[转载]机器学习优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam
[转载]机器学习优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam
https://blog.csdn.net/u010089444/article/details/76725843
这篇博客格式不好直接粘贴,就不附原文了。
有几个点可以注意下,原文没有写的很清楚:
优化方法的作用是什么?
可以说,没有优化方法,机器学习模型一般一样可以执行,所以说它并不是必须的。但是优化方法可以动态调整学习率以及影响迭代中参数调整的方向和幅度,可以加速收敛,是对原方法的一种优化。
Momentum:
Momentum方法一般用来辅助SGD,从下图也能看出来:
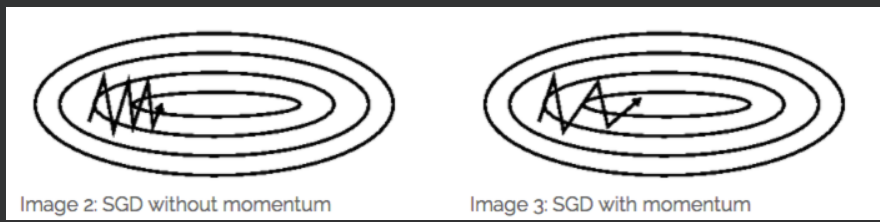
它的作用是加速SGD,并且抑制震荡。
另外,从原理上来说,它应用在BGD上也没有什么问题。
Nesterov Momentum方法是Momentum方法的一种改进,思路也是和传统的思路比较类似的:传统思路中,在一次参数更新中,更新后面的参数如果要使用前面的参数,则使用本次更新中前面参数已经更新了的值可以加速收敛。这里是反过来了:先更新vt,后更新梯度。但是vt的计算中要用到梯度,这里就使用梯度更新后的值可以使得结果更加准确、收敛更快。但是这时更新值还没有计算出来,于是使用了”预测“值,J中的梯度计算取的是迭代公式中的线性部分。
什么是”矩估计“
来源:https://baike.baidu.com/item/%E7%9F%A9%E4%BC%B0%E8%AE%A1
矩估计,即矩估计法,也称“矩法估计”,就是利用样本矩来估计总体中相应的参数。首先推导涉及感兴趣的参数的总体矩(即所考虑的随机变量的幂的期望值)的方程。然后取出一个样本并从这个样本估计总体矩。接着使用样本矩取代(未知的)总体矩,解出感兴趣的参数。从而得到那些参数的估计。
其实就是用样本估计总体
在实际应用中 ,Adam为最常用的方法,可以比较快地得到一个预估结果
[转载]机器学习优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam的更多相关文章
- 深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)
深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam) 深度学习笔记(一):logistic分类 深度学习笔记(二):简单神经网络,后向传播算法及实现 ...
- 优化方法:SGD,Momentum,AdaGrad,RMSProp,Adam
参考: https://blog.csdn.net/u010089444/article/details/76725843 1. SGD Batch Gradient Descent 在每一轮的训练过 ...
- 机器学习优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)
SGD: 此处的SGD指mini-batch gradient descent,关于batch gradient descent, stochastic gradient descent, 以及 mi ...
- 优化器,SGD+Momentum;Adagrad;RMSProp;Adam
Optimization 随机梯度下降(SGD): 当损失函数在一个方向很敏感在另一个方向不敏感时,会产生上面的问题,红色的点以“Z”字形梯度下降,而不是以最短距离下降:这种情况在高维空间更加普遍. ...
- 5、Tensorflow基础(三)神经元函数及优化方法
1.激活函数 激活函数(activation function)运行时激活神经网络中某一部分神经元,将激活信息向后传入下一层的神经网络.神经网络之所以能解决非线性问题(如语音.图像识别),本质上就是激 ...
- Deep Learning基础--参数优化方法
1. 深度学习流程简介 1)一次性设置(One time setup) -激活函数(Activation functions) - 数据预处理(Data Preprocessing) ...
- 各种优化方法总结比较(sgd/momentum/Nesterov/adagrad/adadelta)
前言 这里讨论的优化问题指的是,给定目标函数f(x),我们需要找到一组参数x,使得f(x)的值最小. 本文以下内容假设读者已经了解机器学习基本知识,和梯度下降的原理. Batch gradient d ...
- 深度学习常见的优化方法(Optimizer)总结:Adam,SGD,Momentum,AdaGard等
机器学习的常见优化方法在最近的学习中经常遇到,但是还是不够精通.将自己的学习记录下来,以备不时之需 基础知识: 机器学习几乎所有的算法都要利用损失函数 lossfunction 来检验算法模型的优劣, ...
- 优化方法总结以及Adam存在的问题(SGD, Momentum, AdaDelta, Adam, AdamW,LazyAdam)
优化方法总结以及Adam存在的问题(SGD, Momentum, AdaDelta, Adam, AdamW,LazyAdam) 2019年05月29日 01:07:50 糖葫芦君 阅读数 455更多 ...
随机推荐
- Servlet 的三种跳转方式
1.Forword request.getRequestDispatcher (“url”).forword (request,response) 是请求转发,也就是说,一个 Servlet 向当前的 ...
- 013-java中的IO操作-InputStream/Reader、OutputStream/Writer
一.概述 IO流用来处理设备之间的数据传输,上传文件和下载文件,Java对数据的操作是通过流的方式,Java用于操作流的对象都在IO包中. 流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称 ...
- prometheus数据上报方式-pushgateway
pushgateway 客户端使用push的方式上报监控数据到pushgateway,prometheus会定期从pushgateway拉取数据.使用它的原因主要是: Prometheus 采用 pu ...
- 运行React Native项目出现白屏,无法运行
运行React Native出现白屏,无法运行,查看终端报错如下: 原因: 代码中有语法错误,导致运行失败. 其实到这里可以去Xcode查看控制台打印,会提示哪个文件出现错误的. 解决办法: 找到报错 ...
- UICollectionview的头视图和尾视图
UITableView有头视图和尾视图,那么UICollectionView有没有头视图和尾视图呢? 答案是有的. 1.新建一个类,必须继承自 UICollectionReusableView. 2. ...
- django项目添加路由----返回给客户端内容-----windows中的python
django项目添加路由 url函数的第一个参数是匹配url路径的正则表达式,第2个参数是路由函数 第一个正则表达式是r'^$',其中r表示正则表达式字符串不对转义符进行转义.“^”表示匹配URL路径 ...
- PL-VIO Docker测试
Docker里面测试PL-VIO的代码 PL-VIO贺一家大佬最近开源出来的一个点线特征融合的VIO代码,基于Vins-Mono,想要快速测试一下代码,所以就写了个简单的Dockerfile来测试一下 ...
- Had I not seen the Sun(如果我不曾见过太阳)
Had I not seen the Sun by Emily Dickinson Had I not seen the Sun I could have borne the shade But Li ...
- 【ARM-Linux开发】内核3.x版本之后设备树机制
内核3.x版本之后设备树机制 Based on Linux 3.10.24 source code 参考/documentation/devicetree/Booting-without- ...
- SpringBoot整合Redis及Redis工具类
前言 想做一个秒杀项目,问了几个大佬要了项目视频,结果,自己本地实践的时候,发现不太一样,所以写下这篇,为以后做准备. 环境配置 IDE:IDEA 环境:Windows 数据库:Redis Maven ...