Apache Flink - 常见数据流类型
DataStream:
DataStream是 Flink 流处理 API 中最核心的数据结构。它代表了一个运行在多个分区上的并行流。一个DataStream可以从StreamExecutionEnvironment通过env.addSource(SourceFunction)获得。- DataStream 上的转换操作都是逐条的,比如
map(),flatMap(),filter()。DataStream 也可以执行rebalance(再平衡,用来减轻数据倾斜)和broadcaseted(广播)等分区转换。 如上图的执行图所示,DataStream 各个算子会并行运行,算子之间是数据流分区。如 Source 的第一个并行实例(S1)和 flatMap() 的第一个并行实例(m1)之间就是一个数据流分区。而在 flatMap() 和 map() 之间由于加了 rebalance(),它们之间的数据流分区就有3个子分区(m1的数据流向3个map()实例)。
KeyedStream:
KeyedStream用来表示根据指定的key进行分组的数据流。KeyedStream可以通过调用DataStream.keyBy()来获得。而在KeyedStream上进行任何transformation都将转变回DataStream。在实现中,KeyedStream是把key的信息写入到了transformation中。每条记录只能访问所属key的状态,其上的聚合函数可以方便地操作和保存对应key的状态。
WindowedStream & AllWindowedStream:
WindowedStream代表了根据key分组,并且基于WindowAssigner切分窗口的数据流。所以WindowedStream都是从KeyedStream衍生而来的。而在WindowedStream上进行任何transformation也都将转变回DataStream。DataStream[MyType] stream = ...
WindowedDataStream[MyType] windowed = stream
.keyBy("userId")
.window(TumblingEventTimeWindows.of(Time.seconds(5))) // Last 5 seconds of data
DataStream[ResultType] result = windowed.reduce(myReducer)Flink 的窗口实现中会将到达的数据缓存在对应的窗口buffer中(一个数据可能会对应多个窗口)。当到达窗口发送的条件时(由Trigger控制),Flink 会对整个窗口中的数据进行处理。Flink 在聚合类窗口有一定的优化,即不会保存窗口中的所有值,而是每到一个元素执行一次聚合函数,最终只保存一份数据即可。
- 在key分组的流上进行窗口切分是比较常用的场景,也能够很好地并行化(不同的key上的窗口聚合可以分配到不同的task去处理)。不过当我们需要在普通流上进行窗口操作时,就要用到
AllWindowedStream。AllWindowedStream是直接在DataStream上进行windowAll(...)操作。AllWindowedStream 的实现是基于 WindowedStream 的。Flink 不推荐使用AllWindowedStream,因为在普通流上进行窗口操作,就势必需要将所有分区的流都汇集到单个的Task中,而这个单个的Task很显然就会成为整个Job的瓶颈。
JoinedStreams & CoGroupedStreams:
- co-group 侧重的是group,是对同一个key上的两组集合进行操作,而 join 侧重的是pair,是对同一个key上的每对元素进行操作, join 只是 co-group 的一个特例。
- JoinedStreams 和 CoGroupedStreams 是基于 Window 上实现的,所以 CoGroupedStreams 最终又调用了 WindowedStream 来实现。
DataStream[MyType] firstInput = ...
DataStream[AnotherType] secondInput = ... DataStream[(MyType, AnotherType)] result = firstInput.join(secondInput)
.where("userId").equalTo("id")
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply (new JoinFunction () {...})双流上的数据在同一个key的会被分别分配到同一个window窗口的左右两个篮子里,当window结束的时候,会对左右篮子进行笛卡尔积从而得到每一对pair,对每一对pair应用 JoinFunction。
ConnectedStreams:
- 在 DataStream 上有一个 union 的转换
dataStream.union(otherStream1, otherStream2, ...),用来合并多个流,新的流会包含所有流中的数据。union 有一个限制,就是所有合并的流的类型必须是一致的。 - union 有一个限制,就是所有合并的流的类型必须是一致的。
ConnectedStreams提供了和 union 类似的功能,用来连接两个流,但是与 union 转换有以下几个区别:- ConnectedStreams 只能连接两个流,而 union 可以连接多个流。
- ConnectedStreams 连接的两个流类型可以不一致,而 union 连接的流的类型必须一致。
- ConnectedStreams 会对两个流的数据应用不同的处理方法,并且双流之间可以共享状态。这在第一个流的输入会影响第二个流时, 会非常有用。
- 如下 ConnectedStreams 的样例,连接
input和other流,并在input流上应用map1方法,在other上应用map2方法,双流可以共享状态(比如计数)。DataStream[MyType] input = ...
DataStream[AnotherType] other = ... ConnectedStreams[MyType, AnotherType] connected = input.connect(other) DataStream[ResultType] result =
connected.map(new CoMapFunction[MyType, AnotherType, ResultType]() {
override def map1(value: MyType): ResultType = { ... }
override def map2(value: AnotherType): ResultType = { ... }
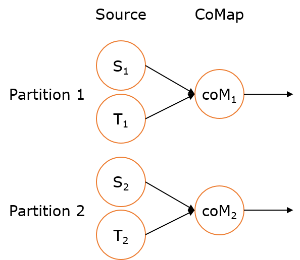
})当并行度为2时:
Apache Flink - 常见数据流类型的更多相关文章
- [Note] Apache Flink 的数据流编程模型
Apache Flink 的数据流编程模型 抽象层次 Flink 为开发流式应用和批式应用设计了不同的抽象层次 状态化的流 抽象层次的最底层是状态化的流,它通过 ProcessFunction 嵌入到 ...
