linux系统编程--文件IO
系统调用
什么是系统调用:
由操作系统实现并提供给外部应用程序的编程接口。(Application Programming Interface,API)。是应用程序同系统之间数据交互的桥梁。
C标准函数和系统函数调用关系。一个helloworld如何打印到屏幕。

C标准库文件IO函数。
fopen、fclose、fseek、fgets、fputs、fread、fwrite......
r 只读、 r+读写
w只写并截断为0、 w+读写并截断为0
a追加只写、 a+追加读写
open/close函数
函数原型:头文件 <unistd.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
int close(int fd);
常用参数
O_RDONLY、O_WRONLY、O_RDWR
O_APPEND、O_CREAT、O_EXCL(判断文件是否存在)、 O_TRUNC(文件截断为0)、 O_NONBLOCK
使用头文件:<fcntl.h>
open常见错误:
1. 打开文件不存在
2. 以写方式打开只读文件(打开文件没有对应权限)
3. 以只写方式打开目录
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h> int main()
{
int fd = open("./test.txt",O_RDONLY);
printf("fd = %d\n",fd); close(fd); return ;
}
O_CREAT 才需要指定第三个参数,文件权限还需要依赖于掩码umask,mode & ~umask
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h> int main()
{
int fd = open("./text.txt",O_RDONLY | O_CREAT, ); // 权限八进制,
printf("fd = %d",fd); close(fd); return ;
}
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h>
#include <errno.h> int main()
{
int fd = open("./textt.txt",O_RDONLY);
printf("fd = %d",fd);
printf("error: %d",errno); close(fd); return ;
}
文件描述符:
PCB进程控制块
可使用命令locate sched.h查看位置: /usr/src/linux-headers-3.16.0-30/include/linux/sched.h
struct task_struct { 结构体
struct task_struct {
#ifdef CONFIG_THREAD_INFO_IN_TASK
/*
* For reasons of header soup (see current_thread_info()), this
* must be the first element of task_struct.
*/
struct thread_info thread_info;
#endif
/* -1 unrunnable, 0 runnable, >0 stopped: */
volatile long state;
/*
* This begins the randomizable portion of task_struct. Only
* scheduling-critical items should be added above here.
*/
randomized_struct_fields_start
void *stack;
atomic_t usage;
/* Per task flags (PF_*), defined further below: */
unsigned int flags;
unsigned int ptrace;
#ifdef CONFIG_SMP
struct llist_node wake_entry;
int on_cpu;
#ifdef CONFIG_THREAD_INFO_IN_TASK
/* Current CPU: */
unsigned int cpu;
#endif
unsigned int wakee_flips;
unsigned long wakee_flip_decay_ts;
struct task_struct *last_wakee;
int wake_cpu;
#endif
int on_rq;
int prio;
int static_prio;
int normal_prio;
unsigned int rt_priority;
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
#ifdef CONFIG_CGROUP_SCHED
struct task_group *sched_task_group;
#endif
struct sched_dl_entity dl;
#ifdef CONFIG_PREEMPT_NOTIFIERS
/* List of struct preempt_notifier: */
struct hlist_head preempt_notifiers;
#endif
#ifdef CONFIG_BLK_DEV_IO_TRACE
unsigned int btrace_seq;
#endif
unsigned int policy;
int nr_cpus_allowed;
cpumask_t cpus_allowed;
#ifdef CONFIG_PREEMPT_RCU
int rcu_read_lock_nesting;
union rcu_special rcu_read_unlock_special;
struct list_head rcu_node_entry;
struct rcu_node *rcu_blocked_node;
#endif /* #ifdef CONFIG_PREEMPT_RCU */
#ifdef CONFIG_TASKS_RCU
unsigned long rcu_tasks_nvcsw;
u8 rcu_tasks_holdout;
u8 rcu_tasks_idx;
int rcu_tasks_idle_cpu;
struct list_head rcu_tasks_holdout_list;
#endif /* #ifdef CONFIG_TASKS_RCU */
struct sched_info sched_info;
struct list_head tasks;
#ifdef CONFIG_SMP
struct plist_node pushable_tasks;
struct rb_node pushable_dl_tasks;
#endif
struct mm_struct *mm;
struct mm_struct *active_mm;
/* Per-thread vma caching: */
struct vmacache vmacache;
#ifdef SPLIT_RSS_COUNTING
struct task_rss_stat rss_stat;
#endif
int exit_state;
int exit_code;
int exit_signal;
/* The signal sent when the parent dies: */
int pdeath_signal;
/* JOBCTL_*, siglock protected: */
unsigned long jobctl;
/* Used for emulating ABI behavior of previous Linux versions: */
unsigned int personality;
/* Scheduler bits, serialized by scheduler locks: */
unsigned sched_reset_on_fork:;
unsigned sched_contributes_to_load:;
unsigned sched_migrated:;
unsigned sched_remote_wakeup:;
/* Force alignment to the next boundary: */
unsigned :;
/* Unserialized, strictly 'current' */
/* Bit to tell LSMs we're in execve(): */
unsigned in_execve:;
unsigned in_iowait:;
#ifndef TIF_RESTORE_SIGMASK
unsigned restore_sigmask:;
#endif
#ifdef CONFIG_MEMCG
unsigned memcg_may_oom:;
#ifndef CONFIG_SLOB
unsigned memcg_kmem_skip_account:;
#endif
#endif
#ifdef CONFIG_COMPAT_BRK
unsigned brk_randomized:;
#endif
#ifdef CONFIG_CGROUPS
/* disallow userland-initiated cgroup migration */
unsigned no_cgroup_migration:;
#endif
unsigned long atomic_flags; /* Flags requiring atomic access. */
struct restart_block restart_block;
pid_t pid;
pid_t tgid;
#ifdef CONFIG_CC_STACKPROTECTOR
/* Canary value for the -fstack-protector GCC feature: */
unsigned long stack_canary;
#endif
/*
* Pointers to the (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->real_parent->pid)
*/
/* Real parent process: */
struct task_struct __rcu *real_parent;
/* Recipient of SIGCHLD, wait4() reports: */
struct task_struct __rcu *parent;
/*
* Children/sibling form the list of natural children:
*/
struct list_head children;
struct list_head sibling;
struct task_struct *group_leader;
/*
* 'ptraced' is the list of tasks this task is using ptrace() on.
