Transformer详解
0 简述
Transformer改进了RNN最被人诟病的训练慢的缺点,利用self-attention机制实现快速并行。
并且Transformer可以增加到非常深的深度,充分发掘DNN模型的特性,提升模型准确率。
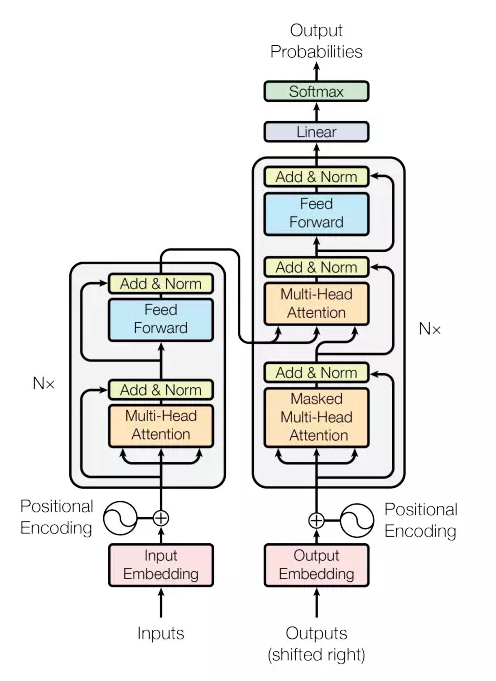
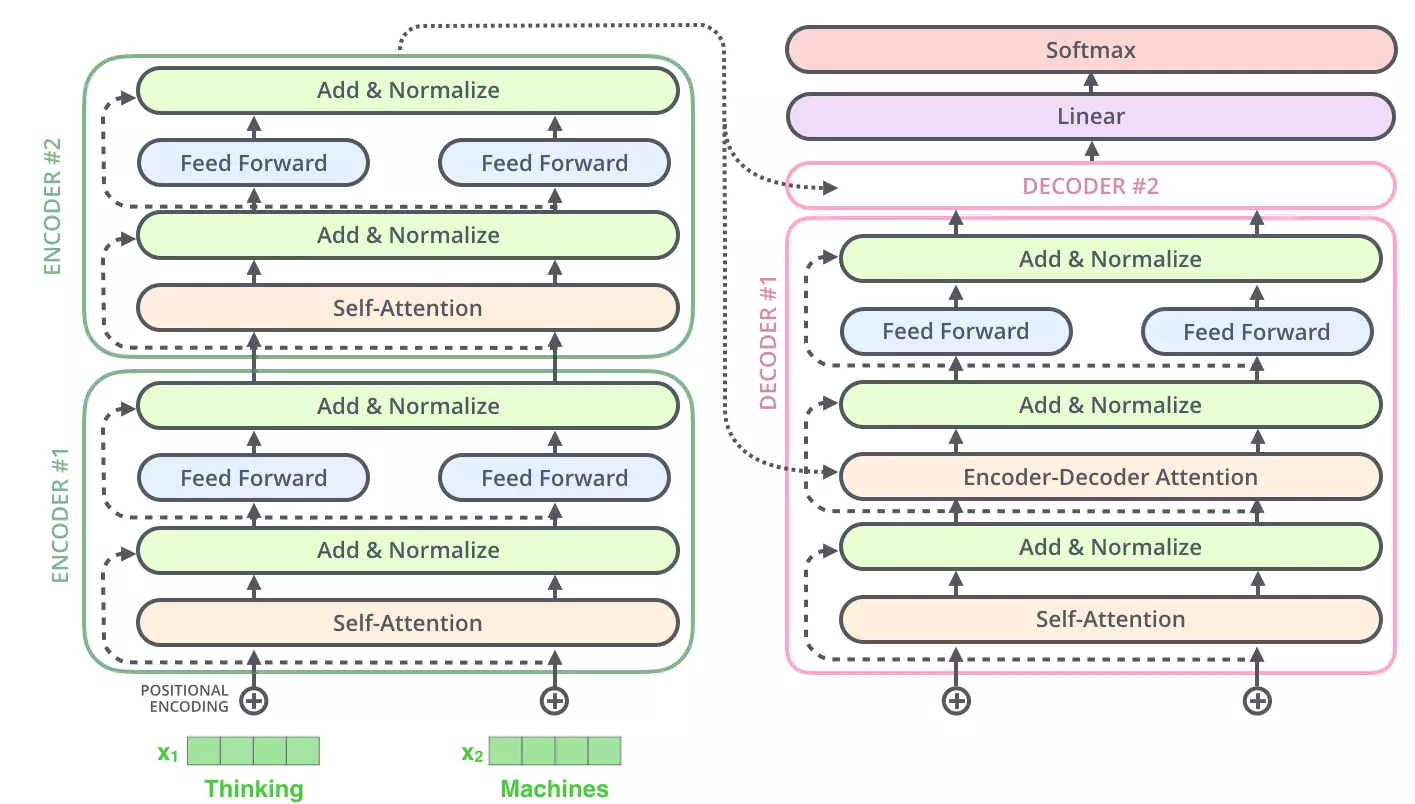
编码组件部分由一堆编码器(encoder)构成(论文中是将6个编码器叠在一起——数字没有什么神奇之处,你也可以尝试其他数字)。解码组件部分也是由相同数量(与编码器对应)的解码器(decoder)组成的。
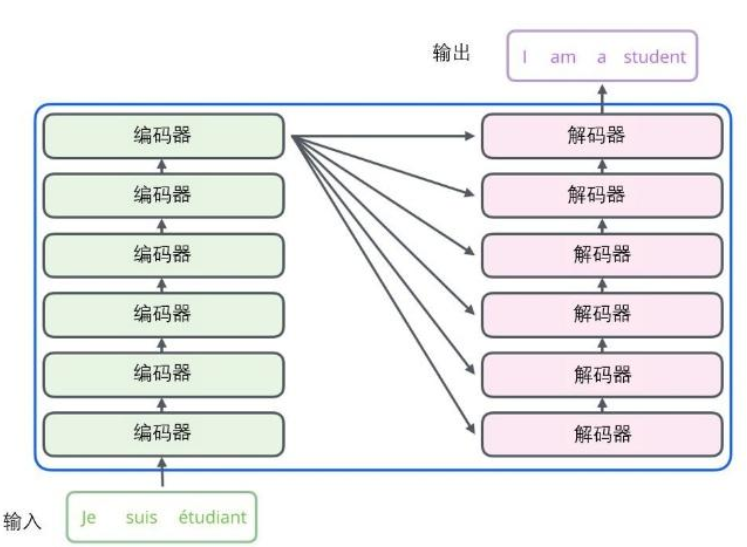
1 编码器
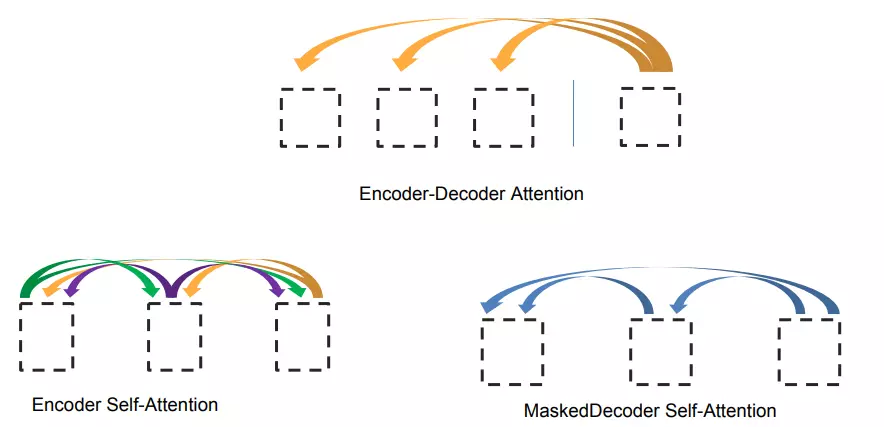
所有的编码器在结构上都是相同的,但它们没有共享参数。每个编码器都可以分解成两个子层。
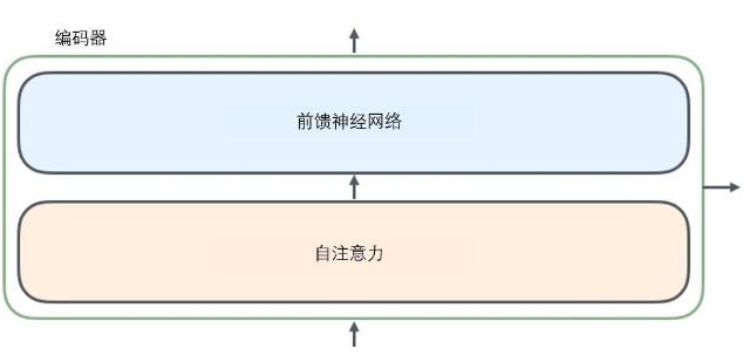
从编码器输入的句子首先会经过一个自注意力(self-attention)层,这层帮助编码器在对每个单词编码时关注输入句子的其他单词。自注意力层的输出会传递到前馈(feed-forward)神经网络中。每个位置的单词对应的前馈神经网络都完全一样(注:一层窗口为一个单词的一维卷积神经网络)。
在这里输入序列中每个位置的单词都有自己独特的路径流入编码器。在自注意力层中,这些路径之间存在依赖关系。而前馈(feed-forward)层没有这些依赖关系。因此在前馈(feed-forward)层时可以并行执行各种路径。
