【分类算法】决策树(Decision Tree)
(注:本篇博文是对《统计学习方法》中决策树一章的归纳总结,下列的一些文字和图例均引自此书~)
决策树(decision tree)属于分类/回归方法。其具有可读性、可解释性、分类速度快等优点。决策树学习包含3个步骤:特征选择、决策树生成、决策树修剪(剪枝)。
0 - 决策树问题
0.0 - 问题描述
假设训练集为
$$D=\{(x_1,y_1),(x_2,y_2),\cdots ,(x_N,y_N)\},$$
其中$x_i=(x_i^{(1)},x_i^{(2)},\cdots,x_i^{(n)})^T$为输入实例(特征向量),$n$为特征个数,$y_i \in \{1,2,\cdots,K\}$为类标记,$i=1,2,\cdots, N$为样本容量。根据训练集构建一个决策树模型,使得能够对于输入$x_i$,给出预测的分类$y_i$。
0.1 - 决策树思想
决策树学习通常是一个递归选择最优特征,并根据该特征对训练数据机型分割,使得对各个之数据集有一个最好的分类的过程。其算法可以描述为如下过程:
- step 0:如果特征数量很多,可以先在决策树学习开始之前对特征进行筛选,只留下对训练数据有足够分类能力的特征,其实就是数据降维(此步不是必须的!)
- step 1:构建根结点,将所有训练数据都放在根结点
- step 2:选择一个最优特征,按照这一特征把当前结点的数据分割成子集。如果这些子集已经能够基本正确分类,转step 3;否则,对于每一个结点,转step 2
- step 3:将该节点构建成叶结点
- step 4:在决策树构造完成之后,需要对决策树自下而上进行剪枝,将树变得更加简单,从而使得它具有更好的泛化能力(具体就是去掉过于细分的叶结点,使其回退到父结点,甚至更高的结点,然后将父结点或更高的结点改为新的叶结点)
经过上述过程之后,所有训练数据都被分到叶结点上,即都有了明确的分类,这就生成了一颗决策树。注意到,对于训练集能够进行正确分类的决策树可能有多个,也可能没有,我们需要的只是一个与训练集矛盾较小的决策树,同时具有很好的泛化能力(不仅仅对训练集有好的拟合,对测试集也应该有很好的预测)。从所有可能的决策树中选取最优决策树是NP完全问题,因此在实际中的决策树学习算法通常采用启发式方法,近似求解这一最优化问题,这样子得到的决策树是次最优的。
1 - 特征选择
首先需要注意到,如果利用一个特征进行分类的结果与随机分类的结果没有很大差别,则称这个特征是没有分类能力的。经验上扔掉这样的特征对决策树学习的精度影响不大。可以通过信息增益、信息增益比以及基尼系数来作为特征选择的准则。在介绍特征选择算法之前,需要先明确熵、条件熵、信息增益、信息增益比以及基尼系数几个概念。
1.0 - 熵
定义(熵):在信息论与概率统计中,熵(entropy)是表示随机变量不确定性的度量。设$X$是一个取有限个值得离散随机变量,其概率分布为
$$P(X=x_i)=p_i,\ i=1,2,\cdots,n$$
则随机变量$X$的熵定义为
$$H(X)=-\sum_{i=1}^{n}p_i\ log\ p_i,$$
注意到,熵只依赖于$X$的分布,而与$X$的取值无关,所以也可将$X$的熵记作$H(p)$,即
$$H(p)=-\sum_{i=1}^{n}p_i\ log\ p_i,$$
熵越大,随机变量的不确定性就越大。
(注:当熵的概率由数据估计(特别是极大似然估计)得到时,称为经验熵(empirical entropy))
举例,当$X$只取两个值时(取0和1),则$X$的概率分布为
$$P(X=1)=p,\ P(X=0)=1-p,\ 0\leq p\leq 1$$
熵为
$$H(p)=-p\ log_2\ p-(1-p)\ log_2\ (1-p)$$
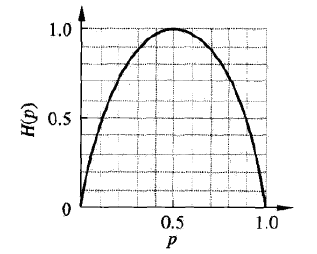