*
* This includes both natural children and PTRACE_ATTACH targets.
* 'ptrace_entry' is this task's link on the p->parent->ptraced list.
*/
struct list_head ptraced;
struct list_head ptrace_entry;
/* PID/PID hash table linkage. */
struct pid_link pids[PIDTYPE_MAX];
struct list_head thread_group;
struct list_head thread_node;
struct completion *vfork_done;
/* CLONE_CHILD_SETTID: */
int __user *set_child_tid;
/* CLONE_CHILD_CLEARTID: */
int __user *clear_child_tid;
u64 utime;
u64 stime;
#ifdef CONFIG_ARCH_HAS_SCALED_CPUTIME
u64 utimescaled;
u64 stimescaled;
#endif
u64 gtime;
struct prev_cputime prev_cputime;
#ifdef CONFIG_VIRT_CPU_ACCOUNTING_GEN
struct vtime vtime;
#endif
#ifdef CONFIG_NO_HZ_FULL
atomic_t tick_dep_mask;
#endif
/* Context switch counts: */
unsigned long nvcsw;
unsigned long nivcsw;
/* Monotonic time in nsecs: */
u64 start_time;
/* Boot based time in nsecs: */
u64 real_start_time;
/* MM fault and swap info: this can arguably be seen as either mm-specific or thread-specific: */
unsigned long min_flt;
unsigned long maj_flt;
#ifdef CONFIG_POSIX_TIMERS
struct task_cputime cputime_expires;
struct list_head cpu_timers[];
#endif
/* Process credentials: */
/* Tracer's credentials at attach: */
const struct cred __rcu *ptracer_cred;
/* Objective and real subjective task credentials (COW): */
const struct cred __rcu *real_cred;
/* Effective (overridable) subjective task credentials (COW): */
const struct cred __rcu *cred;
/*
* executable name, excluding path.
*
* - normally initialized setup_new_exec()
* - access it with [gs]et_task_comm()
* - lock it with task_lock()
*/
char comm[TASK_COMM_LEN];
struct nameidata *nameidata;
#ifdef CONFIG_SYSVIPC
struct sysv_sem sysvsem;
struct sysv_shm sysvshm;
#endif
#ifdef CONFIG_DETECT_HUNG_TASK
unsigned long last_switch_count;
#endif
/* Filesystem information: */
struct fs_struct *fs;
/* Open file information: */
struct files_struct *files;
/* Namespaces: */
struct nsproxy *nsproxy;
/* Signal handlers: */
struct signal_struct *signal;
struct sighand_struct *sighand;
sigset_t blocked;
sigset_t real_blocked;
/* Restored if set_restore_sigmask() was used: */
sigset_t saved_sigmask;
struct sigpending pending;
unsigned long sas_ss_sp;
size_t sas_ss_size;
unsigned int sas_ss_flags;
struct callback_head *task_works;
struct audit_context *audit_context;
#ifdef CONFIG_AUDITSYSCALL
kuid_t loginuid;
unsigned int sessionid;
#endif
struct seccomp seccomp;
/* Thread group tracking: */
u32 parent_exec_id;
u32 self_exec_id;
/* Protection against (de-)allocation: mm, files, fs, tty, keyrings, mems_allowed, mempolicy: */
spinlock_t alloc_lock;
/* Protection of the PI data structures: */
raw_spinlock_t pi_lock;
struct wake_q_node wake_q;
#ifdef CONFIG_RT_MUTEXES
/* PI waiters blocked on a rt_mutex held by this task: */
struct rb_root_cached pi_waiters;
/* Updated under owner's pi_lock and rq lock */
struct task_struct *pi_top_task;
/* Deadlock detection and priority inheritance handling: */
struct rt_mutex_waiter *pi_blocked_on;
#endif
#ifdef CONFIG_DEBUG_MUTEXES
/* Mutex deadlock detection: */
struct mutex_waiter *blocked_on;
#endif
#ifdef CONFIG_TRACE_IRQFLAGS
unsigned int irq_events;
unsigned long hardirq_enable_ip;
unsigned long hardirq_disable_ip;
unsigned int hardirq_enable_event;
unsigned int hardirq_disable_event;
int hardirqs_enabled;
int hardirq_context;
unsigned long softirq_disable_ip;
unsigned long softirq_enable_ip;
unsigned int softirq_disable_event;
unsigned int softirq_enable_event;
int softirqs_enabled;
int softirq_context;
#endif
#ifdef CONFIG_LOCKDEP
# define MAX_LOCK_DEPTH 48UL
u64 curr_chain_key;
int lockdep_depth;
unsigned int lockdep_recursion;
struct held_lock held_locks[MAX_LOCK_DEPTH];
#endif
#ifdef CONFIG_UBSAN
unsigned int in_ubsan;
#endif
/* Journalling filesystem info: */
void *journal_info;
/* Stacked block device info: */
struct bio_list *bio_list;
#ifdef CONFIG_BLOCK
/* Stack plugging: */
struct blk_plug *plug;
#endif
/* VM state: */
struct reclaim_state *reclaim_state;
struct backing_dev_info *backing_dev_info;
struct io_context *io_context;
/* Ptrace state: */
unsigned long ptrace_message;
siginfo_t *last_siginfo;
struct task_io_accounting ioac;
#ifdef CONFIG_TASK_XACCT
/* Accumulated RSS usage: */
u64 acct_rss_mem1;
/* Accumulated virtual memory usage: */
u64 acct_vm_mem1;
/* stime + utime since last update: */
u64 acct_timexpd;
#endif
#ifdef CONFIG_CPUSETS
/* Protected by ->alloc_lock: */
nodemask_t mems_allowed;
/* Seqence number to catch updates: */
seqcount_t mems_allowed_seq;
int cpuset_mem_spread_rotor;
int cpuset_slab_spread_rotor;
#endif
#ifdef CONFIG_CGROUPS
/* Control Group info protected by css_set_lock: */
struct css_set __rcu *cgroups;
/* cg_list protected by css_set_lock and tsk->alloc_lock: */
struct list_head cg_list;
#endif
#ifdef CONFIG_INTEL_RDT
u32 closid;
u32 rmid;
#endif