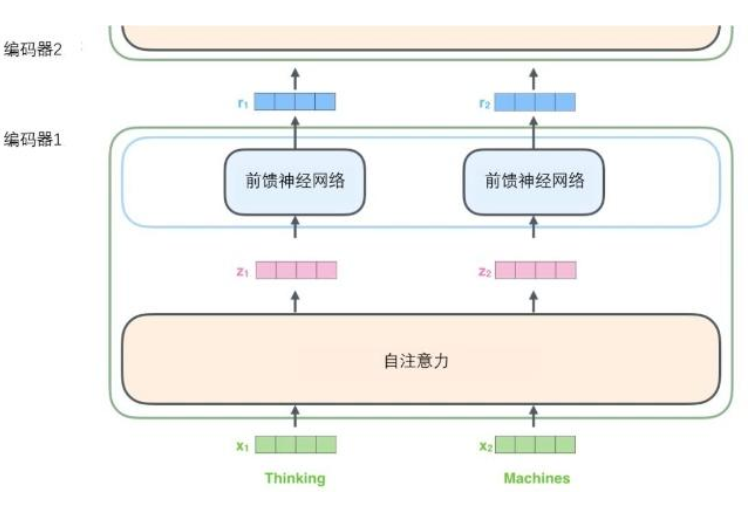
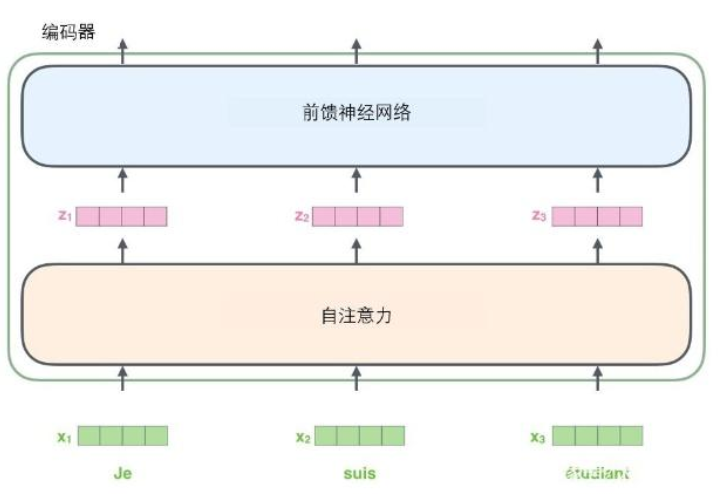
个编码器接收向量列表作为输入,接着将向量列表中的向量传递到自注意力层进行处理,然后传递到前馈神经网络层中,将输出结果传递到下一个编码器中。
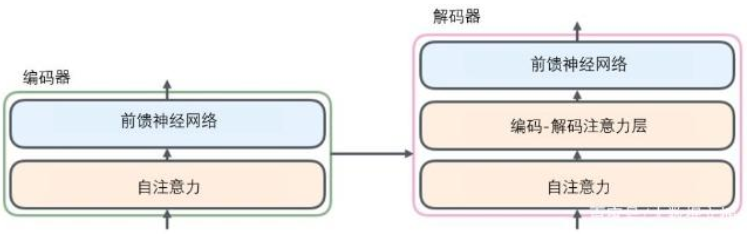
2 解码器
解码器中也有编码器的自注意力(self-attention)层和前馈(feed-forward)层。除此之外,这两个层之间还有一个注意力层,用来关注输入句子的相关部分(和seq2seq模型的注意力作用相似)。
3 自注意力机制
例如,下列句子是我们想要翻译的输入句子:
The animal didn't cross the street because it was too tired
这个“it”在这个句子是指什么呢?它指的是street还是这个animal呢?
当模型处理这个单词“it”的时候,自注意力机制会允许“it”与“animal”建立联系。
随着模型处理输入序列的每个单词,自注意力会关注整个输入序列的所有单词,帮助模型对本单词更好地进行编码。
RNN会将它已经处理过的前面的所有单词/向量的表示与它正在处理的当前单词/向量结合起来。而自注意力机制会将所有相关单词的理解融入到我们正在处理的单词中。

当我们在编码器#5(栈中最上层编码器)中编码“it”这个单词的时,注意力机制的部分会去关注“The Animal”,将它的表示的一部分编入“it”的编码中。
请务必注意Tensor2Tensor notebook ,在里面你可以下载一个Transformer模型,并用交互式可视化的方式来检验。
如何计算?
