(十二)mybatis 查询缓存
目录
什么是查询缓存
mybatis 在查询数据的时候,会将数据存储起来,下次再次查询相同的数据,就不会再去查询数据库,而是直接从 缓存 中查询 ;
这样达到,减轻服务器压力,提高响应 ;
mybatis 提供 一级缓存 、二级缓存 ;
图解查询缓存
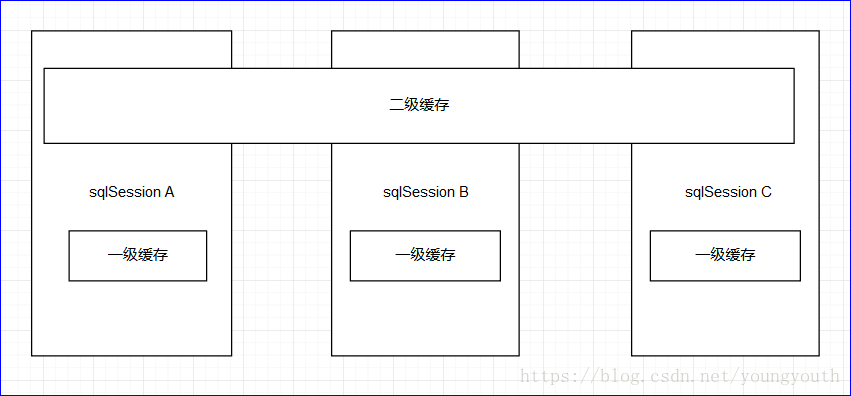
一级缓存
mybatis在操作数据库的时候,会先创建sqlsession,用sqlsession去操作数据库 ;在每个
sqlsession中,都有一个数据结构(hashmap),用于存储缓存,在不同的sqlsession之间,它们是相互不影响的 ;存储在这些
sqlsession对象内部的缓存,就是一级缓存;hashmap的key格式是 :查询到的对象的哈希码:satement 的 id:、、: 参数;value是查询到的对象 ;二级缓存
当多个不同的
sqlsession对象,去使用同一个mapper映射关系文件中的sql语句,也会产生缓存,这个缓存是跨sqlsession的,凡是使用同一个mapper映射关系文件中的sql语句的sqlsession对象都是共享这个缓存的 ;缓存的底层也是
hashMap;
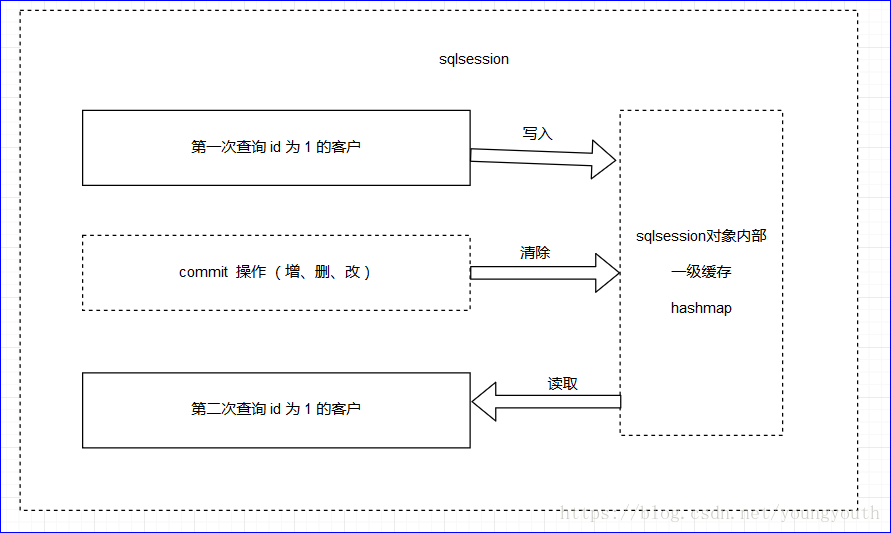
一级缓存
原理每次查询,会先去缓存中,检查要查询的数据,在缓存中有没有,如果有,则直接拿缓存中的数据 ;
如果缓存中没有的话,才去查询数据库,并将查询到的数据写入缓存 ;
如果执行过
commit操作,则会清空全部缓存,因为,commit会对数据库数据进行修改,因此清空缓存,使得下次查询必须经过数据库,也就是保证数据库的缓存必须是最新的数据 ;图示
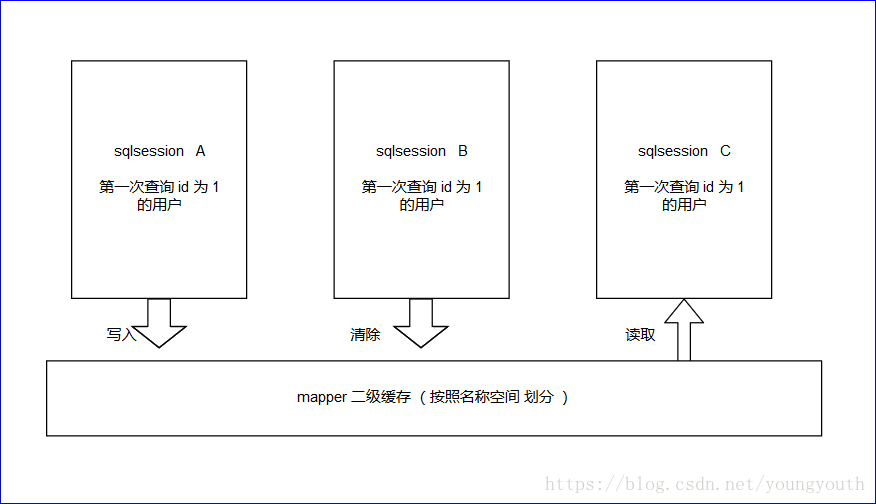
二级缓存
原理当我们开启
二级缓存的时候(默认就是开启的),查询数据的时候,是先去一级缓存找,没有的话,再去二级缓存中找,都没有的话,才会去查询数据库 ;当从数据库查询到信息以后,首先将查询到的数据存进
一级缓存中,然后当sqlsession关闭以后,sqlsession中的一级缓存,才会被写入二级缓存;如果
sqlsession执行了commit操作了,也会清空二级缓存;图示注意:图中有2个地方被我画错了,复制第一个图 ,忘记修改了!!!我也不想重画了
sqlsession B不应该是查询,应该是进行commit操作 ;pojo必须实现序列化接口因为,我们的二级缓存的
hashmap的 值 是查询到的pojo对象,而我们有时候二级缓存,并不是保存到 内存 中的,可能保存到 硬盘 上,这样就可以反序列化;因此,使用
二级缓存那么pojo类必须实现序列化接口 ;注意点二级缓存,是按照mapper文件的命名空间划分的 ,只要命名空间相同,则公用一份二级缓存;最后只要