#ifdef CONFIG_FUTEX
struct robust_list_head __user *robust_list;
#ifdef CONFIG_COMPAT
struct compat_robust_list_head __user *compat_robust_list;
#endif
struct list_head pi_state_list;
struct futex_pi_state *pi_state_cache;
#endif
#ifdef CONFIG_PERF_EVENTS
struct perf_event_context *perf_event_ctxp[perf_nr_task_contexts];
struct mutex perf_event_mutex;
struct list_head perf_event_list;
#endif
#ifdef CONFIG_DEBUG_PREEMPT
unsigned long preempt_disable_ip;
#endif
#ifdef CONFIG_NUMA
/* Protected by alloc_lock: */
struct mempolicy *mempolicy;
short il_prev;
short pref_node_fork;
#endif
#ifdef CONFIG_NUMA_BALANCING
int numa_scan_seq;
unsigned int numa_scan_period;
unsigned int numa_scan_period_max;
int numa_preferred_nid;
unsigned long numa_migrate_retry;
/* Migration stamp: */
u64 node_stamp;
u64 last_task_numa_placement;
u64 last_sum_exec_runtime;
struct callback_head numa_work;
struct list_head numa_entry;
struct numa_group *numa_group;
/*
* numa_faults is an array split into four regions:
* faults_memory, faults_cpu, faults_memory_buffer, faults_cpu_buffer
* in this precise order.
*
* faults_memory: Exponential decaying average of faults on a per-node
* basis. Scheduling placement decisions are made based on these
* counts. The values remain static for the duration of a PTE scan.
* faults_cpu: Track the nodes the process was running on when a NUMA
* hinting fault was incurred.
* faults_memory_buffer and faults_cpu_buffer: Record faults per node
* during the current scan window. When the scan completes, the counts
* in faults_memory and faults_cpu decay and these values are copied.
*/
unsigned long *numa_faults;
unsigned long total_numa_faults;
/*
* numa_faults_locality tracks if faults recorded during the last
* scan window were remote/local or failed to migrate. The task scan
* period is adapted based on the locality of the faults with different
* weights depending on whether they were shared or private faults
*/
unsigned long numa_faults_locality[];
unsigned long numa_pages_migrated;
#endif /* CONFIG_NUMA_BALANCING */
struct tlbflush_unmap_batch tlb_ubc;
struct rcu_head rcu;
/* Cache last used pipe for splice(): */
struct pipe_inode_info *splice_pipe;
struct page_frag task_frag;
#ifdef CONFIG_TASK_DELAY_ACCT
struct task_delay_info *delays;
#endif
#ifdef CONFIG_FAULT_INJECTION
int make_it_fail;
unsigned int fail_nth;
#endif
/*
* When (nr_dirtied >= nr_dirtied_pause), it's time to call
* balance_dirty_pages() for a dirty throttling pause:
*/
int nr_dirtied;
int nr_dirtied_pause;
/* Start of a write-and-pause period: */
unsigned long dirty_paused_when;
#ifdef CONFIG_LATENCYTOP
int latency_record_count;
struct latency_record latency_record[LT_SAVECOUNT];
#endif
/*
* Time slack values; these are used to round up poll() and
* select() etc timeout values. These are in nanoseconds.
*/
u64 timer_slack_ns;
u64 default_timer_slack_ns;
#ifdef CONFIG_KASAN
unsigned int kasan_depth;
#endif
#ifdef CONFIG_FUNCTION_GRAPH_TRACER
/* Index of current stored address in ret_stack: */
int curr_ret_stack;
/* Stack of return addresses for return function tracing: */
struct ftrace_ret_stack *ret_stack;
/* Timestamp for last schedule: */
unsigned long long ftrace_timestamp;
/*
* Number of functions that haven't been traced
* because of depth overrun:
*/
atomic_t trace_overrun;
/* Pause tracing: */
atomic_t tracing_graph_pause;
#endif
#ifdef CONFIG_TRACING
/* State flags for use by tracers: */
unsigned long trace;
/* Bitmask and counter of trace recursion: */
unsigned long trace_recursion;
#endif /* CONFIG_TRACING */
#ifdef CONFIG_KCOV
/* Coverage collection mode enabled for this task (0 if disabled): */
enum kcov_mode kcov_mode;
/* Size of the kcov_area: */
unsigned int kcov_size;
/* Buffer for coverage collection: */
void *kcov_area;
/* KCOV descriptor wired with this task or NULL: */
struct kcov *kcov;
#endif
#ifdef CONFIG_MEMCG
struct mem_cgroup *memcg_in_oom;
gfp_t memcg_oom_gfp_mask;
int memcg_oom_order;
/* Number of pages to reclaim on returning to userland: */
unsigned int memcg_nr_pages_over_high;
#endif
#ifdef CONFIG_UPROBES
struct uprobe_task *utask;
#endif
#if defined(CONFIG_BCACHE) || defined(CONFIG_BCACHE_MODULE)
unsigned int sequential_io;
unsigned int sequential_io_avg;
#endif
#ifdef CONFIG_DEBUG_ATOMIC_SLEEP
unsigned long task_state_change;
#endif
int pagefault_disabled;
#ifdef CONFIG_MMU
struct task_struct *oom_reaper_list;
#endif
#ifdef CONFIG_VMAP_STACK
struct vm_struct *stack_vm_area;
#endif
#ifdef CONFIG_THREAD_INFO_IN_TASK
/* A live task holds one reference: */
atomic_t stack_refcount;
#endif
#ifdef CONFIG_LIVEPATCH
int patch_state;
#endif
#ifdef CONFIG_SECURITY
/* Used by LSM modules for access restriction: */
void *security;
#endif
/*
* New fields for task_struct should be added above here, so that
* they are included in the randomized portion of task_struct.