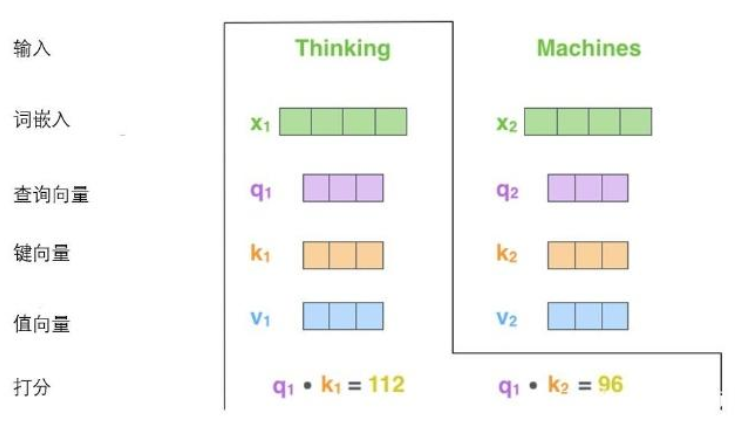
第一步
从每个编码器的输入向量(每个单词的词向量)中生成三个向量。也就是说对于每个单词,我们创造一个查询向量、一个键向量和一个值向量。这三个向量是通过词嵌入与三个权重矩阵后相乘创建的。
这些新向量维度是64,词嵌入和编码器的输入/输出向量的维度是512。
X1与WQ权重矩阵相乘得到q1, 就是与这个单词相关的查询向量。最终使得输入序列的每个单词的创建一个查询向量、一个键向量和一个值向量。
第二步
计算得分。假设我们在为这个例子中的第一个词“Thinking”计算自注意力向量,我们需要拿输入句子中的每个单词对“Thinking”打分。这些分数决定了在编码单词“Thinking”的过程中有多重视句子的其它部分。
这些分数是通过打分单词(所有输入句子的单词)的键向量与“Thinking”的查询向量相点积来计算的。所以如果我们是处理位置最靠前的词的自注意力的话,第一个分数是q1和k1的点积,第二个分数是q1和k2的点积。(打分单词包括它本身)
第三步和第四步
将分数除以8(8是论文中使用的键向量的维数64的平方根,这会让梯度更稳定。这里也可以使用其它值,8只是默认值),然后通过softmax传递结果。softmax的作用是使所有单词的分数归一化,得到的分数都是正值且和为1。
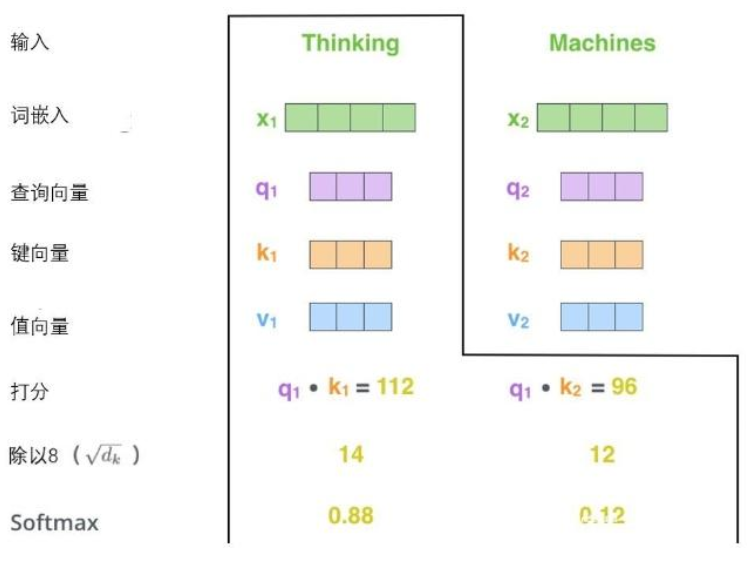
这个softmax分数决定了每个单词对编码当下位置(“Thinking”)的贡献。显然,已经在这个位置上的单词将获得最高的softmax分数,但有时关注另一个与当前单词相关的单词也会有帮助。
第五步
将每个值向量乘以softmax分数(这是为了准备之后将它们求和)。这里的直觉是希望关注语义上相关的单词,并弱化不相关的单词(例如,让它们乘以0.001这样的小数)。
第六步
对加权值向量求和(注:自注意力的另一种解释就是在编码某个单词时,就是将所有单词的表示(值向量)进行加权求和,而权重是通过该词的表示(键向量)与被编码词表示(查询向量)的点积并通过softmax得到。),然后即得到自注意力层在该位置的输出(在我们的例子中是对于第一个单词)。
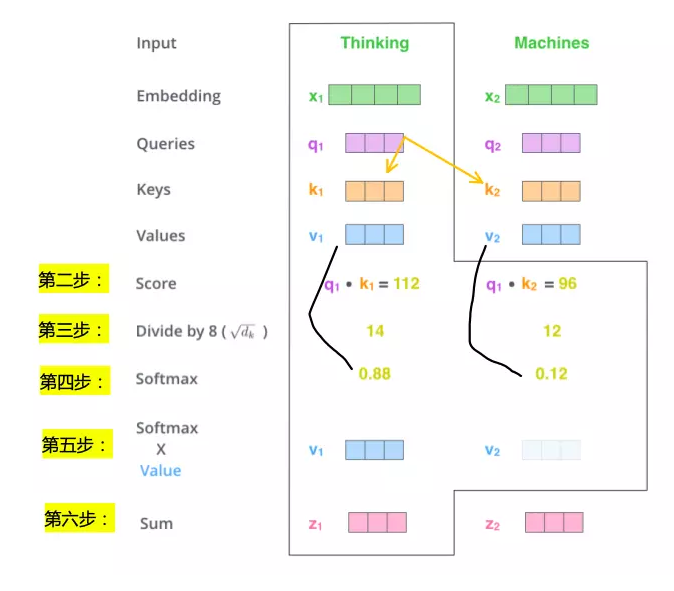
这样自自注意力的计算就完成了。得到的向量就可以传给前馈神经网络。然而实际中,这些计算是以矩阵形式完成的,以便算得更快。那我们接下来就看看如何用矩阵实现的。
4 通过矩阵运算实现自注意力机制
第一步是计算查询矩阵、键矩阵和值矩阵。为此,我们将将输入句子的词嵌入装进矩阵X中,将其乘以我们训练的权重矩阵(WQ,WK,WV)。
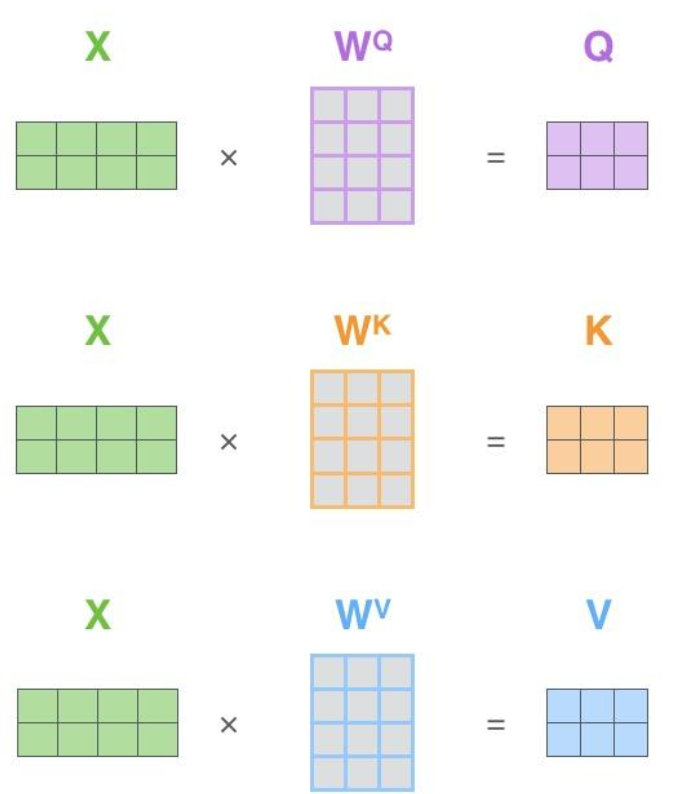
