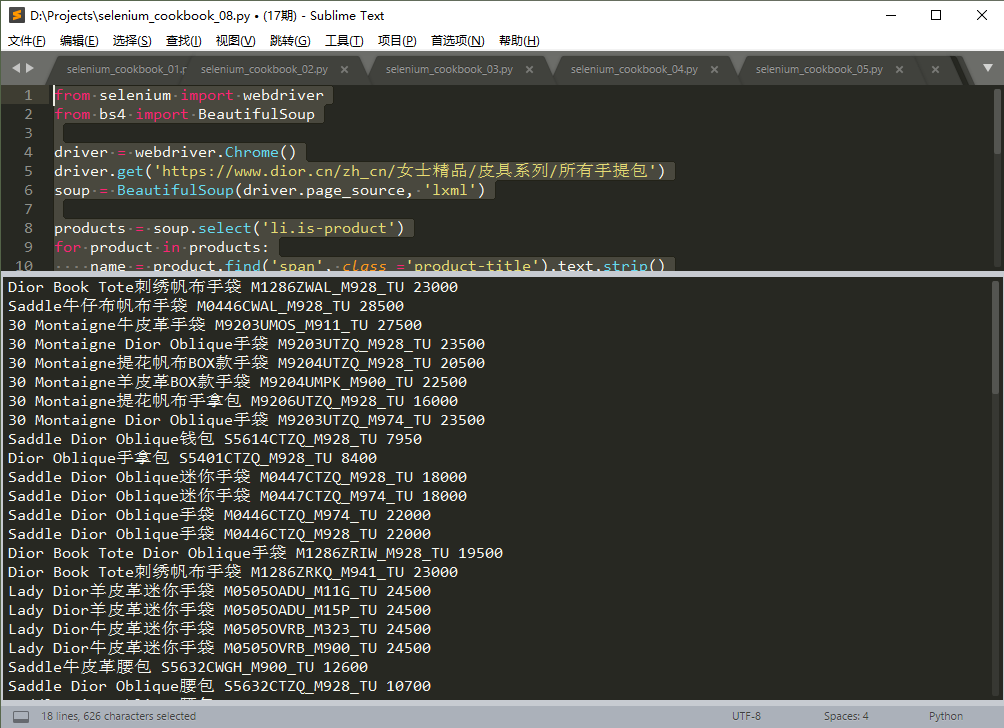
注:本例中,也可以使用requests.get()获取网页源代码,格式和使用selenium加载的稍有不同。
一般简单爬虫编写的步骤为:
- 进入列表页,打开开发者工具,刷新页面及向下滚动,查看新产品加载,是否能抓到XHR数据接口(直接返回JSON格式所有产品数据的接口)
- 如果有这种接口,尝试修改参数中的分页值,和请求总数值,看看是否能从一个接口返回所有的商品数据
- 如果只有Doc类型的接口返回页面,尝试使用requests.get()请求页面,分析响应文本,是否包含所有商品数据
- 如果requests获取不到商品数据或数据不全可以使用selenium加载页面,然后使用bs4解析提取,如果有多个页面,循环逐个操作即可。
Selenium结合BeautifulSoup4编写简单爬虫的更多相关文章
- 用python编写简单爬虫
需求:抓取百度百科python词条相关词条网页的标题和简介,并将数据输出在一个html表格中 入口页:python的百度词条页 https://baike.baidu.com/item/Python/ ...
- Python 利用Python编写简单网络爬虫实例3
利用Python编写简单网络爬虫实例3 by:授客 QQ:1033553122 实验环境 python版本:3.3.5(2.7下报错 实验目的 获取目标网站“http://bbs.51testing. ...
- Python 利用Python编写简单网络爬虫实例2
利用Python编写简单网络爬虫实例2 by:授客 QQ:1033553122 实验环境 python版本:3.3.5(2.7下报错 实验目的 获取目标网站“http://www.51testing. ...