此时$H(p)$随$p$变化曲线如下图所示。可以看到,当$p=0$或$p=1$时,$H(p)=0$,随机变量完全没有不确定性;当$p=0.5$时,$H(p)=1$,此处熵最大,随机变量不确定最大。
1.1 - 条件熵
定义(条件熵):假设有随机变量$(X,Y)$,其联合分布为
$$P(X=x_i,Y=y_i)=p_{ij},\ i=1,2,\cdots,n;\ j=1,2,\cdots,m$$
条件熵$H(Y|X)$表示在已知随机变量$X$的条件下随机变量$Y$的不确定性。随机变量$X$给定的条件下随机变量$Y$的条件熵(conditional entropy)$H(Y|X)$,定义为$X$给定条件下$Y$的条件概率分布的熵对$X$的数学期望
$$H(Y|X)=\sum_{i=1}^nP(X=x_i)H(Y|X=x_i),\ i=1,2,\cdots,n$$
(注:当条件熵的概率由数据估计(特别是极大似然估计)得到时,称为条件经验熵(empirical conditional entropy))
1.2 - 信息增益
信息增益(information gain)表示得知特征$X$的信息而使得类$Y$的信息的不确定性减少的程度。
定义(信息增益):特征$A$对训练数据集$D$的信息增益$g(D,A)$,定义为集合$D$的经验熵$H(D)$与特征$A$给定条件下$D$的经验条件熵$H(D|A)$之差,即
$$g(D,A)=H(D)-H(D|A)$$
1.3 - 信息增益比
信息增益值得大小取决于训练数据,没有绝对意义。比如在分类问题困难的是否,训练集本身的经验熵就很大,从而使得信息增益值也偏大。反之,信息增益值会偏小。可以使用信息增益比(information gain ratio)来进行校正。
定义(信息增益比):特征$A$对训练数据集$D$的信息增益比$g_R(D,A)$,定义为其信息增益$g(D,A)$与训练数据$D$的经验熵$H(D)$之比,即
$$g_R(D,A)=\frac{g(D,A)}{H(D)}$$
1.4 - 基尼系数
基尼系数代表了不纯度,假设有$K$个类别,第$k$个类别的概率为$p_k$,则概率分布的基尼指数表示为
$$Gini(p)=\sum_{k=1}^{K}p_k(1-p_k)=1-sum_{k=1}^{K}p_k^2,$$
基尼指数越小,不纯度越低,特征表达能力越强(和信息增益及信息增益比的趋势是相反的)。对于二分类问题,则有
$$Gini(p)=2p(1-p),$$
对于给定样本集合$D$,其基尼指数为
$$Gini(D)=1-\sum_{k=1}^K\left ( \frac{\left | C_k \right |}{\left | D \right |}\right )^2,$$
其中$C_k$是$D$中属于第$k$类的样本子集,$K$是类的个数。如果样本集合$D$根据特征$A$是否取某一可能值$a$被分割成$D_1$和$D_2$两部分,即
$$D1=\{(x,y)\in D|A(x)=a\},\ D_2=D-D_1,$$
则在特征$A$的条件下,集合$D$的基尼指数定义为
$$Gini(D, A)=\frac{\left | D_1 \right |}{\left | D \right |}Gini(D_1)+\frac{\left | D_2 \right |}{\left | D \right |}Gini(D_2),$$
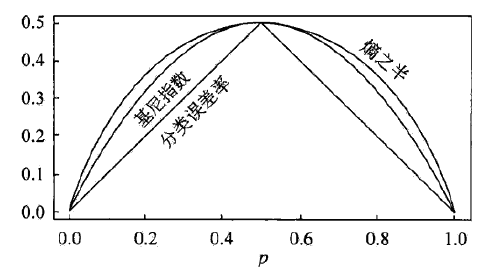
在二类分类中基尼指数与熵之半和分类误差率的关系如下图所示。可以看出基尼指数和熵之半的曲线很接近,并且基尼指数的二元运算比熵中的对数运算简单很多,因此在度量意义上可以用来代替熵。
1.5 - 特征选择原则
决策树学习过程中需要利用信息增益或信息增益比或基尼系数选择特征。
比如在ID3和C4.5算法中,给定训练数据集$D$和特征$A$,经验熵$H(D)$表示对数据集$D$进行分类的不确定性,而经验条件熵$H(D|A)$表示在特征$A$给定的条件下对数据集$D$进行分类的不确定性。那么他们之间的差(信息增益)或者进一步的校正(信息增益比),就是表示由于特征$A$而使得对数据集$D$的分类的不确定性减少的程度。