*/
randomized_struct_fields_end
/* CPU-specific state of this task: */
struct thread_struct thread;
/*
* WARNING: on x86, 'thread_struct' contains a variable-sized
* structure. It *MUST* be at the end of 'task_struct'.
*
* Do not put anything below here!
*/
};
struct task_struct
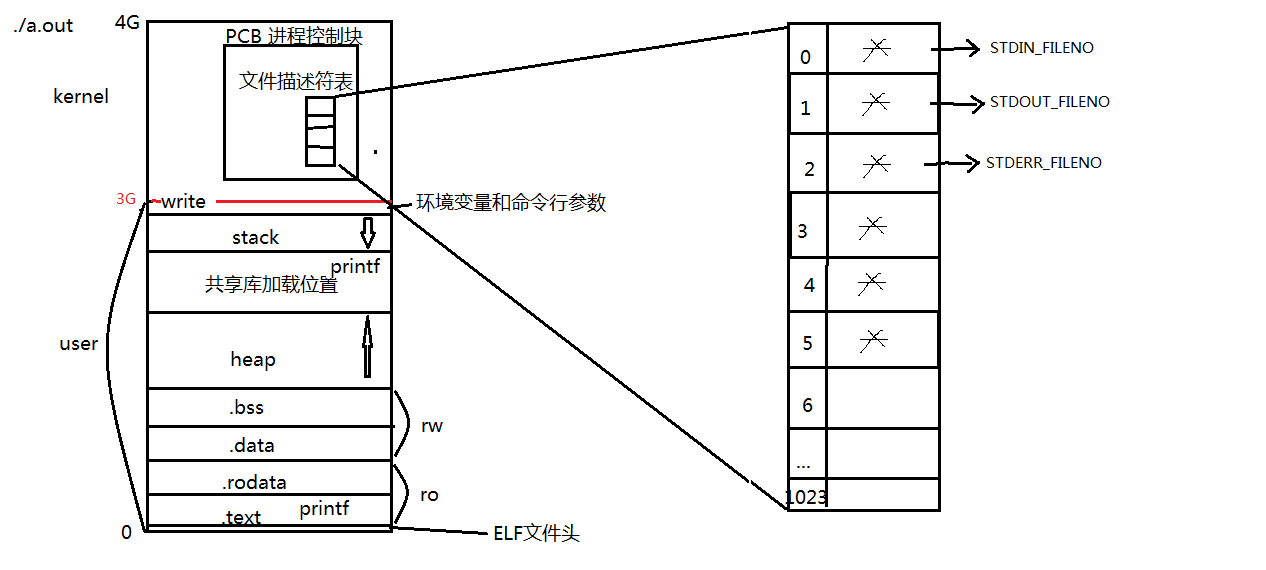
每当执行一个程序,运行./a.out,它就会产生这样一个0-4G的虚拟内存地址空间
文件描述符表
结构体PCB 的成员变量file_struct *file 指向文件描述符表。
从应用程序使用角度,该指针可理解记忆成一个字符指针数组,下标0/1/2/3/4...找到文件结构体。
本质是一个键值对0、1、2...都分别对应具体地址。但键值对使用的特性是自动映射,我们只操作键不直接使用值。
新打开文件返回文件描述符表中未使用的最小文件描述符。
STDIN_FILENO 0
STDOUT_FILENO 1
STDERR_FILENO 2
FILE结构体
主要包含文件描述符、文件读写位置、IO缓冲区三部分内容。
struct file {
...
文件的偏移量;
文件的访问权限;
文件的打开标志;
文件内核缓冲区的首地址;
struct operations * f_op;
...
};
查看方法:
(1) /usr/src/linux-headers-3.16.0-30/include/linux/fs.h
(2) lxr:LXR( Linux超文本交叉代码检索工具)
Linux超文本交叉代码检索工具LXR(Linux Cross Reference),是由挪威奥斯陆大学数学系Arne Georg Gleditsch和Per Kristian Gjermshus编写的。这个工具实际上运行在Linux或者UNIX平台下,通过对源代码中的所有符号建立索引,从而可以方便的检索任何一个符号,包括函数、外部变量、文件名、宏定义等等。不仅仅是针对Linux源代码,对于C语言的其他大型的项目,都可以建立其lxr站点,以提供开发者查询代码,以及后继开发者学习代码。
目前的lxr是专门为Linux下面的Apache服务器设计的,通过运行perl脚本,检索在安装时根据需要建立的源代码索引文件,将数据发送到网络客户端的Web浏览器上。任何一种平台上的Web浏览器都可以访问,这就方便了习惯在Windows平台下工作的用户。
关于lxr的英文网站为http://lxr.linux.no/,在中国Linux论坛http://www.linuxforum.net上有其镜象。 如何建立自己的LXR网站?