- 在python3中使用urllib.request编写简单的网络爬虫
转自:http://www.cnblogs.com/ArsenalfanInECNU/p/4780883.html Python官方提供了用于编写网络爬虫的包 urllib.request, 我们主要 ...
- Python开发简单爬虫
简单爬虫框架: 爬虫调度器 -> URL管理器 -> 网页下载器(urllib2) -> 网页解析器(BeautifulSoup) -> 价值数据 Demo1: # codin ...
- python3实现简单爬虫功能
本文参考虫师python2实现简单爬虫功能,并增加自己的感悟. #coding=utf-8 import re import urllib.request def getHtml(url): page ...
- Python开发简单爬虫 - 慕课网
课程链接:Python开发简单爬虫 环境搭建: Eclipse+PyDev配置搭建Python开发环境 Python入门基础教程 用Eclipse编写Python程序 课程目录 第1章 课程介绍 ...
- Python开发简单爬虫(一)
一 .简单爬虫架构: 爬虫调度端:启动爬虫,停止爬虫,监视爬虫运行情况 URL管理器:对将要爬取的和已经爬取过的URL进行管理:可取出带爬取的URL,将其传送给“网页下载器” 网页下载器:将URL指定 ...
- 用python语言编写网络爬虫
本文主要用到python3自带的urllib模块编写轻量级的简单爬虫.至于怎么定位一个网页中具体元素的url可自行百度火狐浏览器的firebug插件或者谷歌浏览器的自带方法. 1.访问一个网址 re= ...
随机推荐
- WebSocket协议探究(二)
一 复习和目标 1 复习 协议概述: WebSocket内置消息定界并且全双工通信 WebSocket使用HTTP进行协议协商,协商成功使用TCP连接进行传输数据 WebScoket数据格式支持二进制 ...
- Asp.Net Core 轻松学系列-1阅读指引目录
https://www.cnblogs.com/viter/p/10474091.html 目录 前言 1. 从安装到配置 2. 业务实现 3. 日志 4. 测试 5. 缓存使用 6.网络和通讯 7. ...
- ARM微控制器与嵌入式系统
个牛人在ARM实现嵌入式系统的过程 第一章 概览 1.1课程概览 认识ARM嵌入式系统(什么是ARM?什么是嵌入式系统?) 备战智能车 在科技活动中玩起来 积累计算机.电路基础知识 1.2如何学好嵌 ...
- html 输入框ios苹果手机显示九宫格数字键盘
只需要在input标签加上type=‘tel’ 即可
- MUI底部导航栏切换效果
首先是html代码: <nav class="mui-bar mui-bar-tab"> <a href="view/templates/home/ho ...
- ubuntu创建kvm虚拟机
CPU虚拟化支持 [root@ubuntu~]# egrep -o '(vmx|svm)' /proc/cpuinfo vmx vmx vmx vmx KVM环境 [root@ubuntu ~]# a ...
- linux三剑客grep,sed,awk
grep 官方帮助文档 Usage: grep [OPTION]... PATTERN [FILE]... Search for PATTERN in each FILE or standard in ...
- 主板(motherboard)
若转载请于明显处标明出处:http://www.cnblogs.com/kelamoyujuzhen/p/8979262.html 整台PC都是围绕主板(motherboard)构建的,它是PC中最重 ...
- 用arduino的uno开发板为nano板子烧写bootloader
这篇文章,是为了记录下某宝上淘到的一个没有bootloader的nano开发板的历程(比较坑),自己搜索资料而记录的. 如果没有bootloader,板子就不能接收上传的程序,什么也干不了. 烧写bo ...
- Linux 01 Liunx系统简介
Linux是一套免费使用和自由传播的类Unix操作系统,是一个基于POSIX和UNIX的多用户.多任务.支持多线程和多CPU的操作系统.它能运行主要的UNIX工具软件.应用程序和网络协议.它支持32位 ...