而在CART算法中,采用了基尼系数代替了信息增益(或信息增益比)来选择特征。
因此,在ID3、C4.5和CART算法中,特征选择的原则是,选择信息增益(信息增益比)更大的特征或激励系数最小的特征,这样子的特征具有更强的分类能力。
2 - 决策树的生成
2.0 - ID3算法
ID3算法采用信息增益作为特征选择的依据。
输入:数据集$D$,特征集$A$,停止计算的条件。
输出:决策树$T$。
其算法过程可描述如下:
- step 1:若$D$中所有实例都属于同一个类别$C_k$,则$T$为单结点树,并将类$C_k$作为该结点的类标记,返回$T$;
- step 2:若$A=\phi$,则$T$为单结点树,并将$D$中实例数量最大的类$C_k$作为该结点的类标记,返回$T$;
- step 3:计算$A$中各个特征对于$D$的信息增益,选取信息增益最大的特征$A_g$‘
- step 4:如果当前结点满足停止计算的条件,则置$T$为单结点树,并将$D$中实例数最大的类$C_k$作为该结点的类标记,返回$T$;
- step 5:否则,根据特征$A_g$将$D$分割成若干个非空子集$D_i$(每个特征值一分割),构建子结点,由结点及其子结点构成数$T$,返回$T$;
- step 6:对第$i$个直接点,以$D_i$为训练集,以$A-\{A_g\}$为特征集,递归地调用step 1~step 5,得到子树$T_i$,返回$T_i$。
2.1 - C4.5算法
C4.5算法相比于ID3,做了如下改进:
- 首先修改了ID3的特征选择方式,改成采用信息增益比选择特征;
- 其次C4.5还将特征类型从只能选择离散型推广到可以选择连续型。
下述算法只考虑特征为离散的情况,连续的情况后面会简单进行描述,不做重点阐述。
输入:数据集$D$,特征集$A$,停止计算的条件。
输出:决策树$T$。
其算法过程可描述如下:
- step 1:若$D$中所有实例都属于同一个类别$C_k$,则$T$为单结点树,并将类$C_k$作为该结点的类标记,返回$T$;
- step 2:若$A=\phi$,则$T$为单结点树,并将$D$中实例数量最大的类$C_k$作为该结点的类标记,返回$T$;
- step 3:计算$A$中各个特征对于$D$的信息增益比,选取信息增益比最大的特征$A_g$‘
- step 4:如果当前结点满足停止计算的条件,则置$T$为单结点树,并将$D$中实例数最大的类$C_k$作为该结点的类标记,返回$T$;
- step 5:否则,根据特征$A_g$将$D$分割成若干个非空子集$D_i$(每个特征值一分割),构建子结点,由结点及其子结点构成数$T$,返回$T$;
- step 6:对第$i$个直接点,以$D_i$为训练集,以$A-\{A_g\}$为特征集,递归地调用step 1~step 5,得到子树$T_i$,返回$T_i$。
2.2 - CART算法(分类树)
不同于ID3和C4.5,CART算法采用基尼指数作为特征分割的依据,并且CART算法构建的是二叉树。
输入:数据集$D$,停止计算的条件。
输出:CART决策树$T$。
- step 1:设当前结点的训练数据为$D$,计算现有特征对该数据集的基尼指数。根据每一个特征$A$,对于其可能的取值$a$,根据样本点对$A=a$成立的“是”或者“否”将$D$分割成$D_1$和$D_2$两部分,计算$A=a$的基尼指数;
- step 2:在所有可能的特征$A$以及它们所有可能的切分点$a$中,选择基尼指数最小的特征及对应的切分点最为最优特征和最优切分点,生成两个子结点,并将数据集根据最优特征和最优切分点分配到两个子结点中;
- step 3:对两个子结点递归调用step 1~step 2,直到满足停止条件,返回决策树$T$。