直接通过http://lxr.linux.no/lxr-0.3.tar.gz,下载lxr的tarball形式的安装包。
另外,因为lxr使用glimpse作为整个项目中文本的搜索工具,因此还需要下载glimpse,
网址在http://glimpse.cs.arizona.edu
,下载glimpse-4.12..bin.Linux-2.2.--i686.tar.gz,
也可以使用更新的版本。 下载以后按照说明进行安装和配置,就可以建立自己的LXR网站。
如果你上网很方便,就可以直接从http://lxr.linux.no/网站查询你需要的各种源码信息。 目前,可用的lxr网址有:
linux源码浏览:http://lxr.free-electrons.com/
LXR介绍
百度 lxr → lxr.oss.org.cn → 选择内核版本(如3.10) → 点击File Search进行搜索
→ 关键字:“include/linux/fs.h” → Ctrl+F 查找 “struct file {”
→ 得到文件内核中结构体定义
→ “struct file_operations”文件内容操作函数指针
→ “struct inode_operations”文件属性操作函数指针
最大打开文件数
一个进程默认打开文件的个数1024。
命令查看ulimit -a 查看open files 对应值。默认为1024
gec@ubuntu:~/myshare/文件IO$ ulimit -a
core file size (blocks, -c)
data seg size (kbytes, -d) unlimited
scheduling priority (-e)
file size (blocks, -f) unlimited
pending signals (-i)
max locked memory (kbytes, -l)
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size ( bytes, -p)
POSIX message queues (bytes, -q)
real-time priority (-r)
stack size (kbytes, -s)
cpu time (seconds, -t) unlimited
max user processes (-u)
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
可以使用ulimit -n 4096 修改
当然也可以通过修改系统配置文件永久修改该值,但是不建议这样操作。
cat /proc/sys/fs/file-max可以查看该电脑最大可以打开的文件个数。受内存大小影响。
gec@ubuntu:~/myshare/文件IO$ cat /proc/sys/fs/file-max
read/write函数
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);
read与write函数原型类似。使用时需注意:read/write函数的第三个参数。
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h>
#include <errno.h> int main()
{
char buf[] = {};
int ret = ;
int fd = open("./open.c",O_RDONLY); printf("fd = %d",fd);
printf("error: %d",errno); while((ret= read(fd,buf,sizeof(buf))) != ) {
write(STDOUT_FILENO,buf,ret); } close(fd); return ;
}
练习:编写程序实现简单的cp功能。
/*
*./mycp src dst 命令行参数实现简单的cp命令
*/
#include <unistd.h>
#include <stdlib.h>
#include <fcntl.h>
#include <stdio.h> char buf[]; int main(int argc, char *argv[])
{
int src, dst;
int n; src = open(argv[], O_RDONLY); //只读打开源文件
if(src < ){
perror("open src error");
exit();
}
//只写方式打开,覆盖原文件内容,不存在则创建,rw-r--r--
dst = open(argv[], O_WRONLY|O_TRUNC|O_CREAT, );
if(src < ){
perror("open dst error");
exit();
}
while((n = read(src, buf, ))){
if(n < ){
perror("read src error");
exit();
}
write(dst, buf, n); //不应写出1024, 读多少写多少
} close(src);
close(dst); return ;
}
程序比较:如果一个只读一个字节实现文件拷贝,使用read、write效率高,还是使用对应的标库函数效率高呢?
用系统函数read和write 一次一个字节的读写操作,和标准库函数 fgetc, fputc 一次一个字节读写
从理论上来看,好像 fgetc, fputc 的执行效率要比 read,write 慢,因为标库函数 底层还是调用系统函数
#include <string.h>
#include <unistd.h>
#include <fcntl.h>
#include <stdlib.h>
#include <errno.h> #define N 1 int main(int argc, char *argv[])
{
int fd, fd_out;
int n;
char buf[N]; fd = open("dict.txt", O_RDONLY);
if(fd < ){
perror("open dict.txt error");
exit();
} fd_out = open("dict.cp", O_WRONLY|O_CREAT|O_TRUNC, );
if(fd < ){
perror("open dict.cp error");
exit();
} while((n = read(fd, buf, N))){
if(n < ){
perror("read error");
exit();
}
write(fd_out, buf, n);
} close(fd);
close(fd_out); return ;
}
系统调用read,write
#include <stdio.h>
#include <stdlib.h> int main(void)
{
FILE *fp, *fp_out;
int n; fp = fopen("dict.txt", "r");
if(fp == NULL){
perror("fopen error");
exit();
} fp_out = fopen("dict.cp", "w");
if(fp == NULL){
perror("fopen error");
exit();
} while((n = fgetc(fp)) != EOF){
fputc(n, fp_out);
} fclose(fp);
fclose(fp_out); return ;
}
标库调用fgetc,fputc
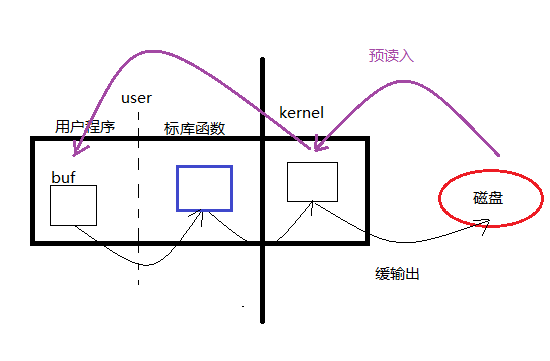
但是实际运行 标库函数运行的效率明显高于系统调用,这是因为系统的一个预读入和缓输出的机制
标库函数用户区有一个默认 4096 字节的缓冲区,不会每一次调用都去触发底层的系统调用,而系统调用函数用户区没有缓冲区机制,它的缓冲区大小有我们在程序中指定,
所以一个字节一个字节的读写操作的时候,标库函数要比系统调用节省很多次数据从用户区到内核区的的拷贝,而这一块是很耗费时间的。
strace命令
shell中使用strace命令跟踪程序执行,查看调用的系统函数。