x矩阵中的每一行对应于输入句子中的一个单词。我们再次看到词嵌入向量 (512,或图中的4个格子)和q/k/v向量(64,或图中的3个格子)的大小差异。
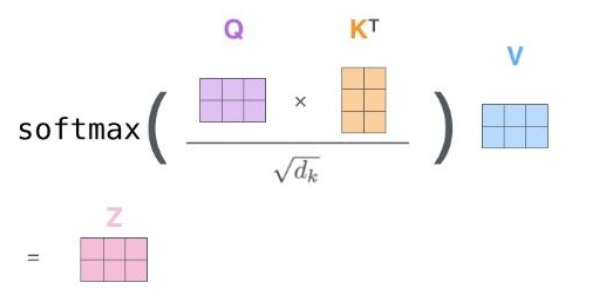
最后,由于我们处理的是矩阵,我们可以将步骤2到步骤6合并为一个公式来计算自注意力层的输出。
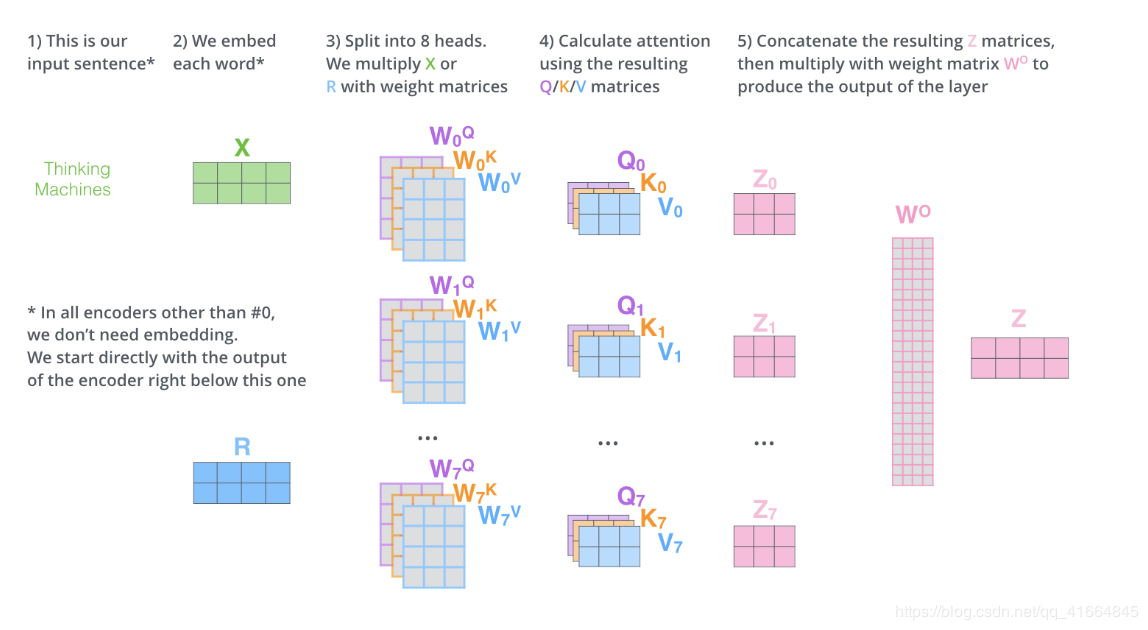
5 “多头”注意力
通过增加一种叫做“多头”注意力(“multi-headed” attention)的机制,论文进一步完善了自注意力层,并在两方面提高了注意力层的性能:
1.它扩展了模型专注于不同位置的能力。在上面的例子中,虽然每个编码都在z1中有或多或少的体现,但是它可能被实际的单词本身所支配。如果我们翻译一个句子,比如“The animal didn’t cross the street because it was too tired”,我们会想知道“it”指的是哪个词,这时模型的“多头”注意机制会起到作用。
2.它给出了注意力层的多个“表示子空间”(representation subspaces)。接下来我们将看到,对于“多头”注意机制,我们有多个查询/键/值权重矩阵集(Transformer使用八个注意力头,因此我们对于每个编码器/解码器有八个矩阵集合)。这些集合中的每一个都是随机初始化的,在训练之后,每个集合都被用来将输入词嵌入(或来自较低编码器/解码器的向量)投影到不同的表示子空间中。
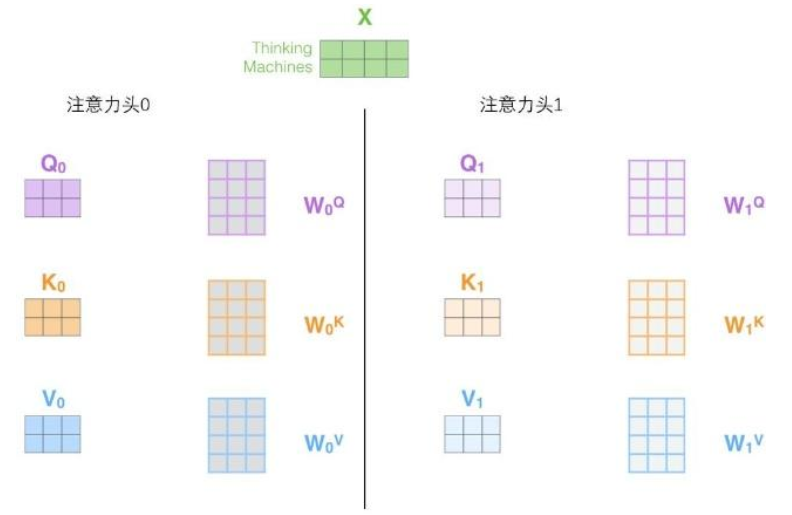
在“多头”注意机制下,我们为每个头保持独立的查询/键/值权重矩阵,从而产生不同的查询/键/值矩阵。和之前一样,我们拿X乘以WQ/WK/WV矩阵来产生查询/键/值矩阵。
如果我们做与上述相同的自注意力计算,只需八次不同的权重矩阵运算,我们就会得到八个不同的Z矩阵。
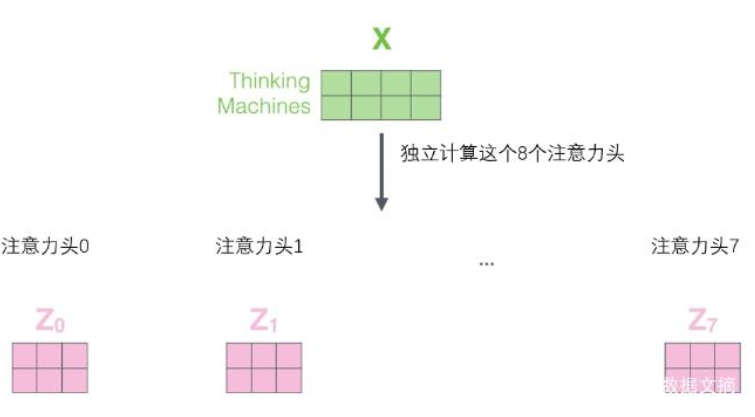
给前馈层之前,需要一种方法把这八个矩阵压缩成一个矩阵。那该怎么做?其实可以直接把这些矩阵拼接在一起,然后用一个附加的权重矩阵WO与它们相乘。

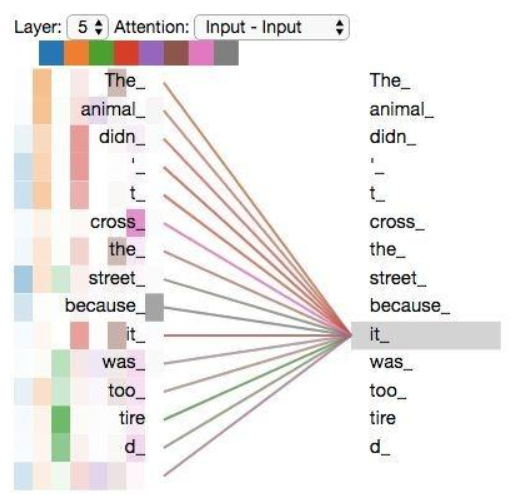
重温之前的例子,看看我们在例句中编码“it”一词时,不同的注意力“头”集中在哪里:
当我们编码“it”一词时,一个注意力头集中在“animal”上,而另一个则集中在“tired”上,从某种意义上说,模型对“it”一词的表达在某种程度上是“animal”和“tired”的代表。
然而,如果我们把所有的attention都加到图示里,事情就更难解释了:
整理以上流程:
6 位置编码