2.3 - CART算法(回归树)
回归树的构建过程与分类树类似,这里只列出与分类树的几点不同:
- 输出不同。分类树输出的是离散值,回归树输出的是连续值。具体的,分类树采用的是叶子结点里面概率最大的类别作为该结点的预测(离散值),回归树采用的是叶子结点的均值或者中位数来预测(连续值);
- 特征分割依据不同。分类树采用的是基尼指数进行分割度量,回归树采用的是如下表达式进行分割度量(其表示使得分割后的$D_1$和$D_2$各自集合的均方差最小且$D_1$和$D_2$的均方差之和最小)。
$$\underbrace{min}_{A,s}\left [ \underbrace{min}_{c_1}\sum_{x_i\in D_1(A,s)}(y_i-c_1)^2+\underbrace{min}_{c_2}\sum_{x_i\in D_2(A,s)}(y_i-c_2)^2\right ]$$
3 - 决策树的剪枝
采用决策树生成算法生成的决策树可能存在分类过细,过拟合训练数据的问题,为了提高泛化能力,可以对通过预剪枝和后剪枝等剪枝方法来得到低复杂度的决策树。
3.0 - 预剪枝
预剪枝在决策树生成过程中通过提前停止树(如决定某一个结点不再分裂下去)的构造而达到剪枝目的(对应于上一节描述决策树生成中的“停止计算的条件”)。一般的预剪枝方法有如下几种:
- 限定一个高度,当树达到这个高度之后就停止决策树的生长;
- 到达此节点的特征组合符合某一个限制,停止决策树的生长;
- 到达此节点的实例个数小于某一个阈值,停止决策树的生长;
- 计算继续生长对于整体决策树的增益,如果小于某一个阈值,停止决策树生长。
3.1 - 后剪枝
后剪枝是在决策树生成之后再进行剪枝,即由完全成长的树剪去子树形成。对于ID3、C4.5的后剪枝方法和对于CART的后剪枝方法有所区别,下述将分开描述。
3.1.0 - ID3和C4.5的后剪枝
常用的对于ID3和C4.5的后剪枝方法是通过极小化决策树整体的损失函数来实现。其中损失函数定义为
$$C_{\alpha}(T)=\sum_{t=1}^{\left |T\right|}N_tH_t(T)+\alpha\left| T\right |$$
其中$\left| T \right |$表示树$T$的叶结点个数,$t$是树$T$的叶结点,该叶结点有$N_t$个样本,$H_t(T)$为叶结点$t$上的经验熵,$\alpha\geq 0$是一个权衡决策树在训练集上精度以及自身复杂的的参数。
对于第$t$个叶结点,其中$k$类的样本点有$N_{tk}$个,$k=1,2,\cdots,K$,则该叶结点的经验熵可以描述为
$$H_t(T)=-\sum_k\frac{N_{tk}}{N_t}log\frac{N_{tk}}{N_t}$$
则损失函数可以写成如下形式
$$C_{\alpha}(T)=\sum_{t=1}^{\left |T\right|}N_tH_t(T)+\alpha\left| T\right |=\sum_{t=1}^{\left |T\right|}N_t\left (-\sum_{k=1}^K\frac{N_{tk}}{N_t}log\frac{N_{tk}}{N_t} \right )+\alpha\left| T\right |=-\sum_{t=1}^{\left | T\right |}\sum_{k=1}^{K}N_{tk}log\frac{N_{tk}}{N_t}+\alpha\left| T\right |=C(T)+\alpha\left| T\right |,$$
其中,$C(T)$表示该决策树对于训练数据的预测误差,$\left | T\right |$表示模型的复杂度。因此,当选取较大的$\alpha$时,可以促使选择较简单的模型(树);当选取较小的$\alpha$时,可以促使选择较复杂的模型(树)。
该剪枝算法可描述如下,
输入:决策树生成算法生成的决策树$T$,参数$\alpha$