缓冲区
read、write函数常常被称为Unbuffered I/O。指的是无用户及缓冲区。但不保证不使用内核缓冲区。
预读入缓输出
错误处理函数:
错误号:errno
perror函数: void perror(const char *s); strerror函数: char *strerror(int errnum);
还有一个函数 strerror() 了解一下
查看错误号:
/usr/include/asm-generic/errno-base.h /usr/include/asm-generic/errno.h
#include <unistd.h> //read write
#include <fcntl.h> //open close O_WRONLY O_RDONLY O_CREAT O_RDWR
#include <stdlib.h> //exit
#include <errno.h>
#include <stdio.h> //perror
#include <string.h> int main(void)
{
int fd;
#if 1
//打开文件不存在
fd = open("test", O_RDONLY | O_CREAT);
if(fd < ){
printf("errno = %d\n", errno);
// perror("open test error");
printf("open test error: %s\n" , strerror(errno)); //printf("open test error\n");
exit();
}
#elif 0
//打开的文件没有对应权限(以只写方式打开一个只有读权限的文件)
fd = open("test", O_WRONLY); //O_RDWR也是错误的
if(fd < ){
printf("errno = %d\n", errno);
perror("open test error");
//printf("open test error\n");
exit();
} #endif
#if 0
//以写方式打开一个目录
fd = open("testdir", O_RDWR); //O_WRONLY也是错的
if(fd < ){
perror("open testdir error");
exit();
}
#endif return ;
}
阻塞、非阻塞
读常规文件是不会阻塞的,不管读多少字节,read一定会在有限的时间内返回。从终端设备或网络读则不一定,如果从终端输入的数据没有换行符,调用read读终端设备就会阻塞,如果网络上没有接收到数据包,调用read从网络读就会阻塞,至于会阻塞多长时间也是不确定的,如果一直没有数据到达就一直阻塞在那里。同样,写常规文件是不会阻塞的,而向终端设备或网络写则不一定。
现在明确一下阻塞(Block)这个概念。当进程调用一个阻塞的系统函数时,该进程被置于睡眠(Sleep)状态,这时内核调度其它进程运行,直到该进程等待的事件发生了(比如网络上接收到数据包,或者调用sleep指定的睡眠时间到了)它才有可能继续运行。与睡眠状态相对的是运行(Running)状态,在Linux内核中,处于运行状态的进程分为两种情况:
正在被调度执行。CPU处于该进程的上下文环境中,程序计数器(eip)里保存着该进程的指令地址,通用寄存器里保存着该进程运算过程的中间结果,正在执行该进程的指令,正在读写该进程的地址空间。
就绪状态。该进程不需要等待什么事件发生,随时都可以执行,但CPU暂时还在执行另一个进程,所以该进程在一个就绪队列中等待被内核调度。系统中可能同时有多个就绪的进程,那么该调度谁执行呢?内核的调度算法是基于优先级和时间片的,而且会根据每个进程的运行情况动态调整它的优先级和时间片,让每个进程都能比较公平地得到机会执行,同时要兼顾用户体验,不能让和用户交互的进程响应太慢。
阻塞读终端:【block_readtty.c】
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h> //hello worl d \n int main(void)
{
char buf[];
int n; n = read(STDIN_FILENO, buf, ); // #define STDIN_FILENO 0 STDOUT_FILENO 1 STDERR_FILENO 2
if(n < ){
perror("read STDIN_FILENO");
//printf("%d", errno);
exit();
}
write(STDOUT_FILENO, buf, n); return ;
}
非阻塞读终端 【nonblock_readtty.c】
#include <unistd.h>
#include <fcntl.h>
#include <errno.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h> #define MSG_TRY "try again\n" int main(void)
{
char buf[];
int fd, n; fd = open("/dev/tty", O_RDONLY|O_NONBLOCK); //使用O_NONBLOCK标志设置非阻塞读终端
if(fd < ){
perror("open /dev/tty");
exit();
}
tryagain: n = read(fd, buf, ); //-1 (1) 出错 errno==EAGAIN或者EWOULDBLOCK if(n < ){
//由于open时指定了O_NONBLOCK标志,read读设备,没有数据到达返回-1,同时将errno设置为EAGAIN或EWOULDBLOCK
if(errno != EAGAIN){ //也可以是 if(error != EWOULDBLOCK)两个宏值相同
perror("read /dev/tty");
exit();
}
sleep();
write(STDOUT_FILENO, MSG_TRY, strlen(MSG_TRY));
goto tryagain;
}
write(STDOUT_FILENO, buf, n);
close(fd); return ;
}
非阻塞读终端和等待超时【nonblock_timeout.c】
#include <unistd.h>
#include <fcntl.h>
#include <stdlib.h>
#include <stdio.h>
#include <errno.h>
#include <string.h> #define MSG_TRY "try again\n"
#define MSG_TIMEOUT "time out\n" int main(void)
{
char buf[];
int fd, n, i; fd = open("/dev/tty", O_RDONLY|O_NONBLOCK); // 重新打开 终端设备,默认是阻塞的,指定非阻塞打开方式
if(fd < ){
perror("open /dev/tty");
exit();
}
printf("open /dev/tty ok... %d\n", fd); for (i = ; i < ; i++){
n = read(fd, buf, );
if(n > ){ //说明读到了东西
break;
}
if(errno != EAGAIN){ //EWOULDBLK
perror("read /dev/tty");
exit();
}
sleep();
write(STDOUT_FILENO, MSG_TRY, strlen(MSG_TRY));
} if(i == ){
write(STDOUT_FILENO, MSG_TIMEOUT, strlen(MSG_TIMEOUT));
}else{
write(STDOUT_FILENO, buf, n);
} close(fd); return ;
}
注意,阻塞与非阻塞是对于文件而言的。而不是read、write等的属性。read终端,默认阻塞读。
总结read 函数返回值:
1. 返回非零值: 实际read到的字节数