Transformer为每个输入的词嵌入添加了一个向量。这些向量遵循模型学习到的特定模式,这有助于确定每个单词的位置,或序列中不同单词之间的距离。这里的直觉是,将位置向量添加到词嵌入中使得它们在接下来的运算中,能够更好地表达的词与词之间的距离。
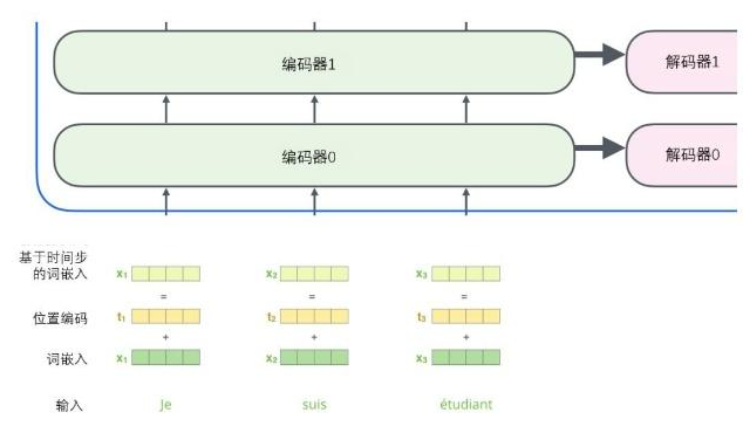
假设词嵌入的维数为4,则实际的位置编码如下:
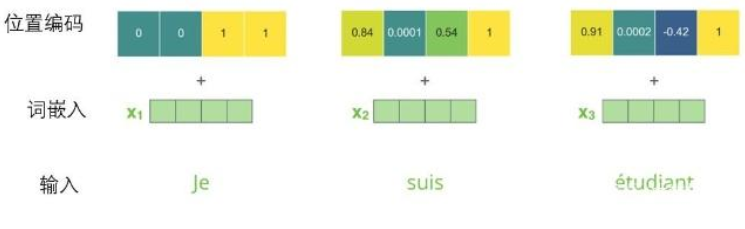
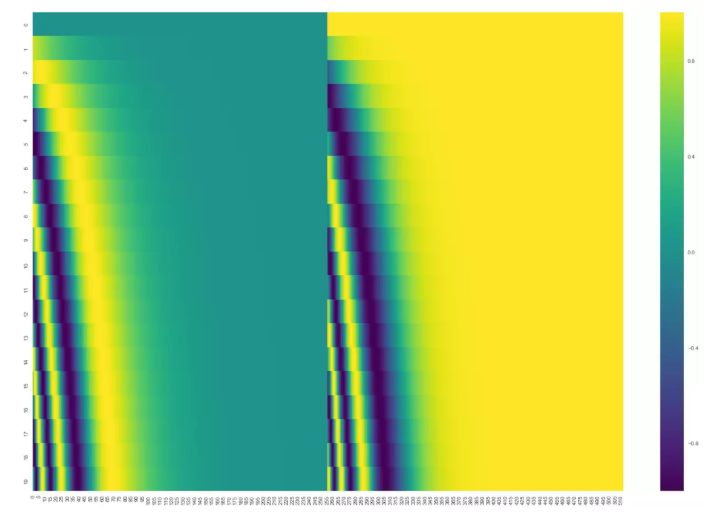
可以看到在中心位置分成了两半,因为左半部分的值由一个正弦函数生成,右半部分由余弦函数生成,然后将它们连接起来形成了每个位置的编码向量。
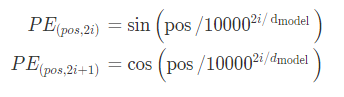
当然这并不是位置编码的唯一方法,只是这个方法能够扩展到看不见的序列长度处,例如当我们要翻译一个句子,这个句子的长度比我们训练集中的任何一个句子都长时。(因为三角公式不受序列长度的限制,也就是可以对 比所遇到序列的更长的序列 进行表示。)
7 残差
在每个编码器中的每个子层(自注意力、前馈网络)的周围都有一个残差连接(求和:+x),并且都跟随着一个“层-归一化”步骤。
Add & Norm模块接在Encoder端和Decoder端每个子模块的后面,其中Add表示残差连接,Norm表示LayerNorm。
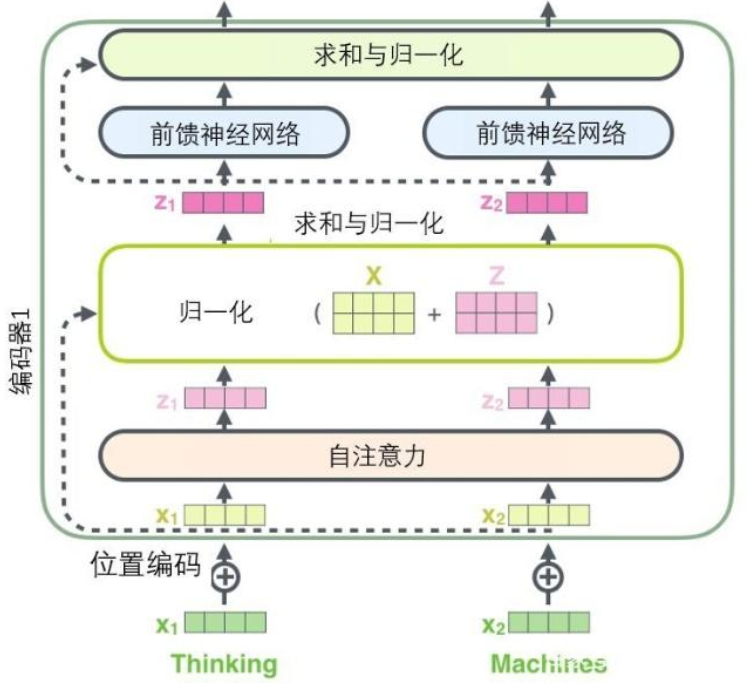
解码器的子层也是这样的。如果我们想象一个2 层编码-解码结构的transformer,它看起来会像下面这张图一样:
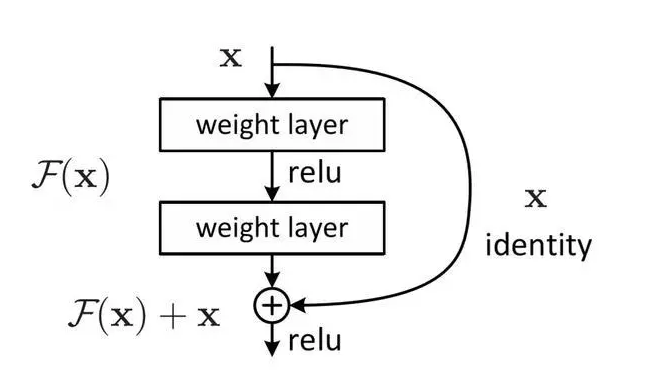
可以看到X是这一层残差块的输入,也称作F(x)为残差,x为输入值,F(X)是经过第一层线性变化并激活后的输出,该图表示在残差网络中,第二层进行线性变化之后激活之前,F(x)加入了这一层输入值X,然后再进行激活后输出。在第二层输出值激活前加入X,这条路径称作shortcut连接。
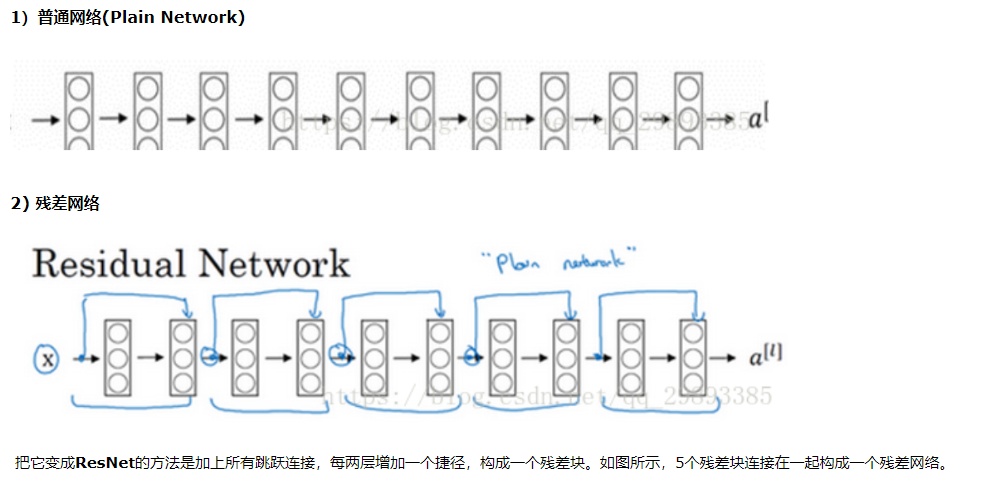
8 解码组件补充
- 如上图所示,也有 positional encodings,Multi-head attention 和 FFN,子层之间也要做残差连接,
- 但比 encoder 多了一个 Masked Multi-head attention,
- 最后要经过 Linear 和 softmax 输出概率。
这些向量会用于每个 decoder 的 encoder-decoder attention 层,有助于解码器聚焦在输入序列中的合适位置
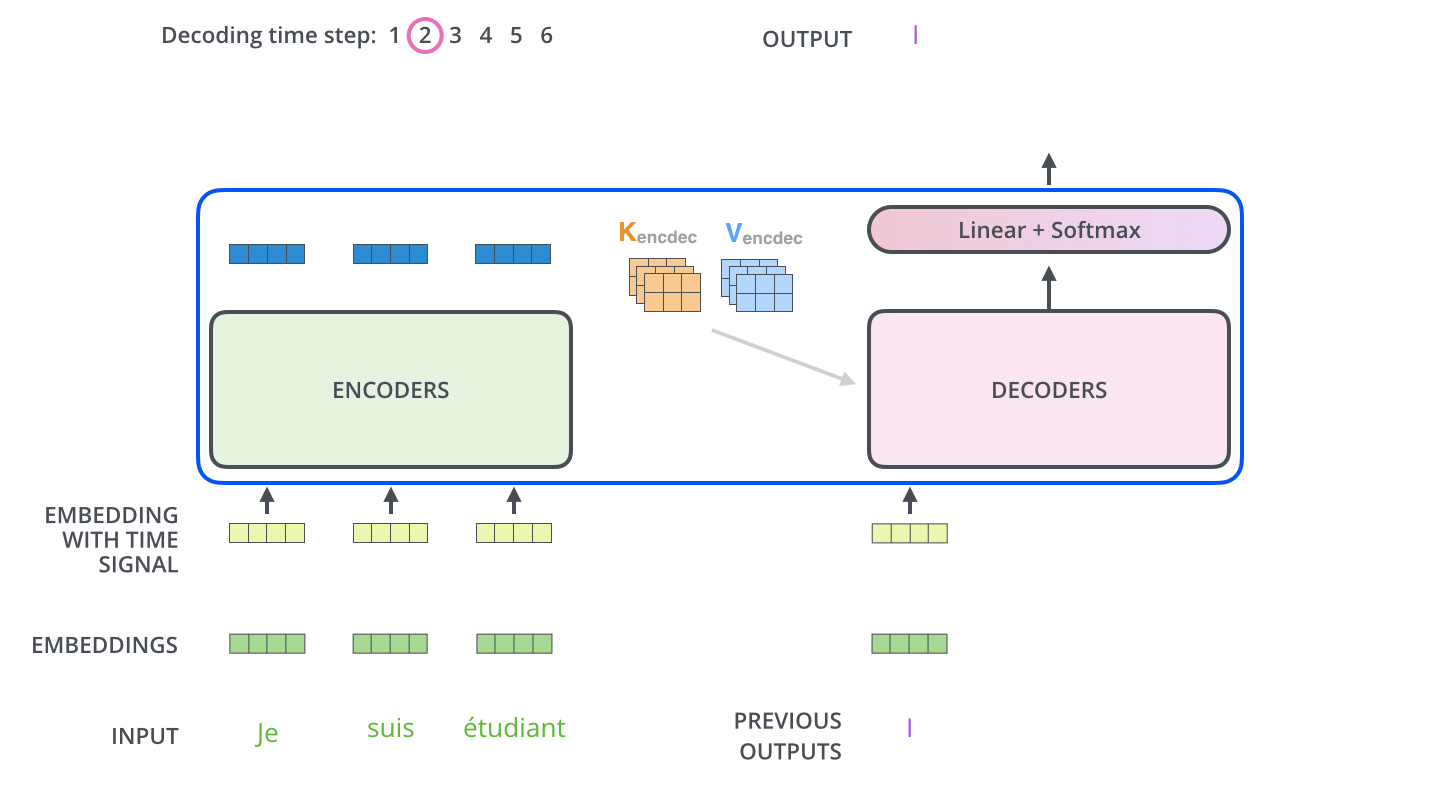