输出:剪枝之后的子树$T_{\alpha}$
- step 1:计算每个结点的经验熵;
- step 2:递归从树的叶结点向上回缩。设回缩之前的树为$T_A$,回缩之后的树为$T_B$,如果有$C_{\alpha}(T_B)\leq C_{\alpha}(T_A)$,则进行剪枝(即将当前结点的父结点变为新的叶结点);
- step 3:不断递归step 2,直到不能继续为止,得到使得损失函数$C_{\alpha}$最小的树$T_{\alpha}$,返回$T_{\alpha}$。
3.1.1 - CART的后剪枝
CART计算子树的损失函数为
$$C_{\alpha}=C(T)+\alpha \left | T \right |,$$
其中$C(T)$为对训练数据的预测误差(分类树是基尼指数,回归树是均方误差),其他参数与ID3和C4.5的损失函数的参数意义相同。
3.1.1.0 - 思路
这里有一个需要先说明的前提:对于固定的$\alpha$,一定存在使得损失函数$C_{\alpha}(T)$最小的子树,将其表示为$T_{\alpha}$,并且这样子的最优子树是唯一的。当$\alpha$大的时候,最优子树$T_{\alpha}$偏小(树比较简单);当$\alpha$小的时候,最优子树$T_{\alpha}$偏大(树比较复杂)。考虑极端情况,当$\alpha=0$时,整体树是最优的。当$\alpha\rightarrow\infty$时,根节点组成的单结点树是最优的。
因此,可以将$\alpha$从小增大,$0<\alpha_0<\alpha_1<\cdots<\alpha_n<+\infty $,产生一系列的区间$[\alpha_i,\alpha_{i+1}),i=0,1,\cdots,n$;对于每一个区间剪枝到一个最优子树,因此可以产生一个最优子树序列$\{T_0,T_1,\cdots,T_n\}$。
具体的,考虑位于结点$t$的一颗子树$T_t$,如果没有剪枝,损失函数为
$$C_{\alpha}(T_t)=C(T_t)+\alpha\left | T_t \right |,$$
如果将子树剪掉,只保留当前结点,则损失函数为
$$C_{\alpha}(t)=C(t)+\alpha,$$
当$\alpha=0$及$\alpha$充分小时,有不等式(因为不剪的话复杂的子树肯定比一个根节点更能描述训练数据,即损失值越小)
$$C_{\alpha}(T_t)<C_{\alpha}(t),$$
当$\alpha$增大时,存在一个$\alpha$,使得
$$C_{\alpha}(T_t)=C_{\alpha}(t),$$
当$\alpha$再增大时,不等式将改变方向,如下式子所示
$$C_{\alpha}(T_t)>C_{\alpha}(t),$$
因此只要当$\alpha=\frac{C(t)-C(T_t)}{\left | T_t \right | - 1}$时,$C_{\alpha}(T_t)=C_{\alpha}(t)$成立,而$t$比$T_t$具有更少的结点,更简单,因此对$T_t$进行剪枝。
3.1.1.1 - 算法
输入:CART算法生成的决策树$T$
输出:最优决策树$T_{\alpha}$
算法过程描述如下
- step 1:初始化$\alpha_{min}=\infty$,最优子树集合$\omega=\{T\}$
- step 2:从叶子结点开始自下而上计算结点$t$的训练损失函数$C_{\alpha}(T_t)$(分类树为基尼指数,回归树为均方误差),叶子结点数为$\left | T_t \right |$,正则化更新为$\alpha=min\{\frac{C(t)-C(T_t)}{\left | T_t \right | - 1},\alpha_{min}\}$,更新$\alpha_{min}=\alpha$
- step 3:得到所有结点的$\alpha$值集合$M$
