算法flink
和Yarn-Cluster模式不同,Session模式的资源在启动Yarn-Session时候就已经启动了,后续提交的作业全都在已申请的资源空间内运行,比较适合小而多的作业
# 启动yarn-session模式,不用启动flink集群
cm:
http://152.32.141.11:7180/cmf/login
登陆manager节点:
sudo su hdfs
yarn application -list
#查flink session的application id

#打开flink的web管理
http://manager.algorithm.opayride.com:8088/proxy/application_1572516566413_0919/#/job
#算法启动session:
/data/flink/bin/yarn-session.sh -n 20 -m 4 -qu flink -jm 1024 -tm 8192 -s 2 -d
-n 多少个容器
tm 每个容器的内存
-s 每个任务用多少slot
#在session上run job
cd /var/lib/hadoop-hdfs/src/oride-research/flink/flink-ufile
flink run -p 4 -c com.opay.research.hadoop.UfileJob target/flink-ufile-1.0.jar --prod
重启session:
1/ 在web管理界面上退出:
点running jobs,点运行的session job进去,把它cancel掉
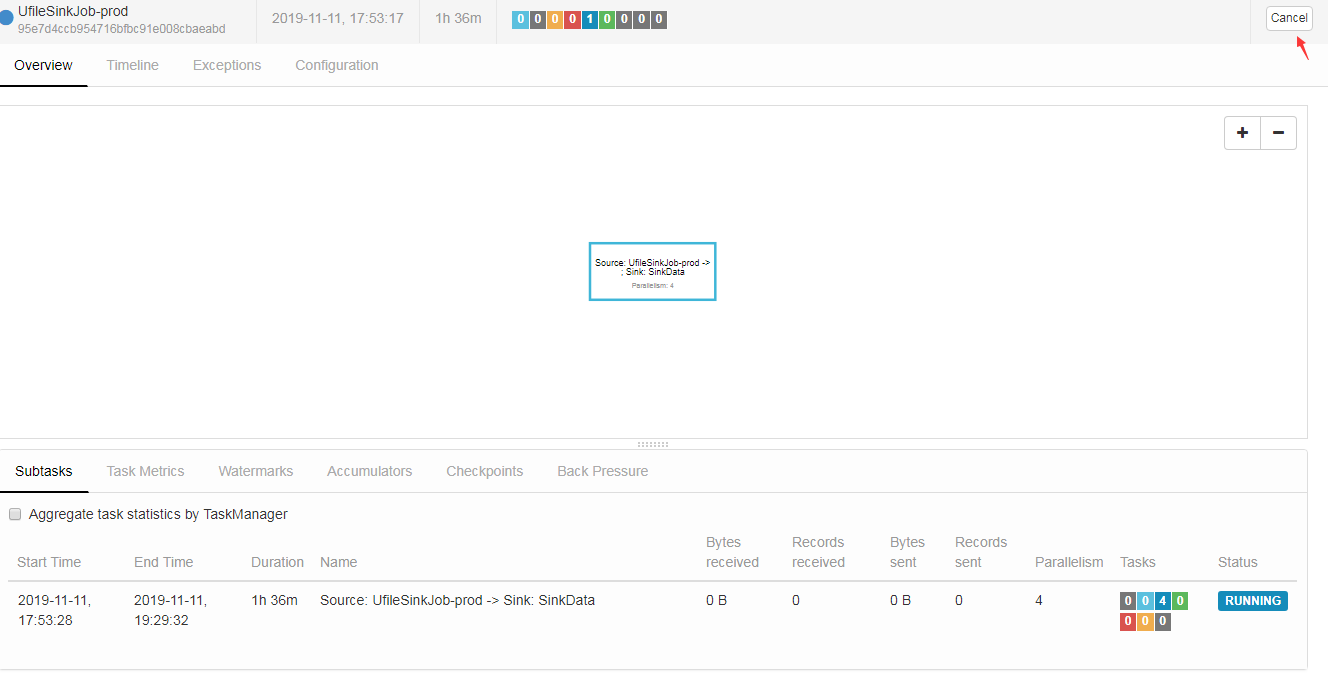
2/ 用yarn kill application xxx把flink作业kill
3/ 重新启动seesion
/data/flink/bin/yarn-session.sh -n 20 -m 4 -qu flink -jm 1024 -tm 8192 -s 2 -d
参数:
bin/yarn-session.sh –help
Usage:
Required
-n,--container <arg> Number of YARN container to allocate (=Number of Task Managers)
Optional
-D <property=value> use value for given property
-d,--detached If present, runs the job in detached mode
-h,--help Help for the Yarn session CLI.
-id,--applicationId <arg> Attach to running YARN session
-j,--jar <arg> Path to Flink jar file
-jm,--jobManagerMemory <arg> Memory for JobManager Container with optional unit (default: MB)
-m,--jobmanager <arg> Address of the JobManager (master) to which to connect. Use this flag to connect to a different JobManager than the one specified in the configuration.
-n,--container <arg> Number of YARN container to allocate (=Number of Task Managers)
-nl,--nodeLabel <arg> Specify YARN node label for the YARN application
-nm,--name <arg> Set a custom name for the application on YARN
-q,--query Display available YARN resources (memory, cores)
-qu,--queue <arg> Specify YARN queue.
-s,--slots <arg> Number of slots per TaskManager
-sae,--shutdownOnAttachedExit If the job is submitted in attached mode, perform a best-effort cluster shutdown when the CLI is terminated abruptly, e.g., in response to a user interrupt, such
as typing Ctrl + C.