2. 返回-1:
1):errno != EAGAIN (或!= EWOULDBLOCK) read出错
2):errno == EAGAIN (或== EWOULDBLOCK) 设置了非阻塞读,并且没有数据到达。
3. 返回0:读到文件末尾
lseek函数
文件偏移
Linux中可使用系统函数lseek来修改文件偏移量(读写位置)
每个打开的文件都记录着当前读写位置,打开文件时读写位置是0,表示文件开头,通常读写多少个字节就会将读写位置往后移多少个字节。
但是有一个例外,如果以O_APPEND方式打开,每次写操作都会在文件末尾追加数据,然后将读写位置移到新的文件末尾。
lseek和标准I/O库的fseek函数类似,可以移动当前读写位置(或者叫偏移量)。
fseek的作用及常用参数。 SEEK_SET(头)、SEEK_CUR(当前位置)、SEEK_END(文件尾)
int fseek(FILE *stream, long offset, int whence); 成功返回0;失败返回-1
特别的:超出文件末尾位置返回0(返回0标志着成功,不会出错);往回超出文件头位置,返回-1(失败)
off_t lseek(int fd, off_t offset, int whence); 失败返回-1;成功:返回的值是较文件起始位置向后的偏移量。
特别的:lseek允许超过文件结尾设置偏移量,文件会因此被拓展(必须要有IO操作之后,拓展才会生效)。
lseek(fd, , SEEK_SET);
write(fd, "s", ); // 必须要有IO操作
注意文件“读”和“写”使用同一偏移位置。【lseek.c】
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <fcntl.h> int main(void)
{
int fd, n;
char msg[] = "It's a test for lseek\n";
char ch; fd = open("lseek.txt", O_RDWR|O_CREAT, );
if(fd < ){
perror("open lseek.txt error");
exit();
} write(fd, msg, strlen(msg)); //使用fd对打开的文件进行写操作,问价读写位置位于文件结尾处。 lseek(fd, , SEEK_SET); //修改文件读写指针位置,位于文件开头。 注释该行会,将读不到数据 while((n = read(fd, &ch, ))){
if(n < ){
perror("read error");
exit();
}
write(STDOUT_FILENO, &ch, n); //将文件内容按字节读出,写出到屏幕
} close(fd); return ;
}
lseek常用应用:
1. 使用lseek拓展文件:write操作才能实质性的拓展文件。单lseek是不能进行拓展的。
一般:write(fd, "a", 1);
od -tcx filename 查看文件的16进制表示形式
od -tcd filename 查看文件的10进制表示形式
2. 通过lseek获取文件的大小:lseek(fd, 0, SEEK_END); 【lseek_test.c】
【最后注意】:lseek函数返回的偏移量总是相对于文件头而言。
fcntl函数
改变一个【已经打开】的文件的 访问控制属性。
重点掌握两个参数的使用,F_GETFL 和 F_SETFL。【fcntl.c】
#include <unistd.h>
#include <fcntl.h>
#include <errno.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h> #define MSG_TRY "try again\n" int main(void)
{
char buf[];
int flags, n; flags = fcntl(STDIN_FILENO, F_GETFL); //获取stdin属性信息
if(flags == -){
perror("fcntl error");
exit();
}
flags |= O_NONBLOCK;
int ret = fcntl(STDIN_FILENO, F_SETFL, flags);
if(ret == -){
perror("fcntl error");
exit();
} tryagain:
n = read(STDIN_FILENO, buf, );
if(n < ){
if(errno != EAGAIN){
perror("read /dev/tty");
exit();
}
sleep();
write(STDOUT_FILENO, MSG_TRY, strlen(MSG_TRY));
goto tryagain;
}
write(STDOUT_FILENO, buf, n); return ;
}
ioctl函数
对设备的I/O通道进行管理,控制设备特性。(主要应用于设备驱动程序中)。
通常用来获取文件的【物理特性】(该特性,不同文件类型所含有的值各不相同) 【ioctl.c】
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/ioctl.h> int main(void)
{
struct winsize size; if (isatty(STDOUT_FILENO) == ) //
exit(); if(ioctl(STDOUT_FILENO, TIOCGWINSZ, &size)<) {
perror("ioctl TIOCGWINSZ error");
exit();
}
printf("%d rows, %d columns\n", size.ws_row, size.ws_col); return ;
}
传入传出参数
传入参数:
const 关键字修饰的 指针变量 在函数内部读操作。 char *strcpy(cnost char *src, char *dst);
传出参数:
1. 指针做为函数参数
2. 函数调用前,指针指向的空间可以无意义,调用后指针指向的空间有意义,且作为函数的返回值传出
3. 在函数内部写操作。
传入传出参数:
1. 调用前指向的空间有实际意义 2. 调用期间在函数内读、写(改变原值)操作 3.作为函数返回值传出。
扩展阅读:
关于虚拟4G内存的描述和解析:
一个进程用到的虚拟地址是由内存区域表来管理的,实际用不了4G。而用到的内存区域,会通过页表映射到物理内存。
所以每个进程都可以使用同样的虚拟内存地址而不冲突,因为它们的物理地址实际上是不同的。内核用的是3G以上的1G虚拟内存地址,
其中896M是直接映射到物理地址的,128M按需映射896M以上的所谓高位内存。各进程使用的是同一个内核。
首先要分清“可以寻址”和“实际使用”的区别。
其实我们讲的每个进程都有4G虚拟地址空间,讲的都是“可以寻址”4G,意思是虚拟地址的0-3G对于一个进程的用户态和内核态来说是可以访问的,而3-4G是只有进程的内核态可以访问的。并不是说这个进程会用满这些空间。
其次,所谓“独立拥有的虚拟地址”是指对于每一个进程,都可以访问自己的0-4G的虚拟地址。虚拟地址是“虚拟”的,需要转化为“真实”的物理地址。
好比你有你的地址簿,我有我的地址簿。你和我的地址簿都有1、2、3、4页,但是每页里面的实际内容是不一样的,我的地址簿第1页写着3你的地址簿第1页写着4,对于你、我自己来说都是用第1页(虚拟),实际上用的分别是第3、4页(物理),不冲突。
内核用的896M虚拟地址是直接映射的,意思是只要把虚拟地址减去一个偏移量(3G)就等于物理地址。同样,这里指的还是寻址,实际使用前还是要分配内存。而且896M只是个最大值。如果物理内存小,内核能使用(分配)的可用内存也小。
linux系统编程--文件IO的更多相关文章
- Linux系统编程--文件IO操作
Linux思想即,Linux系统下一切皆文件. 一.对文件操作的几个函数 1.打开文件open函数 int open(const char *path, int oflags); int open(c ...