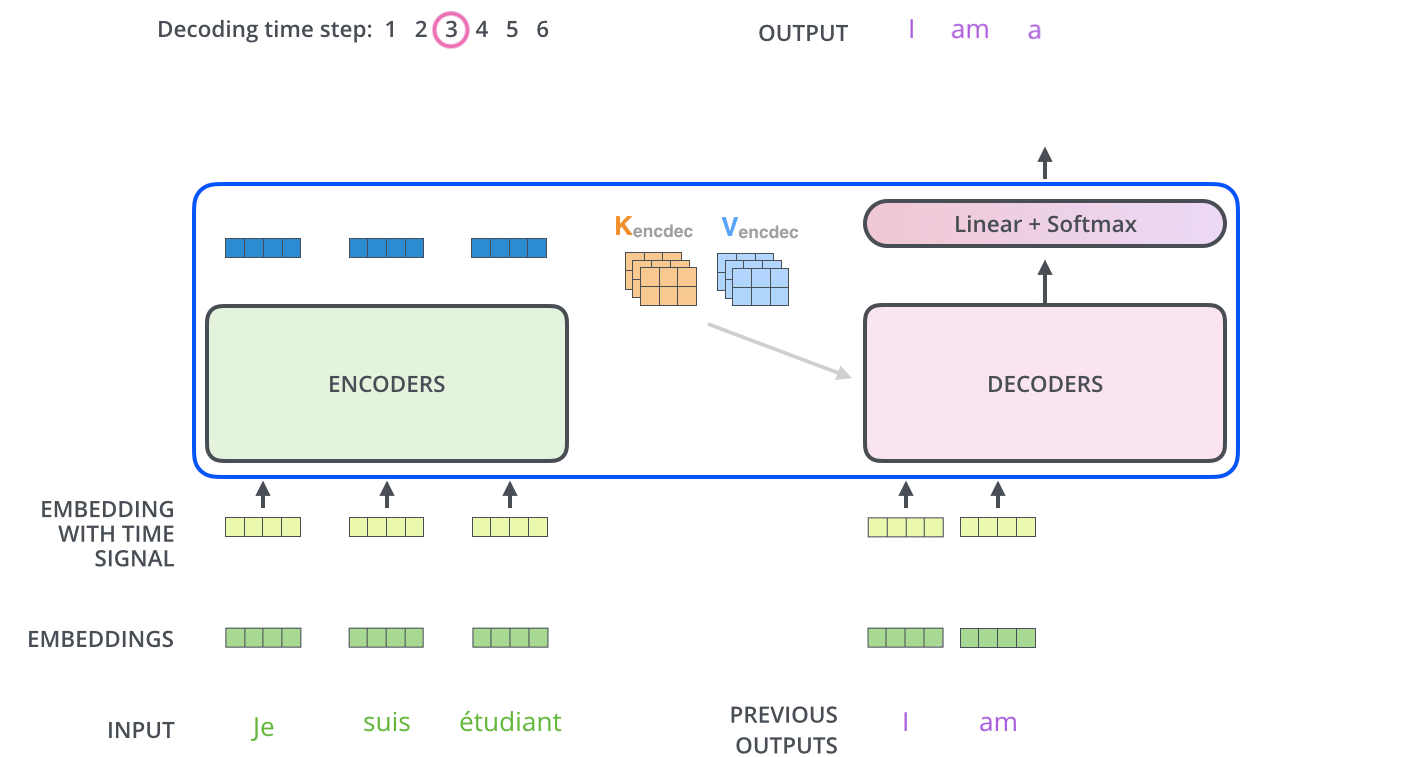
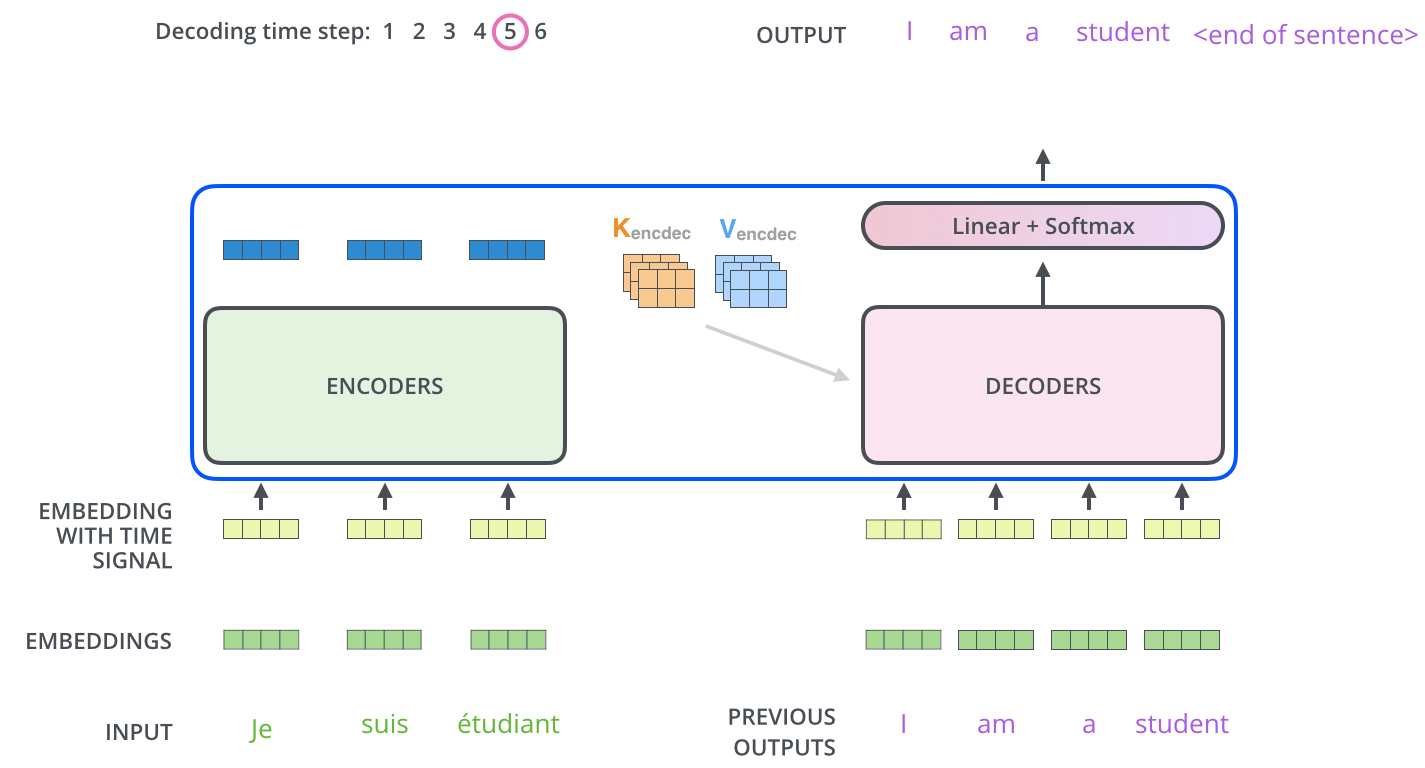
重复上面的过程,直到 decoder 完成了输出,每个时间步的输出都在下一个时间步时喂入给最底部的 decoder,同样,在这些 decoder 的输入中也加入了位置编码,来表示每个字的位置。
解码器中的 self attention 层与编码器中的略有不同
在解码器中,在 self attention 的 softmax 步骤之前,将未来的位置设置为 -inf 来屏蔽这些位置,这样做是为了 self attention 层只能关注输出序列中靠前的一些位置。
Encoder-Decoder Attention 层的工作方式与 multiheaded self-attention 类似,只是它用下面的层创建其 Queries 矩阵,从编码器栈的输出中获取 Keys 和 Values 矩阵。
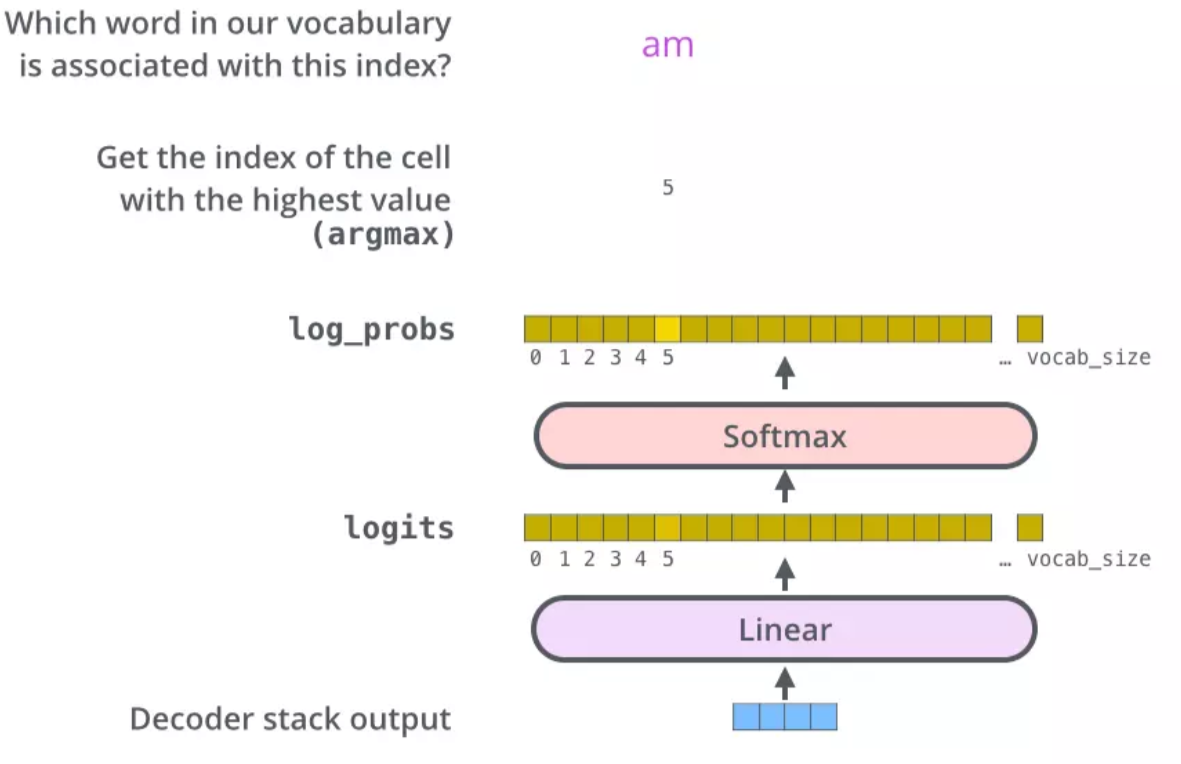
解码器最后输出的是一个向量,如何把它变成一个单词,这就要靠它后面的线性层和 softmax 层
线性层就是一个很简单的全连接神经网络,将解码器输出的向量映射成一个更长的向量。
例如我们有 10,000 个无重复的单词,那么最后输出的向量就有一万维。
每个位置上的值代表了相应单词的分数。
参考:
https://arxiv.org/abs/1706.03762
Attention is All You Need
https://www.jianshu.com/p/e7d8caa13b21
图解什么是 Transformer
https://baijiahao.baidu.com/s?id=1622064575970777188&wfr=spider&for=pc
BERT大火却不懂Transformer?读这一篇就够了
https://blog.csdn.net/qq_41664845/article/details/84969266
图解Transformer
https://www.jianshu.com/p/ef41302edeef?utm_source=oschina-app
神经机器翻译 之 谷歌 transformer 模型
https://www.nowcoder.com/discuss/258321?type=2
NLPer看过来,一些关于Transformer的问题整理
Transformer详解的更多相关文章
- Transformer详解:各个特征维度分析推导
谷歌在文章<Attention is all you need>中提出的transformer模型.如图主要架构:同样为encoder-decoder模式,左边部分是encoder,右边部 ...