log文件中出现命中率,就代表二级缓存开始使用了 ;命中率:
Cache Hit Ratio [xin.ijava.dao.UserMapper]: 0.3333333333333333
禁用二级缓存
select 标签中配置 useCache 属性,其默认值是 true ,将其值设为 false ,就会禁用 二级缓存 了
刷新缓存
mybatis 的 刷新缓存,就是直接 清空缓存 ,默认值是 true ,我们可以设置 commit 操作的属性 flushCache的值为 false 让其不刷新缓存,一般不会这样做;
二级缓存应用场景
某信息,不经常变化,其用户对该信息实时性要求不高,这时候,可以使用二级缓存 ;
比如:电话账单 ;
用户要想查询 前一天、前一个月 的电话账单,电话账单一旦产生,基本就不会再变了,除非用户删除某条通话记录 ;
并且一般,对电话账单的实时性要求也不高,基本为 0 ,营业厅给我们提供查什么时候的电话账单,我们就去查什么时候的;
比如,人家就提供了,查询前一天的电话账单,那么,我们想查今天的,只能等到明天再查今天的 ;
对于这样的信息,我们就可以使用 mybatis 的 二级缓存 了,并且在开启具体 mapper 的 二级缓存 的时候,配置刷新频率 flushInterval ;
刷新频率的时候根据需求而定,这里,人家提供查询前一天的数据,那么,我们的刷新频率,就设为 一天;这样,当我们想查询昨天的电话账单的时候,也就第一次需要去查数据库,然后,今天的任意时候,再去查询,都是直接拿 二级缓存 ;
等到明天的时候,我们设定的刷新频率 就会自动刷新缓存,因为,之前的缓存已经没用了,现在查询前一天的数据,应该是今天的数据 ;
二级缓存局限性
其实 mybatis 的二级缓存,应用的应该不广泛 ;它有很大的局限性 ;
比如,我们缓存中已经缓存了 10000 商品价格的记录,这样 ,当这一万条商品再被访问时,就不再去查询数据库了;
但是,只要这一万条里面的任意一条商品记录发生变化,那么 剩下的 9999 条记录,都会被一并刷新掉,这样,导致命中率很低;
也就是对 细粒度 的缓存很不友好,即想要具体到某一条改变了,只刷新改变的这一条记录的缓存,留下其他的没更改的数据缓存,mybatis 是做不到的,原因在于 mybatis 自己的缓存策略,只要其中一个 sqlsession 进行 commit ,即刷新缓存 ;
对于这样的问题,我们需要在 services 自己写逻辑进行完成,也就是所谓的 三级缓存 ;
(十二)mybatis 查询缓存的更多相关文章
- (十二)数据库查询处理之Query Execution(1)
(十二)数据库查询处理之Query Execution(1) 1. 写在前面 这一大部分就是为了Lab3做准备的 每一个query plan都要实现一个next函数和一个init函数 对于next函数 ...