- step 4:从$M$中选择最大的值$\alpha_k$,自上而下访问子树$t$的内部结点,如果$\frac{C(t)-C(T_t)}{\left | T_t \right | - 1}\leq \alpha_k$时,进行剪枝(注意到,剪枝之后需要更新当前结点的值,分类树为概率最高的类别,回归树为所有样本的均值)。这样子可得到$\alpha_k$对应的最优子树$T_k$
- step 5:最优子树集合$\omega=\omega\ \cup\ T_k$,$M=M-\{\alpha_k\}$
- step 6:如果$M$不为空,回到step 4。否则已经得到所有可能的可选最优子树集合$\omega$
- step 7:采用交叉验证在$\omega$选取最优子树$T_{\alpha}$
4 - 决策树的对比
对于上述描述的ID3、C4.5和CART决策树的总结对比如下:
| 决策树算法 | 特征类型 | 不纯度度量 | 子结点数量 | 目标类型 |
| ID3 | 离散型 | 信息增益 | $K\geq 2$ | 离散型 |
| C4.5 | 离散型、连续型 | 信息增益比 | $K\geq 2$ | 离散型 |
| CART | 离散型、连续型 | Gini指数 | $K=2$ | 离散型、连续型 |
上述讨论的决策树算法均在离散特征值的前提下,上表显示,C4.5和CART算法都可以对连续型特征值生效,这里只简单介绍一下对于连续特征值需要怎么处理。
对于连续特征的处理方法为:将连续属性进行排序(升序),再将其转换成离散属性(即对连续属性进行有限采样),例如在当前结点对于当前属性有$N$种离散化方法,取一个落于属性中的阈值$\theta$,对于这$N$种离散化方法,均规定将采样后的值若$\leq \theta$则分到左子树,否则分到右子树,再计算每一种离散化方法的信息增益(或者基尼指数或均方差),最后选取具有最大的信息增益(或者基尼指数或均方差)的离散化方法及$\theta$作为此节点的分割依据。
5 - 总结
- 决策树生成之后可以转换成IF-THEN规则的集合,可解释性较好
- 决策树模型不稳定,方差大,训练集的改变容易导致性能的波动(可以通过集成方法解决)
- 决策树采用贪婪算法的思想,每次分裂时只考虑当前情况下能带来最好的属性分裂,容易陷入局部最优
6 - 参考资料
《统计学习方法》,李航
https://blog.csdn.net/zhangbaoanhadoop/article/details/79904091
https://www.cnblogs.com/keye/p/10564914.html
【分类算法】决策树(Decision Tree)的更多相关文章
- 用于分类的决策树(Decision Tree)-ID3 C4.5
决策树(Decision Tree)是一种基本的分类与回归方法(ID3.C4.5和基于 Gini 的 CART 可用于分类,CART还可用于回归).决策树在分类过程中,表示的是基于特征对实例进行划分, ...
- (ZT)算法杂货铺——分类算法之决策树(Decision tree)
https://www.cnblogs.com/leoo2sk/archive/2010/09/19/decision-tree.html 3.1.摘要 在前面两篇文章中,分别介绍和讨论了朴素贝叶斯分 ...
- 机器学习算法实践:决策树 (Decision Tree)(转载)
前言 最近打算系统学习下机器学习的基础算法,避免眼高手低,决定把常用的机器学习基础算法都实现一遍以便加深印象.本文为这系列博客的第一篇,关于决策树(Decision Tree)的算法实现,文中我将对决 ...
- 数据挖掘 决策树 Decision tree
数据挖掘-决策树 Decision tree 目录 数据挖掘-决策树 Decision tree 1. 决策树概述 1.1 决策树介绍 1.1.1 决策树定义 1.1.2 本质 1.1.3 决策树的组 ...