- Attention和Transformer详解
目录 Transformer引入 Encoder 详解 输入部分 Embedding 位置嵌入 注意力机制 人类的注意力机制 Attention 计算 多头 Attention 计算 残差及其作用 B ...
- Transformer 详解
感谢:https://www.jianshu.com/p/04b6dd396d62 Transformer模型由<Attention is all your need>论文中提出,在seq ...
- Transformer各层网络结构详解!面试必备!(附代码实现)
1. 什么是Transformer <Attention Is All You Need>是一篇Google提出的将Attention思想发挥到极致的论文.这篇论文中提出一个全新的模型,叫 ...
- seq2seq模型详解及对比(CNN,RNN,Transformer)
一,概述 在自然语言生成的任务中,大部分是基于seq2seq模型实现的(除此之外,还有语言模型,GAN等也能做文本生成),例如生成式对话,机器翻译,文本摘要等等,seq2seq模型是由encoder, ...
- 无所不能的Embedding6 - 跨入Transformer时代~模型详解&代码实现
上一章我们聊了聊quick-thought通过干掉decoder加快训练, CNN-LSTM用CNN作为Encoder并行计算来提速等方法,这一章看看抛开CNN和RNN,transformer是如何只 ...
- 78. Android之 RxJava 详解
转载:http://gank.io/post/560e15be2dca930e00da1083 前言 我从去年开始使用 RxJava ,到现在一年多了.今年加入了 Flipboard 后,看到 Fli ...
- 给 Android 开发者的 RxJava 详解
我从去年开始使用 RxJava ,到现在一年多了.今年加入了 Flipboard 后,看到 Flipboard 的 Android 项目也在使用 RxJava ,并且使用的场景越来越多 .而最近这几个 ...
- Fiddler界面详解
Statistics 页签 完整页签如下图: Statistics 页签显示当前用户选择的 Sessions 的汇总信息,包括:选择的 Sessions 总数.发送字节数.接收字节数.响应类型的汇总表 ...
随机推荐
- HDU 6046 - hash | 2017 Multi-University Training Contest 2