- Linux系统编程@终端IO
Linux系统中终端设备种类 终端是一种字符型设备,有多种类型,通常使用tty 来简称各种类型的终端设备.终端特殊设备文件一般有以下几种: 串行端口终端(/dev/ttySn ) ,伪终端(/dev ...
- Linux系统编程@文件操作(一)
只总结了部分常用的内容,详细内容参考<UNIX环境高级编程>及相关书籍. Linux中文件编程可以使用两种方法 Linux系统调用(依赖于系统) C语言库函数(不依赖于系统) Linux系 ...
- 系统编程--文件IO
1.文件描述符 文件描述符是一个非负整数,当打开一个现有文件或创建一个新文件时候,内核向进程返回一个文件描述符,新打开文件返回文件描述符表中未使用的最小文件描述符.Unix系统shell使用文件描述符 ...
- linux系统编程:IO读写过程的原子性操作实验
所谓原子性操作指的是:内核保证某系统调用中的所有步骤(操作)作为独立操作而一次性加以执行,其间不会被其他进程或线程所中断. 举个通俗点的例子:你和女朋友OOXX的时候,突然来了个电话,势必会打断你们高 ...
- Linux系统编程--文件描述符的复制dup()和dup2()【转】
本文转载自:http://blog.csdn.net/tennysonsky/article/details/45870459 dup() 和 dup2() 是两个非常有用的系统调用,都是用来复制一个 ...
- Linux系统编程---文件I/O(open、read、write、lseek、close)
文件描述符 定义:对内核而言,文件描述符相当于一个文件的标识,它是一个非负整数,当打开(open)一个现有文件或者创建(creat)一个新文件时,内核会向进程返回一个文件描述符 在unix中(文件描述 ...
- linux系统编程之文件与io(一)
经过了漫长的学习,C语言相关的的基础知识算是告一段落了,这也是尝试用写博客的形式来学习c语言,回过头来看,虽说可能写的内容有些比较简单,但是个人感觉是有史起来学习最踏实的一次,因为里面的每个实验都是自 ...
- linux系统编程之文件与io(五)
上一节中已经学习了文件描述符的复制,复制方法有三种,其中最后一种fcntl还并未使用到,关于这个函数,不光只有复制文件描述符的功能,还有其它一些用法,本节就对其进行一一剖析: fcntl常用操作: 这 ...
随机推荐
- (九)springMvc 的 post 提交乱码
#post 提交乱码 在 web.xml 配置下 过滤器 : <!--解决 post 乱码问题,--> <filter> <filter-name>characte ...
- # Ubuntu子系统安装配置
目录 Ubuntu子系统安装配置 安装配置 终端美化 卸载 和win10之间的交互 Ubuntu子系统安装配置 亲测启动速度毫秒之间 安装配置 系统升级到一周年正式版及以上(1607) 依次在 设置 ...
- kafka安装、相关命令以及PHP使用
1.安装JAVA #下载安装包 https://www.oracle.com/technetwork/java/javase/downloads/index.html tar -xzvf jdk-8u ...
- 20190805-Python基础 第二章 列表和元组(2)列表
1. list函数,用于将字符串转换为列表 2. 基本的列表操作 修改列表 - 给元素赋值,使用索引表示法给特定的元素赋值,如x[1] = 2 删除元素 - 使用del语句即可 name1 = ['a ...
- Vasya's Function CodeForces - 837E (gcd)
大意: 给定$a,b$, $1\le a,b\le 1e12$, 定义 $f(a,0)=0$ $f(a,b)=1+f(a,b-gcd(a,b))$ 求$f(a,b)$. 观察可以发现, 每次$b$一定 ...
- react 管理平台
https://open.vbill.cn/react-admin/ 开源中国:https://gitee.com/sxfad/react-admin.git GitHub:https://githu ...
- 关键字:for_each
std::for_each 先贴cppreference中对for_each的概述: template< class InputIt, class UnaryFunction > //此处 ...
- [转载]torch参数:torch.backends.cudnn.benchmark的意义
[转载]torch参数:torch.backends.cudnn.benchmark的意义 来源:https://zhuanlan.zhihu.com/p/73711222 完整版请看原文,这里只截取 ...
- connect() failed (111: Connection refused) while connecting to upstream的解决
遇到这种情况, 首先 1.检查php-fpm是否启动---------如果没启动->启动, 2.用命令 netstat -ant | grep 9000 查看php-fpm进程,如果没启动-&g ...
- CSS设置浮动导致背景颜色设置无效的解决方法
float浮动会使父元素高度塌陷,父级元素不能被撑开,所以导致背景颜色不能被撑开 解决方法: 对父元素设置高度 对父元素设置 overflow:hidden清除浮动 把父元素也设置为float浮动 结 ...