- 【机器学习算法-python实现】决策树-Decision tree(1) 信息熵划分数据集
(转载请注明出处:http://blog.csdn.net/buptgshengod) 1.背景 决策书算法是一种逼近离散数值的分类算法,思路比較简单,并且准确率较高.国际权威的学术组织,数据挖掘国际 ...
- 决策树decision tree原理介绍_python sklearn建模_乳腺癌细胞分类器(推荐AAA)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- 机器学习方法(四):决策树Decision Tree原理与实现技巧
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术.应用感兴趣的同学加入. 前面三篇写了线性回归,lass ...
- 决策树Decision Tree 及实现
Decision Tree 及实现 标签: 决策树熵信息增益分类有监督 2014-03-17 12:12 15010人阅读 评论(41) 收藏 举报 分类: Data Mining(25) Pyt ...
- 决策树 Decision Tree
决策树是一个类似于流程图的树结构:其中,每个内部结点表示在一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或类分布.树的最顶层是根结点.  决策树的构建 想要构建一个决策树,那么咱们 ...
- 【转载】决策树Decision Tree学习
本文转自:http://www.cnblogs.com/v-July-v/archive/2012/05/17/2539023.html 最近在研究规则引擎,需要学习决策树.决策表等算法.发现篇好文对 ...
随机推荐
- Django :中间 件与csrf
一.中间件 什么是中间件 中间件有什么用 自定义中间件 中间件应用场景 二.csrf csrf token跨站请求伪造 一.中间件 1.什么是中间件 中间件顾名思义,是介于request与respon ...
- HDU_2717_Catch That Cow
很短的 BFS 队列 HDU_2717_Catch That Cow #include<iostream> #include<algorithm> #include<cs ...
- orm多表的创建和基于对象的查询
创建模型 实例:我们来假定下面这些概念,字段和关系 作者模型:一个作者有姓名和年龄. 作者详细模型:把作者的详情放到详情表,包含生日,手机号,家庭住址等信息.作者详情模型和作者模型之间是一对一的关系( ...
- MyBatis_[tp_50]_动态sql_bind绑定 与原生sql对比
笔记要点出错分析与总结 更推荐,原生的sql写法,bind方法不灵活! Test中: e.setLastName("%e%"); 直接在这里写上模糊查询的语句,更加省时 配置中: ...
- Winform工程反编译后的工作
Winform工程,反编译后,虽然能用,但不太好用. 因为form并没有像原生的那样. 所以,需要几个步聚: 1. 用ResGen工具,把二进制资源文件还原为xml格式: ResGen fromXX. ...
- P3197 [HNOI2008]越狱[组合数学]
题目来源:洛谷 题目描述 监狱有连续编号为 1…N 的 N 个房间,每个房间关押一个犯人,有 M 种宗教,每个犯人可能信仰其中一种.如果相邻房间的犯人的宗教相同,就可能发生越狱,求有多少种状态可能发生 ...
- OpenSSL和Python实现RSA Key公钥加密私钥解密
基于非对称算法的RSA Key主要有两个用途,数字签名和验证(私钥签名,公钥验证),以及非对称加解密(公钥加密,私钥解密).本文提供一个基于OpenSSL和Python进行非对称加解密的例子. 1. ...
- 002_软件安装之_keil4与keil5共存
目的:实现keil4和keil5的共存 1. Keil4 主要用来开发 C51 程序 2. Keil5 也就是 MDK 主要用来开发 ARM 芯片,如 STM32 系列芯片 3. 资料下载地址:链接: ...
- git致命错误汇总
1. 拒绝合并无关历史 fatal: refusing to merge unrelated histories 解决办法: git pull origin master --allow-unrel ...
- HTML 文字垂直剧中
HTML 有个使文字垂直剧中的代码 line-height: line-height:使用时 总高多少 后边就输入多少PX 剧中前展示 剧中后展示