思路来自题解和一些博客 最麻烦的是样例没啥用- - /* HDU 6046 - hash [ hash,鸽巢 ] | 2017 Multi-University Training Contest 2 ...
- Spring Boot系列目录
1.spring mvc 接口动态注入 FactoryBean ImportBeanDefinitionRegistrar ClassPathScanningCandidateComponentPro ...
- 小程序列表倒计时 wxs 实现
效果 代码 js //拿到服务器时间 var serverLocalDate = data.serverLocalDate; //调用函数开始计时 this.serverLocalDate(serve ...
- 调用七牛云存储文件,返回url
文档地址:https://developer.qiniu.com/kodo/sdk/1283/javascript#2 npm引入 npm install qiniu-js 例子: var obser ...
- 集合家族——LinkedList
一.概述: LinkedList 与 ArrayList 一样实现 List 接口,只是 ArrayList 是 List 接口的大小可变数组的实现,LinkedList 是 List 接口链表的实现 ...
- [Shell] 分隔字符串为数组
#!/bin/bash tmp="test,girl,boy,love" OLD_IFS="$IFS" IFS="," arr=($a) I ...
- 1.2 JAVA的String类和StringBuffer类
一.String 1.String概念 String不属于基本类型,String是final修饰的是不可改变的,所以你一旦创建了 String 对象,那它的值就无法改变了如果要对String修改使用 ...
- 反省——关于csp-s模拟50
本人于搜索csp-s模拟49题解时,有意识地点开了一篇关于csp-s模拟50T2的题解,并知道了题解是二维前缀和以及四维偏序. 更重要的是,那篇博客说有解法二,叫二维莫队. 于是我上网搜索二维莫队,结 ...
- Filebeat使用
1.Beat家族 Beats可以直接(或者通过Logstash)将数据发送到Elasticsearch,在那里你可以进一步处理和增强数据,然后在Kibana中将其可视化. 2.FileBeat安装 2 ...
- (转载)完成端口(CompletionPort)详解 - 手把手教你玩转网络编程系列之三
转自:http://blog.csdn.net/piggyxp/article/details/6922277 前 言 本系列里完成端口的代码在两年前就已经写好了,但是由于许久没有写东西了,不知该如何 ...