-st,--streaming Start Flink in streaming mode
-t,--ship <arg> Ship files in the specified directory (t for transfer)
-tm,--taskManagerMemory <arg> Memory per TaskManager Container with optional unit (default: MB)
-yd,--yarndetached If present, runs the job in detached mode (deprecated; use non-YARN specific option instead)
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper sub-paths for high availability mode
也可在启动时得到它的web地址
# 启动yarn-session模式,不用启动flink集群
[root@oldboy-node101 conf]# yarn-session.sh
2019-08-03 21:57:59,585 WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Flink JobManager is now running on oldboy-node103:35244 with leader id 00000000-0000-0000-0000-000000000000.
JobManager Web Interface: http://oldboy-node103:35244
算法flink的更多相关文章
- (二)基于商品属性的相似商品推荐算法——Flink SQL实时计算实现商品的隐式评分
系列随笔: (总览)基于商品属性的相似商品推荐算法 (一)基于商品属性的相似商品推荐算法--整体框架及处理流程 (二)基于商品属性的相似商品推荐算法--Flink SQL实时计算实现商品的隐式评分 ( ...
- Peeking into Apache Flink's Engine Room
http://flink.apache.org/news/2015/03/13/peeking-into-Apache-Flinks-Engine-Room.html Join Processin ...
- Apache Flink vs Apache Spark——感觉二者是互相抄袭啊 看谁的好就抄过来 Flink支持在runtime中的有环数据流,这样表示机器学习算法更有效而且更有效率
Apache Flink是什么 Flink是一款新的大数据处理引擎,目标是统一不同来源的数据处理.这个目标看起来和Spark和类似.没错,Flink也在尝试解决 Spark在解决的问题.这两套系统都在 ...
- flink Transitive Closure算法,实现寻找新的可达路径
flink 使用Transitive Closure算法实现可达路径查找. 1.Transitive Closure是翻译闭包传递?我觉得直译不准确,意译应该是传递特性直至特性关闭,也符合本例中传递路 ...
- flink 实现ConnectedComponents 连通分量,增量迭代算法(Delta Iteration)实现详解
1.连通分量是什么? 首先需要了解什么是连通图.无向连通图.极大连通子图等概念,这些概念都来自数据结构-图,这里简单介绍一下. 下图是连通图和非连通图,都是无向的,这里不扩展有向图: 连通分量(con ...
- flink KMeans算法实现
更正:之前发的有两个错误. 1.K均值聚类算法 百度解释:k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类 ...
- flink 实现三角枚举EnumTriangles算法详解
1.三角枚举,从所有无向边对中找到相互连接的三角形 /** * @Author: xu.dm * @Date: 2019/7/4 21:31 * @Description: 三角枚举算法 * 三角枚举 ...
- flink PageRank详解(批量迭代的页面排名算法的基本实现)
1.PageRank算法原理 2.基本数据准备 /** * numPages缺省15个测试页面 * * EDGES表示从一个pageId指向相连的另外一个pageId */ public clas ...
- Flink 剖析
1.概述 在如今数据爆炸的时代,企业的数据量与日俱增,大数据产品层出不穷.今天给大家分享一款产品—— Apache Flink,目前,已是 Apache 顶级项目之一.那么,接下来,笔者为大家介绍Fl ...
随机推荐
- 【csp模拟赛1】铁路网络 (network.cpp)
[题目描述] 在暑假来临之际,小 Z 的地理老师布置了一个暑假作业,让同学们暑假期间 了解一下 C 国的铁路发展史.小 Z 在多番查证资料后发现,C 国在铁路发展初期, 铁路网络有着一个严密规整的结构 ...
- BDD行为驱动简介及Pytest-bdd基础使用
目录 BDD介绍 需求描述/用户场景 场景解析/实现 场景测试 Pytest-bdd的参数化 运行环境: pip insall pytest pytest-bdd pytest-selenium BD ...
- python 正则相关函数全解析
前言:网上有很多关于python正则函数的方法说明,这里尽可能用最简单的demo把所有函数之间的逻辑关系说清楚,供参考. 1.最原始的 re.compile()这个函数一般是需要和其它函数一起使用的, ...
- LIUNX 安装 nginx
安装依赖 yum install gcc yum install pcre-devel yum install zlib zlib-devel yum install openssl openssl- ...
- Educational Codeforces Round 53 E. Segment Sum(数位DP)
Educational Codeforces Round 53 E. Segment Sum 题意: 问[L,R]区间内有多少个数满足:其由不超过k种数字构成. 思路: 数位DP裸题,也比较好想.由于 ...
- TypeScript 技巧
前言 很早以前就尝试过使用 TypeScript 来进行日常编码,但自己对静态类型语言的了解并不深入,再加上 TypeScript 的类型系统有着一定的复杂度,因此感觉自己并没有发挥好这门语言的优势, ...
- 必懂知识——HashMap的实现原理
HashMap的底层数据结构 1.7之前是:数组+链表 数组的元素是Map.Entiry对象 当出现哈希碰撞的时候,使用链表解决, 先计算出key对应的数组的下标,这个数组的这个位置上为空,直接放入, ...
- 判定Java程序员等级,HashMap就够了
JDK1.8 HashMap源码分析 用到的符号: ^异运算:两个操作数相同,结果是;两个操作数不同,结果是1. &按位与:两个操作数都是1,结果才是1. 一.HashMap概述 在JDK1 ...
- Amdahl定律和可伸缩性
性能的思考 提升性能意味着可以用更少的资源做更多的事情.但是提升性能会带来额外的复杂度,这会增加线程的安全性和活跃性上的风险. 我们渴望提升性能,但是还是要以安全为首要的.首先要保证程序能够安全正常的 ...
- ARP输入 之 arp_rcv
概述 arp_rcv是ARP包的入口函数,ARP模块在二层注册了类型为ETH_P_ARP的数据包回调函数arp_rcv,当收到ARP包时,二层进行分发,调用arp_rcv: arp_rcv对ARP输入 ...