- Apache Flink vs Apache Spark——感觉二者是互相抄袭啊 看谁的好就抄过来 Flink支持在runtime中的有环数据流,这样表示机器学习算法更有效而且更有效率
Apache Flink是什么 Flink是一款新的大数据处理引擎,目标是统一不同来源的数据处理.这个目标看起来和Spark和类似.没错,Flink也在尝试解决 Spark在解决的问题.这两套系统都在 ...
- Apache Flink - 数据流容错机制
Apache Flink提供了一种容错机制,可以持续恢复数据流应用程序的状态.该机制确保即使出现故障,程序的状态最终也会反映来自数据流的每条记录(只有一次). 从容错和消息处理的语义上(at leas ...
- Apache Flink 介绍
原文地址:https://mp.weixin.qq.com/s?__biz=MzU2Njg5Nzk0NQ==&mid=2247483660&idx=1&sn=ecf01cfc8 ...
- 深入理解Apache Flink
Apache Flink(下简称Flink)项目是大数据处理领域最近冉冉升起的一颗新星,其不同于其他大数据项目的诸多特性吸引了越来越多人的关注.本文将深入分析Flink的一些关键技术与特性,希望能够帮 ...
- 深入理解Apache Flink核心技术
深入理解Apache Flink核心技术 2016年02月18日 17:04:03 阅读数:1936 标签: Apache-Flink数据流程序员JVM 版权声明:本文为博主原创文章,未经博主允许 ...
- 《从0到1学习Flink》—— Apache Flink 介绍
前言 Flink 是一种流式计算框架,为什么我会接触到 Flink 呢?因为我目前在负责的是监控平台的告警部分,负责采集到的监控数据会直接往 kafka 里塞,然后告警这边需要从 kafka topi ...
- Apache Flink 入门示例demo
在本文中,我们将从零开始,教您如何构建第一个Apache Flink (以下简称Flink)应用程序. 开发环境准备 Flink 可以运行在 Linux, Max OS X, 或者是 Windows ...
- Apache Flink -Streaming(DataStream API)
综述: 在Flink中DataStream程序是在数据流上实现了转换的常规程序. 1.示范程序 import org.apache.flink.api.common.functions.FlatMap ...
随机推荐
- ElementUI+命名视图实现复杂顶部和左侧导航栏
在了解了命名视图的用途后,发现用命名视图来实现复杂导航更加省力.更多知识请参考这里 这里只说明重要配置内容,其他内容配置请参考上一篇初始版本: ElementUI 复杂顶部和左侧导航栏实现 或参考文末 ...
- JavaScript常用节点类型
一.常用节点类型: nodeType:节点类型 nodeName:节点名称 nodeValue:节点值 1.查看节点类型(控制台操作): 获取元素:var p = document.getElemen ...
- js时间格式化和相互转换
1. Thu Mar 07 2019 12:00:00 GMT+0800 (中国标准时间) 转换为 2019-03-07 12:00:00 const d = new Date(Thu Mar 07 ...
- jquery-weui滚动事件的注册与注销
注册infinite(50)是自定义的,详细暂时没去了解,可以不写即代表默认值. // body是整一块代码的标签,也就是滚动的部分. $('body').infinite().on("in ...
- Nginx.conf配置文件默认配置块略解
#user nobody; worker_processes 1; #error_log logs/error.log; #error_log logs/error.log notice; #erro ...
- PS批量制作获奖证书并导出PNG
其实方法和"使用PS批量制作视频字幕"的方法类似.区别在于制作视频字幕时导出成psd格式就可以直接导入Premiere中使用了,而获奖证书考虑到打印设备有无PS的不确定性,可能需要 ...
- js、jquery实现列表模糊搜索功能
实现的搜索功能: 1. 可以匹配输入的字符串找出列表中匹配的项,列表框的高度跟随搜索出的列表项的多少改变 2. 可以点击某一项进行选中列表项 3. 可以按下上.下.回车键来控制列表项 4. 按下回车键 ...
- python3 wordcloud词云
wordclou:根据文本生成词云 一.词云设置 wc=WordCloud(width=400, height=200, #画布长.宽,默认(400,200)像素 margin=1, #字与字之间的距 ...
- redis 介绍与操作
参考连接: https://www.cnblogs.com/wupeiqi/articles/5132791.html redis 是什么? redis是一个软件,帮助开发者对一台机器的内存进行操作 ...
- NO.24两两交换链表中的节点
NO.24两两交换链表中的节点 给定一个链表,两两交换其中相邻的节点,并返回交换后的链表. 你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换. 示例:给定 1->2->3-&g ...