- Mybatis学习记录(七)----Mybatis查询缓存
1. 什么是查询缓存 mybatis提供查询缓存,用于减轻数据压力,提高数据库性能. mybaits提供一级缓存,和二级缓存. 一级缓存是SqlSession级别的缓存.在操作数据库时需要构造 sql ...
- 八 mybatis查询缓存(一级缓存,二级缓存)和ehcache整合
1 查询缓存 1.1 什么是查询缓存 mybatis提供查询缓存,用于减轻数据压力,提高数据库性能. mybaits提供一级缓存,和二级缓存.
- mybatis查询缓存——(十三)
1. mybatis缓存介绍 如下图,是mybatis一级缓存和二级缓存的区别图解: mybatis提供查询缓存,用于减轻数据压力,提高数据库性能. mybaits提供一级缓存,和二级缓存.
- (十)mybatis之缓存
一.缓存的意义 将用户经常查询的数据放在缓存(内存)中,用户去查询数据就不用从磁盘上(关系型数据库数据文件)去查询,从缓存中进行查询,从而提高查询效率,解决了高并发系统的性能问题. 二.mybatis ...
- Spring+SpringMVC+MyBatis深入学习及搭建(八)——MyBatis查询缓存
转载请注明出处:http://www.cnblogs.com/Joanna-Yan/p/6956206.html 前面讲到:Spring+SpringMVC+MyBatis深入学习及搭建(七)——My ...
- apache ignite系列(九):使用ddl和dml脚本初始化ignite并使用mybatis查询缓存
博客又断了一段时间,本篇将记录一下基于ignite对jdbc支持的特性在实际使用过程中的使用. 使用ddl和dml脚本初始化ignite 由于spring-boot中支持通过spring.dataso ...
- 让EFCore更疯狂些的扩展类库(二):查询缓存、分部sql、表名替换的策略配置
前言 上一篇介绍了扩展类库的功能简介,通过json文件配置sql语句 和 sql语句的直接执行,这篇开始说明sql配置的策略模块:策略管理器与各种策略的配置. 类库源码:github:https:// ...
- mybatis 查询缓存问题
<settings> <setting name="localCacheScope" value="STATEMENT" /> < ...
随机推荐
- 系统信息的管理函数API
1.Windows系统信息 1.1获取系统版本: BOOL WINAPI GetVersionEx( __in_out LPOSVERSIONINFO lpVersionInfo ); lpVer ...
- oc Learning Blog
http://www.cnblogs.com/heyonggang/p/3351269.html M了个J :http://www.cnblogs.com/mjios/tag/objective-c/ ...
- UVA 11605 Lights inside a 3d Grid —— (概率和期望)
题意:见大白书P181. 分析:一个一个点的进行分析,取其期望然后求和即可.假设当前点在第一次中被选到的概率为p,f[i]表示进行k次以后该点亮的概率(在这里也可以理解为期望),g[i]表示k次后该点 ...
- html 刷新更新背景图
需求:每次刷新页面,随机获取背景图 实现方式: 1 通过js动态生成标签 <body> <script type="text/javascript"> va ...
- macOS Mojave 10.14 无法安装brew缺少Command Line Tools for Xcode的解决办法
问题描述: 首先我的版本是 Xcode 10.1 如果按照以前的方法安装brew 复制 1 /usr/bin/ruby -e "$(curl -fsSL https://raw.github ...
- 重读APUE(15)-pthread_cond_wait与while循环
即使pthead_cond_wait()和pthread_cond_timewait()没有错误返回,等待的条件也可能是假的:即使pthread_cond_timewait()返回了超时错误,关联的条 ...
- SpringMVC返回Map类型转换成JSON失败
错误信息:WARN DefaultHandlerExceptionResolver:380 - Failed to write HTTP message: org.springframework.ht ...
- Linux 操作memcache命令行
telnet 127.0.0.1 11211 连接 memcache stats 查看 memcache 状态 状态说明: pid memcache服务器的进程ID uptime 服务器已经运行的秒数 ...
- vue单页面项目架构方案
这里的架构方案是基于vue-cli2生成的项目应用程序产生的,是对项目应用程序或者项目模板的一些方便开发和维护的封装.针对单页面的解决方案. 主要有四个方面: 一,不同环境下的分别打包 主要是测试环境 ...
- Mapper抽象类参数
Mapper< Object, Text, Text, IntWritable> Mapper< Text, Text, Text, Text> Mapper< Text ...